呕心沥血深入学正则和字符串
前言:
如果面试官问你exec与match的区别是什么,你应该怎么回答?
这个是我前几天看到牛客网的一个面经,觉得很有意思的一个问题。
正则是我们经常会使用的一个东西,我们可以用一行代码实现很多事情,从最简单的邮箱验证、手机号的验证,到进阶级别的字符串查找,字符串的替换等;
关于正则你真的懂了吗?
正则类型
在创建正则对象的时候有两种创建方式,
字面量方式
//方式一
var myRe=/pattern/flags
var pattern1=/at/g
var pattern1=/at/gi构造函数方式
//方式二
var myRe=new Reg(pattern,flags)flags的三个取值:
- g 表示全局模式
- i 表示不区分大小写
- m 表示多行模式
两种创建方式的区别:对象字面量和构造函数
- 由于构造函数中创建的模式参数是字符串,因此在某些情况下要对字符进行双重转义。
var re1 = /\[bc\]at/;
var re2 = new RegExp("\[bc\]at");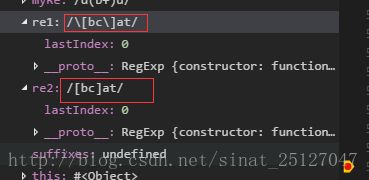
正确的写法是:
var re2 = new RegExp("\\[bc\\]at");2.正则字面量始终会共享同一个RegExp实例,而使用构造函数创建的每一个新RegExp实例都是一个新实例
Reg 实例属性
- global:布尔值,表示是否设置了g标志
- ignoreCase:布尔值,表示是否设置了i标志
- lastIndex :表示下一次开始搜索的位置
- multiline:布尔值,表示是否设置了m标志
- source:正则表达式的字符串
Reg 实例方法
Reg只有两个实例方法:exec和test;
回到开头那个问题:exec是Reg对象的实例方法,match是String对象的实例方法(属于模式匹配方法中的一种);
但是其实exec和match方法的效果类似;
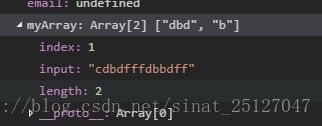
var myRe = new RegExp('d(b+)d', "g");
var myArray = myRe.exec("cdbdfffdbbdff");//[ 'dbd', 'b', index: 1, input: 'cdbdfffdbbdff' ]会返回一个数组myArray:
数组的值就是找到的字符串,数组的对象index 为第一个找到的位置,input:输入的字符串
str.match() 和 RegExp.exec() 的区别
1.正则没有g标志
如果正则表达式没有 g 标志,则 str.match() 会返回和 RegExp.exec() 相同的结果。而且返回的 Array 拥有一个额外的 input 属性,该属性包含被解析的原始字符串。另外,还拥有一个 index 属性,该属性表示匹配结果在原字符串中的索引(以0开始)。
var str = "cdbdfffdbbdff";
var myRe = new RegExp('d(b+)d');
var myArray = myRe.exec("cdbdfffdbbdff");
var myArray2 = str.match(myRe)
console.log(myArray)//[ 'dbd', 'b', index: 1, input: 'cdbdfffdbbdff' ]
console.log(myArray2)//[ 'dbd', 'b', index: 1, input: 'cdbdfffdbbdff' ]2.正则有g标志
如果有g标志就不一样了,如果正则表达式包含 g 标志,则该方法返回一个 Array ,它包含所有匹配的子字符串而不是匹配对象。捕获组不会被返回(即不返回index属性和input属性)。如果没有匹配到,则返回 null 。
var str = "cdbdfffdbbdff";
var myRe = new RegExp('d(b+)d', "g");
var myArray = myRe.exec("cdbdfffdbbdff");
var myArray2 = str.match(myRe)
console.log(myArray)//[ 'dbd', 'b', index: 1, input: 'cdbdfffdbbdff' ]
console.log(myArray2)//[ 'dbd', 'dbbd' ]match() 返回的是一个包含了整个匹配结果以及任何括号捕获的匹配结果的 Array ;如果没有匹配项,则返回 null 。
String类型
基本包装类型
1. 概念
首先String是基本包装类型;
什么是基本包装类型呢?就是只允许你使用它的方法,不允许你向它添加方法;
书中是这么说的:为了便于操作基本类型,ECMAScript还提供了3个特殊的引用类型:Boolean,Number,String;
他们与引用类型相似,当读取一个基本类型值的时候,后台就会创建一个对应的基本包装类型的对象。
例如
var s="some text";
var s2=s.substring(2);这行代码在后天实际做了以下的事:
- 创建String类型的一个实例;
- 在实例上调用指定的方法;
- 销毁这个实例;
2. 基本包装类型与引用类型的区别
- 对象生存期
使用new创建的引用类型的实例,在执行流离开当前作用域之前都保存在内存中;
但是自动创建的基本包装类型的对象,只存在于代码执行的瞬间,然后立即被销毁;
所以我们不能在运行时为基本类型添加属性和方法;
var b = 1;
var h = new Number(1)
h.name = "array"
b.name = "array"
console.log(h)//{ [Number: 1] name: 'array' }
console.log(b) //1- typeof结果不一样
typeof只针对基本类型检测,如果是new Number()检测出的只是object而已;
但是可以采用Object.prototype.call(h),返回的就是[Object Number]
3. 字符串中的模式匹配方法
match()
前面已经对比过了match和Reg的exec()方法;
search()
search和test也相似,返回字符串中第一个匹配项的索引,如果没有则返回1;
replace()
这个方法用于替换;
接受两个参数:
- 第一个参数:RegExp对象或者一个字符串;
- 第二个参数:一个字符串或者一个函数;
如果第一个参数是字符串,那么只替换字符串中第一个匹配到的字符串;要想全局替换,则必须是RegExp对象,并带有g标志;
匹配的结果:
字符串
| 字符序列 | 替换文本 |
|---|---|
| $$ | $ |
| $& | 匹配整个模式的子字符串 |
| $’ | 匹配的子字符串之前的子字符串,与RegExp.leftContext的值相同 |
| $` | 匹配的子字符串之h后的子字符串,与RegExp.rightContext的值相同 |
| $n | 匹配第n个捕获组的子字符串 |
| $nn | 匹配第nn个捕获组的子字符串 |
var text = "cat,bat,sat,fat";
var result = text.replace(/(.at)/g, "world($1)"); //world(cat),world(bat),world(sat),world(fat)
var result2 = text.replace(/(.at)/g, "world($')"); //world(,bat,sat,fat),world(,sat,fat),world(,fat),world()函数
var result2 = text.replace(/(.at)/g, function(match, pos, offset, origin) {
console.log('match:' + match);
console.log('pos:' + pos);
console.log('offset:' + offset);
console.log('origin:' + origin);
});函数的参数依次是:
| 参数 | 说明 |
|---|---|
| match | 匹配的子串。(对应于上述的$&。) |
| p1,p2, … | 假如replace()方法的第一个参数是一个RegExp 对象,则代表第n个括号匹配的字符串。(对应于上述的 1, 2等。) |
| offset | 匹配到的子字符串在原字符串中的偏移量。(比如,如果原字符串是“abcd”,匹配到的子字符串是“bc”,那么这个参数将是1) |
| string | 被匹配的原字符串。 |
多个模式的匹配
因为正则语言(w),表示记住()中的内容,也就是说匹配到了()中的文本就用$1,$2这样记住下来
var result2 = text.replace(/(.at),(fat)/g, "world($1 $2)");
//cat,bat,world(sat fat)
console.log(result2)
var result2 = text.replace(/(.at),(fat)/g, function(match, p1, p2, offset, origin) {
console.log('match:' + match); //match:sat,fat
console.log('p1:' + p1);//p1:sat对应$1
console.log('p2:' + p2);//p2:fat 对应$2
console.log('origin:' + origin);
});终于搞懂了$1 $2 $' $` ....