笔记(总结)-利用GMM和EM算法解决聚类问题
对Gaussian Mixture Model和Expectation Maximization算法一直以来了解不多,一来直接使用这两个方法的场景少,二来初看这两个算法确实有些一头雾水,不太理解为什么要这么做。上学期的课又涉及到了这部分,还是咬牙把这块给啃了下来,结合“周志华西瓜书”,在聚类场景下对这两部分做下总结。
高斯混合(Mixture of Gaussian)
$n$维随机变量$x$服从多元高斯分布,则概率密度函数为:其中 μ \mu μ为均值向量, Σ \Sigma Σ为协方差矩阵,给定这两个参数,则可以确定高斯分布,记为 p ( x ∣ μ , Σ ) p(x|\mu,\Sigma) p(x∣μ,Σ)。当维度退化为一维、二维空间时,高斯分布图像如下:
在此基础上,我们可以定义高斯混合分布如下:
该分布由 k k k个高斯分布混合而成, α i \alpha_i αi为混合系数,表示每个高斯分布的占比, ∑ i α i = 1 \sum_i \alpha_i=1 ∑iαi=1。
为什么要使用高斯混合模型做聚类?考虑如下两个图:
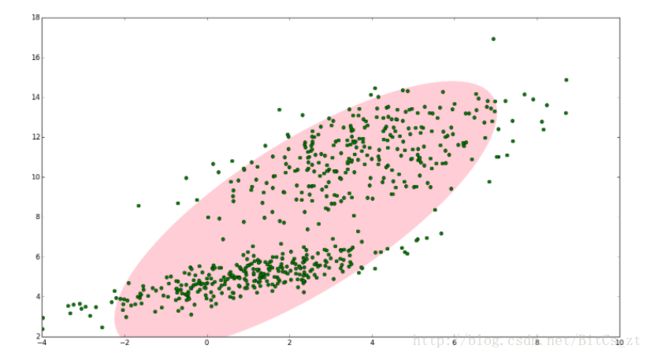

对于上述点集可以清楚看到,用一个高斯分布来拟合(图一)和用两个单独的高斯分布(图二)来拟合的效果差距是很大的。如果我们想用一个模型来达到图二的效果,最好的办法是将两个高斯分布进行线性组合。可以想见,当点集十分复杂时,增大参与线性混合的高斯分布数量越多,拟合能力就越强大,即
高斯分布在混合分量足够多的情况能逼近任意分布(可比对神经网络模型,在神经元、层数够多时能拟合任何函数)
那为什么要使用高斯分布呢?因为高斯分布是现实生活中最常见的分布,而且数学性质良好(密度函数处处可导)。实际上,把混合成分换成其他分布也是可以的,比如伯努利分布,卡方分布等,这才是高斯混合分布的精髓思想,即:
高斯混合分布,重要的不是“高斯”,而是“混合”。思想本质是用多个简单分布的组合去拟合更复杂的分布。
GMM用于聚类
假设现在样本是由未知的高斯混合模型生成,我们现在要根据所有样本来确定GMM的参数($\alpha_i,\mu_i,\Sigma_i,i=1,2,...,k$),从而确定每个样本是由哪个高斯分布产生。自然的,每个高斯分布对应聚类中的一类。定义高斯混合分布如下:给定样本集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m \} D={x1,x2,...,xm},采用极大似然对参数进行估计,即最大化似然函数:
由于对数中含有求和式,难以直接求导。故常用EM算法进行求解。
EM算法
假设我们不考虑样本应来自于哪个高斯分布。此时我们使用极大似然法可以直接求解:而当我们需要考虑上述问题时,来自哪个高斯分布相当于“隐变量”。当我们确定了各个高斯分布的参数后,才能求解隐变量,不能直接对上式求导了。
我们采用EM算法进行求解。EM算法是一个迭代算法,概括起来其实就两步:
- E step:固定参数,求解隐变量
- M step:固定隐变量,求参数
反复迭代直到收敛。下面具体应用到我们的问题中。
EM算法解GMM
E step
现有样本集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m \} D={x1,x2,...,xm}。令随机变量 z j ∈ { 1 , 2 , . . . , k } z_j \in\{1,2,...,k\} zj∈{1,2,...,k}表示样本 x j x_j xj属于的高斯分布,即为之前提到的隐变量。由于假设了样本是由GMM生成,先验概率下 P ( z j = i ) = α i ( i = 1 , 2 , . . . , k ) P(z_j=i)=\alpha_i(i=1,2,...,k) P(zj=i)=αi(i=1,2,...,k),由贝叶斯, x j x_j xj来自第 i i i个高斯分布的后验概率为:
可以看到,利用模型参数求解出了隐变量。
M step
对于$\alpha_i$的选择要满足:利用拉格朗日进行求解:
令:
将所得结果化简,有:
求解使似然函数最大的 μ , Σ \mu,\Sigma μ,Σ,令:
将所得结果化简,有:
隐变量取值固定,模型参数 μ i , Σ i \mu_i,\Sigma_i μi,Σi由隐变量 α \alpha α确定。
确定聚类标签
迭代进行E step、M step直到收敛。对于每个样本,将其归类为最高后验概率对应的高斯分布,完成聚类,每个样本的聚类标签为:
一些问题
- EM算法一定收敛吗?结论是一定收敛,但由于 L L L函数不一定是严格凸函数,不能保证收敛到全局最优。
- E step和M step的结果是相互确定的,有点像“鸡生蛋、蛋生鸡”。算法初始时会对模型参数初始化,然后E-M-E…进行迭代,直至收敛。结合上一条,不同初始化可能收敛到不同的结果。
GMM和K-means
当引入一些额外条件,GMM就退化成了K-means:- 各高斯分布混合系数 α i \alpha_i αi相同
- 每个样本以概率1属于一个类
- 协方差矩阵 Σ \Sigma Σ为单位阵
此时该GMM的参数只有 μ \mu μ,用EM算法求解该特殊情况下的GMM如下(也可以说从EM的角度来看待K-means算法):
E step:
M step:
反复迭代执行E、M步骤,直至收敛。如此便得到了K-means算法。算法最初也会对参数进行随机初始化(选择 k k k个样本作为初始均值向量),不同的初始化方法会得到不同的聚类结果,这和GMM的EM算法是一样的。
本文首先介绍了什么是高斯混合,然后介绍了GMM来解决聚类问题的背景,利用EM算法求解GMM模型参数来解决聚类问题,最后介绍了EM观点下GMM和K-means的关联。列出参考链接如下:
高斯混合模型(GMM)的两种详解及简化
《机器学习实战》学习总结(十四)——EM算法
高斯混合模型(GMM)及其EM算法的理解
周志华西瓜书