Zookeeper
zookeeper
一、简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
一个基于观察者模式的分布式服务管理架构,它负责存储管理大家关心的数据,然后接收观察者注册,一旦这些数据发生状态变化,ZooKeeper就将负责通知在ZooKeeper上注册的观察者做出反应,就像redis的maser/slaver。
命名服务、配置维护、集群管理、分布式消息同步和协调机制、负载均衡、对Dubbo的支持。
二、Linux下安装ZooKeeper并启动
前往ZooKeeper官网,下载ZooKeeper页面。此处使用3.5.6版本
ZooKeeper需要Java环境的支持,所以服务器要先安装JDK
将apache-zookeeper-3.5.6.tar.gz文件通过Xftp传输到Linux系统上,解压放进myzookeeper文件夹
makdir myzookeeper 创建文件夹
tar -zxvf apache-zookeeper-3.5.6.tar.gz 解压命令
cp -r apache-zookeeper-3.5.6-bin /opt/software/myzookeeper copy进自己创建的文件夹
成功后进入文件夹查看
[root@localhost myzookeeper]# cd apache-zookeeper-3.5.6-bin/
[root@localhost apache-zookeeper-3.5.6-bin]# ll
总用量 32
drwxr-xr-x. 2 user user 232 10月 9 04:14 bin
drwxr-xr-x. 2 user user 70 3月 19 17:03 conf
drwxr-xr-x. 5 user user 4096 10月 9 04:15 docs
drwxr-xr-x. 2 root root 4096 11月 10 13:29 lib
-rw-r--r--. 1 user user 11358 10月 5 19:27 LICENSE.txt
drwxr-xr-x. 2 root root 61 11月 10 13:32 logs
-rw-r--r--. 1 user user 432 10月 9 04:14 NOTICE.txt
-rw-r--r--. 1 user user 1560 10月 9 04:14 README.md
-rw-r--r--. 1 user user 1347 10月 5 19:27 README_packaging.txt
ZooKeeper配置文件在 conf下的zoo.cfg,我修改并注释的配置文件在最下方。
进入bin目录 启动server,启动client,退出
[root@localhost apache-zookeeper-3.5.6-bin]# cd bin/
[root@localhost bin]# ./zkServer.sh start 启动
ZooKeeper JMX enabled by default
Using config: /opt/software/myzookeeper/apache-zookeeper-3.5.6-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@localhost bin]# ps -ef |grep zookeeper 查看启动情况
…………
[root@localhost bin]# ./zkCli.sh 启动客户端
…………
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls / 启动成功
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[quota]
[zk: localhost:2181(CONNECTED) 2] quit 退出连接
[root@localhost bin]# ./zkServer.sh stop 关闭服务
三、Helloword
[zk: localhost:2181(CONNECTED) 0] ls /
[dubbo, zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /helloword hello 创建节点
Created /helloword
[zk: localhost:2181(CONNECTED) 2] ls /
[dubbo, helloword, zookeeper]
[zk: localhost:2181(CONNECTED) 3] get /helloword 获取节点
hello
[zk: localhost:2181(CONNECTED) 4] set /helloword hello01 set节点
[zk: localhost:2181(CONNECTED) 5] get /helloword
hello01
[zk: localhost:2181(CONNECTED) 6] delete /helloword 删除节点
[zk: localhost:2181(CONNECTED) 7] ls /
[dubbo, zookeeper]
ZooKeeper数据模型结构就像是Linux的文件系统,整体上能够看作是一棵树,每个节点成为ZNode,每个节点默认最大存储1M。每个节点通过路径唯一标识
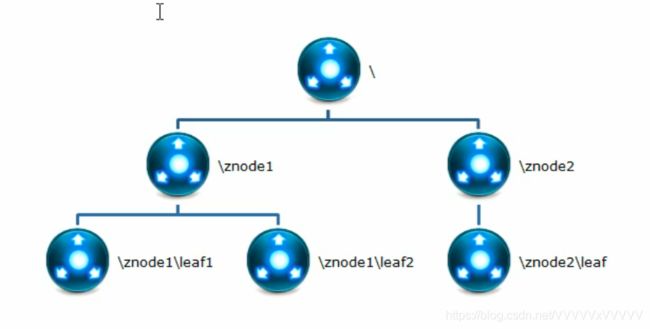
四、节点
[zk: localhost:2181(CONNECTED) 11] create /test test01
Created /test
[zk: localhost:2181(CONNECTED) 12] create /test test02
Node already exists: /test
[zk: localhost:2181(CONNECTED) 23] create /helloword helloword
Created /helloword
[zk: localhost:2181(CONNECTED) 24] get /helloword
helloword
[zk: localhost:2181(CONNECTED) 25] stat /helloword 节点状态
cZxid = 0x79 事务ID
ctime = Fri Mar 20 10:03:06 CST 2020 创建时间
mZxid = 0x79 修改的事务id
mtime = Fri Mar 20 10:03:06 CST 2020 修改时间
pZxid = 0x79 最后更新的子节点zxid
cversion = 0 子节点变化号
dataVersion = 0 数据变化号
aclVersion = 0 访问控制列表变化号
ephemeralOwner = 0x0 不是临时节点为0,是临时节点znode拥有者的session id
dataLength = 9 数据长度
numChildren = 0 子节点数
[zk: localhost:2181(CONNECTED) 26]
-
节点类型:
-
持久型节点:①客户端与服务器断开后创建节点不删除,依旧存在②客户端与服务器断开后创建节点不删除,依旧存在,但是会进行顺序编号
-
临时目录节点:①客户端与服务器断开或者挂掉后创建节点立即删除②客户端与服务器断开或者挂掉后创建节点立即删除,但是新建会编号增加
[zk: localhost:2181(CONNECTED) 26] create -s /myznode01 v01 -s自动编号 Created /myznode010000000005 [zk: localhost:2181(CONNECTED) 27] ls / [dubbo, helloword, myznode010000000005, zookeeper] [zk: localhost:2181(CONNECTED) 28] create -s /myznode01 v02 Created /myznode010000000006 [zk: localhost:2181(CONNECTED) 29] ls / [dubbo, helloword, myznode010000000005, myznode010000000006, zookeeper] [zk: localhost:2181(CONNECTED) 30] create -e /mytest v01 -e临时节点 Created /mytest [zk: localhost:2181(CONNECTED) 32] ls / [dubbo, helloword, mytest, myznode010000000005, myznode010000000006, zookeeper]什么都不带就是持久化 -p 带序号 -s节点,重启客户端发现mytest没了
WatchedEvent state:SyncConnected type:None path:null [zk: localhost:2181(CONNECTED) 0] ls / [dubbo, helloword, myznode010000000005, myznode010000000006, zookeeper] [zk: localhost:2181(CONNECTED) 1]
-
五、通知机制watch
客户端监听它关心的目录节点,当目录节点发生变化时,zookeeper会通知客户端。
watch:异步+回调+触发机制
# 在client1中监视
[zk: localhost:2181(CONNECTED) 1] get /testwatch watch01
persistent,no-sequence
cZxid = 0x81
ctime = Fri Mar 20 12:56:08 CST 2020
mZxid = 0x82
mtime = Fri Mar 20 12:56:30 CST 2020
pZxid = 0x81
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
# 在client2中set
[zk: localhost:2181(CONNECTED) 0] set /testwatch watch02
cZxid = 0x81
ctime = Fri Mar 20 12:56:08 CST 2020
mZxid = 0x82
mtime = Fri Mar 20 12:56:30 CST 2020
pZxid = 0x81
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
# client1监视到数据变化
[zk: localhost:2181(CONNECTED) 2]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/testwatch
六、Zookeeper集群leader+flower
在多台服务器上配置Zookeeper服务端和客户端,配置配置文件zoo.cfg 书写规则如下
#server.N=YYYY :AA :BB
#N为服务编号,AA为通信端口,集群中交换信息的端口,zookeeper默认就是2888,BB为选举新leader端口,一般所有机器的A、B端口一致
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
分别启动三台服务,三台客户端。
注:上边我已经将IP映射地址写入hosts文件,根据自己情况写,没有那么多服务器的可以用伪集群。
copy apache-zookeeper-3.5.6-bin 文件,重命名zk1、zk2、zk3,分别修改配置文件中的clientPort为2182、2183、2184,数据存储位置也要改,日志位置也要改,集群配置改为如下
server.1=127.0.0.1:2182:3991
server.2=127.0.0.1:2183:3992
server.3=127.0.0.1:2184:3993
分别启动三台服务器
四个终端分别客户端连接
./zkCli.sh -server 127.0.0.1:2182
./zkCli.sh -server 127.0.0.1:2183
./zkCli.sh -server 127.0.0.1:2184
Zookeeper
-
核心:ZooKeeper:文件系统+通知机制
-
可做注册中心,软负载均衡
-
奇数机制:最好用奇数台。因为半数以上机器存活集群可用。
-
leader选举机制:一个leader,多个flower,leader宕机之后他们会投票,先投自己,投票超过半数就是leader,如果投自己不行,就投id号最大的,选完leader后就不再选。
-
节点类型:
1. 持久型节点:①客户端与服务器断开后创建节点不删除,依旧存在②客户端与服务器断开后创建节点不删除,依旧存在,但是会进行顺序编号
2. 临时目录节点:①客户端与服务器断开或者挂掉后创建节点立即删除②客户端与服务器断开或者挂掉后创建节点立即删除,但是新建会编号增加 -
监听原理:首先一个main线程,main线程中创建客户端,然后创建两个线程,一个负责网络通信,一个负责监听,通过connect线程将注册事件发送给ZooKeeper,在ZooKeeper的注册监听器列表中,将事件添加到列表中,ZooKeeper监听到有数据变化,或者路径变化,就会将消息发送给listener线程,listener线程内部调用process方法,常见监听:监听节点:get 节点watch 监听路径子节点数量变化:ls 节点 watch
ZooKeeper的配置文件,zoo.cfg文件
#The number of milliseconds of each tick
#心跳时间,每个2S检测一次
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
#1通信时长延迟启动时,初始链接时能容忍的心跳次数10*2S
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
#启动之后通信时间延时5*2S
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#存储数据位置zkData文件夹
dataDir=/opt/software/zkData
# the port at which the clients will connect
#客户端访问端口号
clientPort=2181
#配置集群时,node为域名(Ip地址,在etc/hosts里边配置),2888为zookeeper的通信端口3888为选举的端口号,不用集群时不用配置
#server.N=YYYY :AA :BB
#N为服务编号,AA为通信端口,集群中交换信息的端口,zookeeper默认就是2888,BB为选举新leader端口
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
server.4=node04:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
# maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1