设计模式 #1(7大设计原则)
单一职责原则
简述:单个类,单个方法或者单个框架只完成某一特定功能。
需求:统计文本文件中有多少个单词。
反例:
public class nagtive {
public static void main(String[] args) {
try{
//读取文件的内容
Reader in = new FileReader("E:\\1.txt");
BufferedReader bufferedReader = new BufferedReader(in);
String line = null;
StringBuilder sb = new StringBuilder("");
while((line =bufferedReader.readLine()) != null){
sb.append(line);
sb.append(" ");
}
//对内容进行分割
String[] words = sb.toString().split("[^a-zA-Z]+");
System.out.println(words.length);
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上面代码违反单一职责原则,同一个方法我们让它去做文件读取,还让他去做内容分割;当有需求变更(需要更换加载文件,统计文本文件中有多少个句子)时,我们需要重写整个方法。
正例:
public class postive {
public static StringBuilder loadFile(String fileLocation) throws IOException {
//读取文件的内容
Reader in = new FileReader("E:\\1.txt");
BufferedReader bufferedReader = new BufferedReader(in);
String line = null;
StringBuilder sb = new StringBuilder("");
while ((line = bufferedReader.readLine()) != null) {
sb.append(line);
sb.append(" ");
}
bufferedReader.close();
return sb;
}
public static String[] getWords(String regex, StringBuilder sb){
//对内容进行分割
return sb.toString().split(regex);
}
public static void main(String[] args) throws IOException {
//读取文件的内容
StringBuilder sb = loadFile("E:\\1.txt");
//对内容进行分割
String[] words = getWords("[^a-zA-Z]+", sb);
System.out.println(words.length);
}
}
遵守单一原则,可以给我们带来的好处是,提高了代码的可重用性,同时还让得到的数据不再有耦合,可以用来完成我们的个性化需求。
开闭原则
简述:对扩展(新功能)开放,对修改(旧功能)关闭
实体类设计:
public class Pen {
private String prod_name;
private String prod_origin;
private float prod_price;
public String getProd_name() {
return prod_name;
}
public void setProd_name(String prod_name) {
this.prod_name = prod_name;
}
public String getProd_origin() {
return prod_origin;
}
public void setProd_origin(String prod_origin) {
this.prod_origin = prod_origin;
}
public float getProd_price() {
return prod_price;
}
public void setProd_price(float prod_price) {
this.prod_price = prod_price;
}
@Override
public String toString() {
return "Pen{" +
"prod_name='" + prod_name + '\'' +
", prod_origin='" + prod_origin + '\'' +
", prod_price=" + prod_price +
'}';
}
}
public static void main(String[] args) {
//输入商品信息
Pen redPen = new Pen();
redPen.setProd_name("英雄牌钢笔");
redPen.setProd_origin("厂里");
redPen.setProd_price(15.5f);
//输出商品信息
System.out.println(redPen);
}
需求:商品搞活动,打折8折销售。
反例:在实体类的源代码,修改 setProd_price 方法
public void setProd_price(float prod_price) {
this.prod_price = prod_price * 0.8f;
}
违反了开闭原则,在源代码中修改,对显示原价这一功能进行了修改。
在开发时,我们应该,必须去考虑可能会变化的需求,属性在任何时候都可能发生改变,对于需求的变化,在要求遵守开闭原则的前提下,我们应该在开发中去进行扩展,而不是修改源代码。
正例:
public class discountPen extends Pen{
//用重写方法设置价格
@Override
public void setProd_price(float prod_price) {
super.setProd_price(prod_price * 0.8f);
}
}
public class postive {
public static void main(String[] args) {
//输入商品信息,向上转型调用重写方法设置价格
Pen redPen = new discountPen();
redPen.setProd_name("英雄牌钢笔");
redPen.setProd_origin("厂里");
redPen.setProd_price(15.5f);
//输出商品信息
System.out.println(redPen);
}
}
开闭原则并不是必须要一味地死守,需要结合开发场景进行使用,如果需要修改的源代码是自己写的,修改之后去完成需求,当然是简单快速的;但是如果源代码是别人写的,或者是别人的架构,修改是存在巨大风险的,这时候应该去遵守开闭原则,防止破坏结构的完整性。
接口隔离原则
简述:设计接口的时候,接口的抽象应是具有特定意义的。需要设计出的是一个内聚的、职责单一的接口。“使用多个专门接口总比使用单一的总接口好。”这一原则不提倡设计出具有“普遍”意义的接口。
反例:动物接口中并不是所有动物都需要的。
public interface Animal {
void eat();
void fiy(); //泥鳅:你来飞?
void swim(); // 大雕:你来游?
}
class Bird implements Animal {
@Override
public void eat() {
System.out.println("用嘴巴吃");
}
@Override
public void fiy() {
System.out.println("用翅膀飞");
}
@Override
public void swim() {
//我是大雕不会游泳
}
}
接口中的 swim() 方法在实际开发中,并不适用于该类。
正例:接口抽象出同一层级的特定意义,提供给需要的类去实现。
public interface Fly {
void fly();
}
public interface Eat {
void eat();
}
public interface Swim {
void swim();
}
public class Bird_02 implements Fly,Eat{
@Override
public void eat() {
System.out.println("用嘴巴吃");
}
@Override
public void fly() {
System.out.println("用翅膀飞");
}
//我是大雕不会游泳
}
客户端依赖的接口中不应该存在他所不需要的方法。
如果某一接口太大导致这一情况发生,应该分割这一接口,使用接口的客户端只需要知道他需要使用的接口及该接口中的方法即可。
依赖倒置原则
简述:上层不能依赖于下层,他们都应该依赖于抽象。
需求:人喂养动物
反例:
public class negtive {
static class Person {
public void feed(Dog dog){
dog.eat();
}
}
static class Dog {
public void eat() {
System.out.println("主人喂我了。汪汪汪...");
}
}
public static void main(String[] args) {
Person person= new Person();
Dog dog = new Dog();
person.feed(dog);
}
}
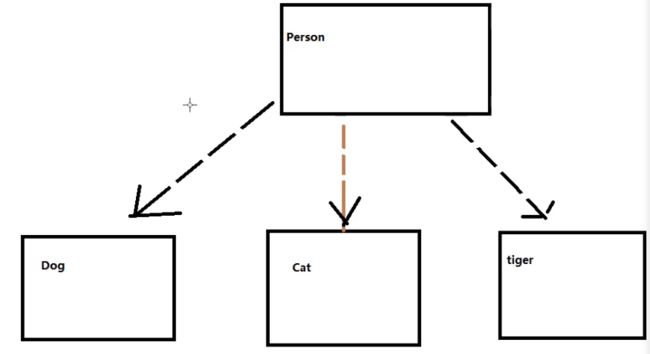
这时候,Person内部的feed方法依赖于Dog,是上层方法中又依赖于下层的类。(人竟然依赖于一条狗?这算骂人吗?)
当有需求变更,人的宠物不止有狗狗,还可以是猫等等,这时候需要修改上层类,这带来的是重用性的问题,同时还违反上面提到的开闭原则。
正例:
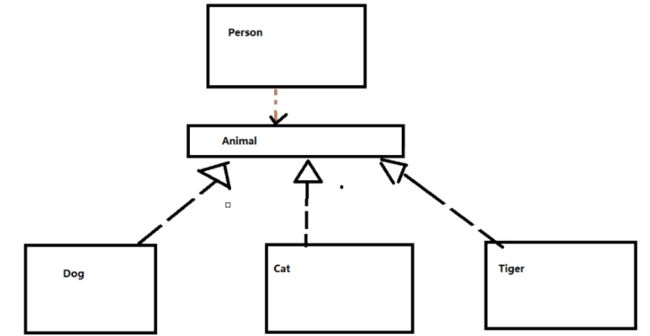
public class postive {
static class Person {
public void feed(Animal animal){
animal.eat();
}
}
interface Animal{
public void eat();
}
static class Dog implements Animal{
public void eat() {
System.out.println("我是狗狗,主人喂我了。汪汪汪...");
}
}
static class Cat implements Animal{
public void eat() {
System.out.println("我是猫咪,主人也喂我了。(我为什么要说也?)喵喵喵...");
}
}
public static void main(String[] args) {
Person person= new Person();
Dog dog = new Dog();
Cat cat = new Cat();
person.feed(dog);
person.feed(cat);
}
}
这时候,Person内部的feed方法不在依赖于依赖于Dog或者Cat,而是不管是Person,还是Dog或者Cat,他们都依赖与Animal这一抽象类,都依赖于抽象类。
这时候,不管是曾经的上层代码,还是曾经的下层代码,都不会因为需求而改变。
依赖倒转原则就是指:代码要依赖于抽象的类,而不要依赖于具体的类;要针对接口或抽象类编程,而不是针对具体类编程。通过面向接口编程,抽象不应该依赖于细节,细节应该依赖于抽象。
迪米特法则(最少知道原则)
简述:一个类对于其他类知道的越少越好,就是说一个对象应当对其他对象有尽可能少的了解,只和朋友通信,不和陌生人说话。
反例:
public class negtive {
class Computer{
public void closeFile(){
System.out.println("关闭文件");
}
public void closeScreen(){
System.out.println("关闭屏幕");
}
public void powerOff(){
System.out.println("断电");
}
}
class Person{
private Computer computer;
public void offComputer(){
computer.closeFile();
computer.closeScreen();
computer.powerOff();
}
}
}
这时候,Person 知道了 Computer的很多细节,对于用户来说不够友好,而且,用户还可能会调用错误,先断电,再保存文件,显然不符合逻辑,会导致文件出现未保存的错误。
其实对于用户来说,知道进行关机就行了。
正例:封装细节
public class postive {
class Computer{
public void closeFile(){
System.out.println("关闭文件");
}
public void closeScreen(){
System.out.println("关闭屏幕");
}
public void powerOff(){
System.out.println("断电");
}
public void turnOff(){ //封装细节
this.closeFile();
this.closeScreen();
this.powerOff();
}
}
class Person{
private Computer computer;
public void offComputer(){
computer.turnOff();
}
}
}
前面说的,只和朋友通信,不和陌生人说话。先来明确一下什么才叫做朋友:
什么是朋友?
- 类中的字段
- 方法的返回值
- 方法的参数
- 方法中的实例对象
- 对象本身
- 集合中的泛型
总的来说,只要在自身内定义的就是朋友,通过其他方法得到的都只是朋友的朋友;
但是,朋友的朋友不是我的朋友。
举个反例:
public class negtive {
class Market{
private Computer computer;
public Computer getComputer(){
return this.computer;
}
}
static class Computer{
public void closeFile(){
System.out.println("关闭文件");
}
public void closeScreen(){
System.out.println("关闭屏幕");
}
public void powerOff(){
System.out.println("断电");
}
}
class Person{
private Market market;
Computer computer =market.getComputer();
// //此时的 computer 并不是 Person 的朋友,只是 Market 的朋友。
}
}
在实际开发中,要完全符合迪米特法则,也会有缺点:
-
在系统里造出大量的小方法,这些方法仅仅是传递间接的调用,与系统的业务逻辑无关。
-
遵循类之间的迪米特法则会是一个系统的局部设计简化,因为每一个局部都不会和远距离的对象有直接的关联。但是,这也会造成系统的不同模块之间的通信效率降低,也会使系统的不同模块之间不容易协调。
因此,前人总结出,一些方法论以供我们参考:
-
优先考虑将一个类设置成不变类。
-
尽量降低一个类的访问权限。
-
谨慎使用
Serializable。 -
尽量降低成员的访问权限。
虽然规矩很多,但是理论需要深刻理解,实战需要经验积累。路还很长。
里氏替换原则
简述:任何能使用父类对象的地方,都应该能透明地替换为子类对象。
需求:将长方形的宽改成比长大 1 。
反例:在父类Rectangular下,业务场景符合逻辑。现有子类Square,替换后如何。
public class negtive {
static class Rectangular {
private Integer width;
private Integer length;
public Integer getWidth() {
return width;
}
public void setWidth(Integer width) {
this.width = width;
}
public Integer getLength() {
return length;
}
public void setLength(Integer length) {
this.length = length;
}
}
static class Square extends Rectangular {
private Integer sideWidth;
@Override
public Integer getWidth() {
return sideWidth;
}
@Override
public void setWidth(Integer width) {
this.sideWidth = width;
}
@Override
public Integer getLength() {
return sideWidth;
}
@Override
public void setLength(Integer length) {
this.sideWidth = length;
}
}
static class Utils{
public static void transform(Rectangular graph){
while ( graph.getWidth() <= graph.getLength() ){
graph.setWidth(graph.getWidth() + 1);
System.out.println("长:"+graph.getLength()+" : " +
"宽:"+graph.getWidth());
}
}
}
public static void main(String[] args) {
// Rectangular graph = new Rectangular();
Rectangular graph = new Square();
graph.setWidth(20);
graph.setLength(30);
Utils.transform(graph);
}
}
替换后运行将是无限死循环。
要知道,在向上转型的时候,方法的调用只和new的对象有关,才会造成不同的结果。在使用场景下,需要考虑替换后业务逻辑是否受影响。
由此引出里氏替换原则的使用需要考虑的条件:
- 是否有
is-a关系 - 子类可以扩展父类的功能,但是不能改变父类原有的功能。
这样的反例还有很多,如:鸵鸟非鸟,还有咱们老祖宗早就说过的的春秋战国时期--白马非马说,都是一个道理。
组合优于继承
简述:复用别人的代码时,不宜使用继承,应该使用组合。
需求:制作一个组合,该集合能够记录下曾经添加过多少元素。(不只是统计某一时刻)
反例 #1:
public class negtive_1 {
static class MySet extends HashSet{
private int count = 0;
public int getCount() {
return count;
}
@Override
public boolean add(Object o) {
count++;
return super.add(o);
}
}
public static void main(String[] args) {
MySet mySet = new MySet();
mySet.add("111111");
mySet.add("22222222222222");
mySet.add("2333");
Set hashSet = new HashSet();
hashSet.add("集合+11111");
hashSet.add("集合+22222222");
hashSet.add("集合+233333");
mySet.addAll(hashSet);
System.out.println(mySet.getCount());
}
}
看似解决了需求,add 方法可以成功将count进行自加, addAll方法通过方法内调用add,可以成功将count进行增加操作。
缺陷:JDK 版本如果未来进行更新,addAll方法不再通过方法内调用add,那么当调用addAll进行集合添加元素时,count将不无从进行自加。需求也将无法满足。
HashMap 就在 1.6 1.7 1.8就分别更新了三次。
反例 #2:
public class negtive_2 {
static class MySet extends HashSet{
private int count = 0;
public int getCount() {
return count;
}
@Override
public boolean add(Object o) {
count++;
return super.add(o);
}
@Override
public boolean addAll(Collection c) {
boolean modified = false;
for (Object e : c)
if (add(e))
modified = true;
return modified;
}
}
public static void main(String[] args) {
MySet mySet = new MySet();
mySet.add("111111");
mySet.add("22222222222222");
mySet.add("2333");
Set hashSet = new HashSet();
hashSet.add("集合+11111");
hashSet.add("集合+22222222");
hashSet.add("集合+233333");
mySet.addAll(hashSet);
System.out.println(mySet.getCount());
}
}
亲自再重写addAll方法,确保addAll方法一定能调用到add方法,也就能够对 count进行增加操作。
但是,问题还是有的:
缺陷:
- 如果未来,
HashSet新增了一个addSome方法进行元素的添加,那就白给了。 - 重写了
addAll、add这两个方法,如果JDK中其他类的某些方法依赖于HashMap中的这两个方法,那么JDK中其他类依赖于HashMap中的这两个方法的某些方法就会有出错、崩溃等风险。
这时候,可以得出一些结论:
当我们不属于继承父类的开发团队时,是没办法保证父类代码不会被修改,或者修改时一定被通知到,这时候,就可能会出现需求满足有缺陷的情况。所以,但我们去复用父类的代码时,避免去重写或者新建方法,这样可以防止源代码结构发生改变带来的打击。
也就是说,我们在重用代码时,应该是组合优于继承。
正例:
public class postive {
class MySet{
private HashSet hashSet;
private int count = 0;
public int getCount() {
return count;
}
public boolean add(Object o) {
count++;
return hashSet.add(o);
}
public boolean addAll(Collection c) {
count += c.size();
return hashSet.addAll(c);
}
}
public static void main(String[] args) {
negtive_2.MySet mySet = new negtive_2.MySet();
mySet.add("111111");
mySet.add("22222222222222");
mySet.add("2333");
Set hashSet = new HashSet();
hashSet.add("集合+11111");
hashSet.add("集合+22222222");
hashSet.add("集合+233333");
mySet.addAll(hashSet);
System.out.println(mySet.getCount());
}
}
利用组合,实现解耦,将HashSet和自定义类MySet由原来的继承关系改为了低耦合的组合关系。