深度学习基础(不断补充
基于 深度学习基础(mooc上的一门课)
记录知识点,并用代码实现。打好基础,拓展地去运用不同的数据集、不同的库、不同的模型…
文章目录
- 1、机器学习
- 2、深度学习
-
- 2.0感知机介绍
- 2.1支持向量机介绍
- 2.2深度学习基础
-
- 2.2.0步骤介绍1 - 特征工程
-
- 2.2.0.0特征创建(从样本中提取特征)
- 2.2.0.1特征处理
- 2.2.0.2特征选择
- 2.2.0.3特征降维(特征提取)
- 2.2.0.4代码分析
1、机器学习
概念:对研究问题进行模型假设,利用计算机从训练数据中学习得到模型参数。并最终对数据进行云测和分析,其基础是归纳和统计。
引入:
分类问题:
- 二维分类:设定一条直线(y=w*x+b) 或设定一条曲线(y = w1x+w2x2+w3x3…?) 线的一边是一类,另一边是另一类
- 三维分类:设定一个平面,设定一个曲面
- 多维分类:???
步骤(与概念类似):
- 根据问题进行模型假设
- 利用训练集进行模型调参,确定模型
- 利用模型对测试集进行测试,返回评估值
问题:考虑一个多维的分类问题,多维意味着有多个特征,但事实上,许多特征与目标值并没有什么影响;或者就算有影响,但由于维数实在太多,也不得不去省略一些影响不大的特征,来降低维数。这是一方面,机器学习还需要我们来初始化各种参数,甚至调参。
这种特征处理、参数调整的工作量巨大,而且还是由人来做,似乎还是不够智能。所以引出深度学习。
深度学习可以自动学习特征和任务之间的关联,还能从简单特征中提取复杂的特征。
大概是这样,具体怎么样还需探索—to be continued
↓↓↓↓↓↓↓↓↓↓↓↓
2、深度学习
概念:深度学习是实现机器学习的技术,是机器学习的重要分支。基于对人脑轴突树突等神经元的研究,包含了多层隐藏层来模拟人脑。

引入:
 步骤:可以理解为与机器学习一致
步骤:可以理解为与机器学习一致
问题:上文的自动学习特征与任务之间的关联体现在哪里????多层神经网络如何解决特征自动选择,参数自己调节功能????-- >目前深度学习也只是能够把输入的低阶特征组合变换成高阶特征
发展:感知机(单层)-支持向量机(单层)-深度学习(多层)
先了解深度学习的前身,感知机和支持向量机
2.0感知机介绍
感知机
2.1支持向量机介绍
支持向量机
2.2深度学习基础
a.按照深度学习的步骤来进行介绍:
- 面对文本、图像,需要对信息的特征的预处理、量化工作 ——>特征工程
- 预处理完之后,进行训练集、校验集、测试集的拆分——>数据集拆分
- 将数据集放入模型进行训练,并要有一定的评估标准——>性能评估
- 得到了性能评估指标,我们需要进行优化,最后确定模型——>模型优化
- 对于训练集过分拟合会导致对测试集效果不好——>过拟合,要泛化处理(正则化)
- 信息熵?一言蔽之:所有可能事件的信息量的期望一看就懂信息熵-JiangXiaoKun
(总有一天我会根据信息熵,写一篇自己的博客的!!!!)
b.按照常用的神经网络框架来进行介绍:
- 循环神经网络(Recurrent Neural Networks)
- 卷积神经网络(Convolutional Neural Networks)
- 递归神经网络(Recursive Neural Networks)
- 生成式神经网络(Generative Adversarial Networks)
2.2.0步骤介绍1 - 特征工程
一文读懂特征工程-kobejayandy
数据与特征只是决定了机器学习的上限,而模型和算法只是逼近这个值而已
就我的理解,特征工程是一个很大的概念,包括了特征的创建、特征的处理、特征的选择
*特征创建:*tobecontinued
*特征处理:*tobecontinued
*特征选择:*tobecontinued
2.2.0.0特征创建(从样本中提取特征)
自然分词(以英文为例,中文不好操作,jieba库可以提供中文操作):
分词是基础,只有把一串文本分解成单词或者词组,才能进行进一步操作
- 词根提取(stemming),抽取词的词干或者词根形式,用于英文
- 词型还原(lemmatization),抽取词的一般形式,用于英文
- N-gram模型:可用于文档的向量化。
考虑一个只有三个单词构成的句子
“I like apple”
1-gram(uni-gram)就是将其分成三个单词
2-gram(bi_gram)就是分成“I like” “like apple”
3-gram(tri_gram)就是“I like apple” - 其他分词方法:HMM中文分词方法
中文分词的条件随机场模型(CRF)介绍
等等等等…
词性标注(POS):给分得的每一个词标注词性,如PRP(personal pronoun)是人称代词
具体参考滨州数库
句法分析(Syntactic parsing):给分得的词与词之间标注语法关系
以上操作都可以用现成的库来实现:
-
NLTK(natural language toolkit)NLTK使用方法总结-Asia Lee
是python的一个库 -
Text Processing其官网
-
使用curl来访问Text processing API其官网
-
Text blob其使用文档
是一个python的库,更为强大。 -
jieba某博客园文章,介绍得很全面
中文处理就用它
文档向量化:
向量化后的文档可以方便计算文档的距离,以表示相似度
- VSM(Vector space model):基于BOW(bag of word)假设,将每一个文档表示成同一向量空间中的向量。比如两个句子’i like an apple"、“you are beatiful”,则可以创建一个向量空间[0,0,0,0,0,0,0],第一个句子表示为[1,1,1,1,0,0,0]第二个表示为[0,0,0,0,1,1,1]NLP — 文本分类(向量空间模型(Vector Space Model)VSM
- 停用词(stop words):一些非常常见但是没有实际意义的词,在创造词向量空间时可能会被过滤掉,但它也可能在一些词组中很重要。
- 除了停用词之外,还有一些有实际意义的高频词会影响特征。以此我们可以计算一个文档的Tf- idf权重,如图所示

文档相似度:
-
欧氏距离

-
余弦相似度

2.2.0.1特征处理
特征缩放(feature scaler):
- 标准化法
- 区间缩放法
特征规范化:
- 归一化处理:L1 L2
- 定量特征的二值化
缺失值弥补:
- 利用同特征维度的均值
创建多项式特征:比如拥有特征X1、X2,可以得到X1+X2、X1*X2
2.2.0.2特征选择
选择对于学习任务有帮助的特征,以降低维度提高效率、降低学习任务的难度、增加模型的可解释性
主要考虑1、不同样本之间该特征的方差大小----特征是否发散 2、特征与目标的相关性
方差选择法:剔除各个样本特征方差较小的特征
皮尔森相关系数法:计算特征与目标值的相关性,适用于线性关系
基于森林的特征选择:分类器自身提供了特征的重要性分值
递归特征消除:根据重要性分值,舍弃一部分特征,再进行训练,得到新的重要性分值,直到符合条件。
2.2.0.3特征降维(特征提取)
特征选择是对特征进行舍弃,特征降维本质上是将一个特征空间映射到另一个特征空间
线性判别分析(linear discriminant analysis):
是有监督的分析,因为原理是知道了代表不同类别的两个特征,将特征向低维投影,然后计算投影后的,1、一个类别内的特征方差 2、不同类别间的特征方差,要使1比较小(比较接近)、2比较大

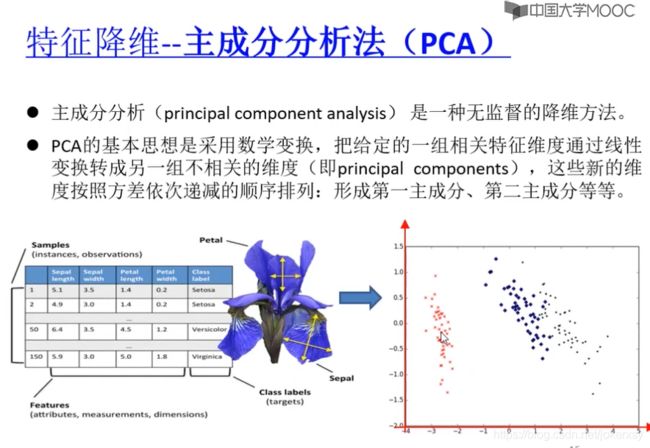
主成分分析(principle component analysis):
是无监督的学习…具体怎么做我去查资料
2.2.0.4代码分析
首先,通过之前的学习,我们直到特征创建中有特征向量化这一步骤(上文具体说的是文档向量化)并提出了:VSM、停词、tf-idf等知识。
下面的代码主要是:
- 简单的对文档进行向量化
- 经过过滤停词对文档进行向量化
- 通过N-gram模型来对文档进行向量化
from sklearn.feature_extraction.text import CountVectorizer # 用于向量化
corpus = [ # 文集
'Jobs was the chairman of Apple Inc., and he was very famous',
'I like to use apple computer',
'And I also like to eat apple'
]
# 未经停用词过滤的文档向量化(简单向量化)
vectorizer =CountVectorizer()
print(vectorizer.fit_transform(corpus).todense()) # 转化为完整特征矩阵
#->result:[[0 1 1 1 0 0 1 1 1 1 0 1 1 0 0 1 2]
# [0 0 1 0 1 0 0 0 0 0 1 0 0 1 1 0 0]
# [1 1 1 0 0 1 0 0 0 0 1 0 0 1 0 0 0]]
## 关于fit_tranform:个人理解为拟合(fit)+tranform(变换)
# 如果仅有transform(vectorizer.transform()) 会报 sklearn.exceptions.NotFittedError:Vocabulary not fitted or provided
# 也可以先写 vectorizer.fit()
# 再写 vectorizer.transform()
## 关于todense()就是把结果转换成matrix
print(vectorizer.vocabulary_) # 打印输入corpus里面出现的所有单词,和它对应的标号
#->result:{'jobs': 9, 'was': 16, 'the': 12, 'chairman': 3, 'of': 11, 'apple': 2, 'inc': 8, 'and': 1, 'he': 7....等等等等}
print(" ")
# 经过停用词过滤后的文档向量化
import nltk
nltk.download('stopwords') # 如果这里一直卡着不执行,试试换个网(如手机热点)
stopwords = nltk.corpus.stopwords.words('english')
print(stopwords)
#->result:{'jobs': 9, 'was': 16, 'the': 12, 'chairman': 3, 'of': 11, 'apple': 2, 'inc': 8, 'and': 1, 'he': 7..............很多}
print(" ")
vectorizer = CountVectorizer(stop_words='english')
print("after stopwords removal: ", vectorizer.fit_transform(corpus).todense())
#->result:[[1 1 0 0 1 1 0 0] # 由于删掉了停词,总的词变少了,维度变少了
# [1 0 1 0 0 0 1 1]
# [1 0 0 1 0 0 1 0]]
print("after stopwords removal: ", vectorizer.vocabulary_)
#->result:{'jobs': 5, 'chairman': 1, 'apple': 0, 'famous': 4, 'like': 6, 'use': 7, 'computer': 2, 'eat': 3}
print(" ")
# 采用ngram模式进行文档向量化
vectorizer = CountVectorizer(ngram_range=(1, 3)) # 表示从1-3,既包括unigram,也包括bigram,还包括trigram 如上文所说 ngram分为 uni、bi、tri 三个gram
print("N-gram mode: ", vectorizer.fit_transform(corpus).todense())
#->result:[[0 0 0 1 0 0 1 1 1 0 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1
# 1 1 0 0 0 0 0 0 0 0 1 1 2 1 1 1 1]
# [0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0
# 0 0 1 0 0 1 1 1 1 1 0 0 0 0 0 0 0]
# [1 1 1 1 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0
# 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0]]
# 有点乱,现在对文档的划分,既要单个单个分,也要两个两个分,还有三个三个分,所以空间很大
print(" ")
print("N-gram mode: ", vectorizer.vocabulary_)
# ->result:{'jobs': 25, 'was': 48, 'the': 35, 'chairman': 12, 'of': 32, 'apple': 8, 'inc': 22, 'and': 3, 思考: 如何计算tf-idf 如何计算文档间距离??? 明天吧,加油。
第二步,特征处理中的特征缩放(标准化法、区间法)
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
import numpy as np
# 标准化法1:手算
X = np.array([[0, 0],
[0, 0],
[100, 1],
[1, 1]])
# calculate mean
X_mean = np.mean(X,axis= 0)
# X_mean2 = X.mean(axis = 0)
# calculate variance
X_std = X.std(axis=0)
X1 = (X - X_mean) / X_std
print(X1)
print("")
# 标准化法2:preprocessing.StandardScaler()
print(preprocessing.StandardScaler().fit_transform(X))
print("")
# 标准化法3:StandardScaler()
Scaler = StandardScaler()
# print(Scaler.fit(X))
print(Scaler.fit_transform(X))
print("")
# 标准化法4:preprocessing.scale()
print(preprocessing.scale(X))
print("")
# 对鸢尾花特征集进行区间缩放
from sklearn import datasets
iris = datasets.load_iris()
data = iris.data
# 方法1 手算 算了吧
# 方法2 preprocessing.MinMaxScaler()
print(preprocessing.MinMaxScaler().fit_transform(data))
print("")
# 方法3 from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
print(scaler.fit_transform(data))思考: preprocessing.scale(X)和StandardScaler().fit_transtorm()的区别是什么?
解答:sklearnpreprocessing中scale和standardscale的区别是什么