Python学习进阶:函数及文件的使用
*************************************************************************************************************
进阶教程是在熟悉Python基础语法以及常用数据结构的基础之上,进一步学习Python的相关知识,本部分主要涉及函数与模块、文件的操作两部分,之后,还会就Python的高阶教程,即面向对象的编程、GUI教程、多线程编程进行相关的学习和介绍。
此外,本部分内容是以《Python程序设计:任务式驱动教程》@作者:郑凯梅 这本书为基础对Python相关知识进行介绍,结合网上资料以及相关例程对Python相关知识进行解读和总结,帮助Python学习者步入面向高级的应用。
*************************************************************************************************************
#5函数与模块
函数是组织好的,可重复使用的,用来实现单一、或者相关联功能的代码段。
模块(module)是方法的集合,相当于内部函数的集合。使用import 导入,模块类型是py文件;
包(package)是一个总目录。包目录下为首的一个文件是__init__.py。
5.1函数
为提高编程效率、代码的可靠性,使用Python的函数机制,函数是一个被指定名称的代码块。在任何地方要使用该代码块时,只要提供函数的名称即可,也称为函数调用。
5.1.1函数的定义与使用
@1定义函数
一般格式如下:
def 函数名(参数列表):
"函数文档字符串"
函数体
return [表达式|值]
注意:
(1)return语句是可选的,可以在函数体内的任何地方出现,表示函数调用到此结束。
如果没有return,则自动返回NONE,如果有return,但是没有返还值,也返回NONE
(2)函数函数名必须唯一。如果以同样的名字再定义一个函数,将会将之前的函数覆盖。@2使用函数
函数定义不会改变程序的执行流程。函数定义中的语句不是立即执行的,而是等到函数被调用时才会被执行
函数调用格式如下:
函数名(参数列表)
注意:
(1)函数名必须是已经定义好的函数;
(2)参数列表中参数的个数和类型与函数定义中的参数一般要一一对应。另外,Python支持其他其他参数传递方式 ,详见5.1.2部分;
(3)在函数调用之前使用函数会发生错误。
5.1.2函数的参数
Python函数有两种类型的参数。一种是函数定义中出现的参数,称为形参;另一种是调用函时传入的参数,称为实参。
Python中任何东西都是对象,所以参数只支持引用传递的方式。将形参与实参指向内存中的同一个存储空间。
Python函数中,实参向形参的传递方式有4种:按位置传递参数、按默认值传递参数、按关键字传递函数和可变参数传递
@1按位置传递参数
当实际参数按照位置传递给形参时,函数调用语句中的实际参数和函数头中的形式参数按顺序一一对应,即第一个实参传递给第一个形参,第二个实参传递给第二个形参,以此类推
如果实参指向的对象是不可变的,如数值、字符串或者元组对象时,即使在函数中改变了形参的值,实参指向的对象也不会改变。
例程如下:
例1:【不可变对象传值】
def sample1(num):
num = num +2
return num
num =25
print(sample1(num)) #27 形参改变,返回值为27
print(num) #25 实参不变,num认为25
例2:【可变对象传值】
mylist =[1,2,3,'',2019]
def sample2(list_1):
list_1.append('hoo') #这里是因为append()函数的使用,所以是对可变对象传值
print('in the function :{}'.format(list_1)) #结果是[1,2,3,'',2019, ‘hoo’]
retun
print('out the function:{}'.format(mylist)) #结果是[1,2,3,'',2019, ‘hoo’]
@2按默认值传递函数
Python中的函数也可以给一个或者多个参数(包括全部形参)指定默认值。如果在函数调用过程中省略了相应的实际参数,这些参数就使用默认值。这样,在调用时可以选择性的省略该参数。
定义默认值函数的格式如下:
def 函数名(形参1,形参2,形参3=值1,形参4=值2):
函数体
注意:
(1)函数调用时,除具有默认值的形参除外、其他形参必须有对应的实参传递;
(2)函数定义时,没有默认值的形参必须放在有默认值的形参之前。否则会报错@3 按关键字传递参数
函数调用时,以"形参名=值"的形式来进行函数的调用,这种形参和实参之间的传值方式被称为关键字传值。
对应关系明确指出,所以不限制参数传递的顺序@4可变参数传递
一般情况下,Python中用带*的参数用来接收可变数量参数的
在形参前加一个星号(*)或者两个星号(**)来指定接收可变数量参数的
格式如下:
def 函数名(形参1,形参2,....,形参n,*turpleArg, **dictArg):
函数体
注意:
(1)不带*的是参数是普通形参。调用时可以按照位置传递、按默认值传递、或者按照关键字传递的方式;
(2)对于多余的非关键字参数,函数调用时放在元组参数turpleArg中
(3)对于多余的关键字参数,函数调用时放在字典参数dictArg中5.1.3函数的返回值
函数的返回值可以是多个,返回值可以是数值、字符串、布尔型、列表型、元组型等任何类型的对象
Python支持一个函数返回多个结果。返回的多个值的return语句格式如下:
return[表达式1|值1],[表达式2|值2],....,[表达式3|值3]
注意:
(1)实际返回的多个值是一个元组 #(tuple)
(2)返回一个tuple可以省略括号
(3)可以使用多个变量同时接受一个tuple,按位置赋给对应的值
例5.1.4变量作用域
在Python中,模块(module)、类(class)以及函数(def、lambda)会引入新的作用域,而其他代码块(如if、try、for等)不会引入新的作用域,即定义在这些代码块之内的变量还是可以被访问的。
所有的变量根据作用域可以分为4种:@1L:local,局部作用域,即函数中定义的变量;@2E:enclosing,嵌套的父级函数的局部作用域,即包含次函数的上级函数的局部作用域,但不是全局的;@3G:global,全局变量,就是模块级别定义的变量;@4B:built-in,系统固定模块里面的变量,比如int、bytearray等
@1局部变量
注意:
(1)一个在def内定义的变量名能够被def内的代码使用。不能再函数的外部引用这样的变量名。
(2)def之中的变量名与def之外的变量名并不冲突。一个在def之外被赋值的变量X,与这个在def之中赋值的变量X是完全不同的。
@2全局变量
每个模块都是一个全局作用域。因此,创建于模块文件顶层的变量具有全局作用域。对于外部访问,就成了一个模块对象的属性。全局作用域的作用范围仅限于单个文件。"全局"指的是在一个文件顶层的变量名,对于这个文件而言是全局的。
【例5-8】全局变量应用。
fruit = ['apple', 'pear']
fruit1 = ['apple', 'pp']
def f1():
fruit.append('banana')
print('fruit.qppend = {}'.format(fruit)) #这个可以更改局部变量
global fruit #声明:fruit是全局变量,更改的就是全局变量fruit
fruit = 'banana' #将全局变量fruit进行赋值
print('global fruit is {}'.format(fruit)) #结果是banana
fruit1 = ['banana'] #此部分是对def中的局部变量fruit1进行赋值
print(fruit1) #输出结果也是def作用域中的局部变量fruit1
f1()
print('*'*10)
print(fruit) #此部分函数的作用域是在全局变量中,因此此print为banana
print(fruit1) #此部分函数的作用域是在全局变量中,函数f1()中执行的fruit1只是局部变量,
并没有被赋值,所以输出仍为'apple','pp'
注意:
(1)全局变量是位于模块内部的顶层的变量名。
(2)全局变量如果是在函数内部赋值,必须经过声明。
(3)全局变量在函数内部不经过声明也可以使用。
@3变量名查找原则
Python的变量名解析机制也成为LEGB法则,具体说明如下:当在函数使用未确认的变量名时,Python搜索4个作用域:@1本地作用域(Local);@2上一层嵌套结构中def或者lambda的本地作用域(Enclosing);@3全局作用域(Global);@4内置作用域(Built-in)。按上述查找原则,在第一处找到的地方停止。如果没有找到,Python报错。
【例】
x = int(10) #Python 内置作用域 B
y = 2 当前模块的全局变量 G
def outfunction():
outfx = 2 #外层作用域 E
def infunction():
infx = 1 #局部作用域 L5.1.5 匿名函数
在临时需要一个函数而且功能非常简单的情况下,可以使用Python提供的匿名函数定义来完成。
Python允许快速定义单行的不需要函数名字的最小函数,称为lambda()函数。它是从Lisp()语言借来的,可以用在任何需要函数得地方。
lambda()函数定义格式如下:
lambda 参数1,参数2,...:表达式
功能:lambda是一个表达式,而不是一个语句。作为一个表达式,lambda返回一个值,把结果赋值给一个变量名。
【例】
import os,random
def setQuestion():
opr = {1:'+',2:'-',3:'*',4:'/'}
num1 = random.randint(1,100)
num2 = random.randint(1,4)
#print('typr is{}'.format(type(num2)))
opnum = random.randint(1,4)
op = opr[opnum]
result = {
'+':lambda x,y:x+y,
'-':lambda x,y:x-y,
'*':lambda x,y:x*y,
'/':lambda x,y:x/y
}[op](num1,num2)
result_tuple = (num1,op,num2,result)
return result_tuple
print(setQuestion())5.1.6高阶函数
在Python中,函数可以赋值给一个变量名,并且可以通过这个变量名调用函数。函数的参数可以是任何变量类型,因此这个变量也可以作为函数的参数
f1 =lambda x :[i for i in range(1,x+1) if x%i == 0] #这部分见上对for函数的讲解
def commonFactor(n1, n2, f):
return set(f(n1))&set(f(n2))
out = commonFactor(6,16,f1)
print(out)
内置高阶函数
函数格式 功能说明
map()
filter()
reduce()
sorted()【例】筛选素数
筛选素数的一个方法就是埃氏筛选法
(1)首先,列出从2开始的所有自然数,构造一个序列;
(2)然后,把序列中2的倍数刷掉
(3)然后,取新序列的第一个数3,它一定是素数,在把散的倍数刷掉5.1.7函数的嵌套
def aFunc(a):
def bFunc(b):
return a**b
return bFunc5.1.8递归函数
1、递归的概念
递归就是子程序(或函数)直接调用自己,或通过一系列调用语句间接调用自己。它是一种描述问题和解决问题的基本方法。递归通常用来解决结构相似的问题
2、递归函数定义
def 递归函数名(参数表):
if 递归出口条件:
return 返回值 1
else:
return 递归函数名(实参表)
【例】阶乘n!
def jiechengFun(n):
if n == 0:
return 1
else:
return n*jiechengFun(n-1)5.2 模块
Python应用程序是由一系列模块组成,每个PY文件就是一个模块,每个模块也是一个独立的命名空间。以此,允许在不同模块定义相同的变量名而不发生冲突。
模块的概念类似于C语言的lib库。如果要使用模块中的函数或者其他对象,必须要导入模块才可以
为避免模块名冲突,Python引入了按目录来组织模块的方法,称为包(Package)。
5.2.1模块的创建
以py作为扩展名进行保存的文件,都认为是Python的一个模块。本书之前所有的任务程序都是一个Python模块
注意:
(1)每个模块都有一个__name__属性,当其值为__main__时,表明该模块自身在运行,否则被引入。
(2)可以通过__name__属性的判断,来使程序仅在模块自身运行时执行。
#本部分是模块一的内容
print(__name__)
def func(a,b):
return a**b
if(__name__ == '__main__'):
import sys
print('sys.argv[0] = {0}'.format(sys.argv[0]))
#python module_1.py 5 2
print('sys.argv[1]={0},sys.argv[2]={1}'.format(sys.argv[1],sys.argv[2]))
a = int(sys.argv[1])
b = int(sys.argv[2])
print(func(a,b))
else:
print('This is module_1')
#本部分是模块二的内容
import test11 as test111
print(test111.JieChengFunc(4))
5.2.2导入模块
通常,模块为一个文件,可以导入后使用。可以作为模块的文件类型有:.py.pyo.pyc.pyd.so.dll
Python中有三种导入模块的方法
1、import 语句导入
模块导入的格式:
import 模块名[,模块名1,模块名2,...,模块名n]功能:导入模块后,就可以引用其任何公共的函数、类或者属性。
2、from-import语句导入
模块的导入语法格式:
from 模块名 import *|[对象名,对象名1,....]
功能:导入指定的函数和模块变量。如果在import之后使用*,则任何只要不是以“_”开始的对象都会被导入
注意:
(1)这种导入方式是将导入的对象直接导入到本地的命名空间,以此在访问这些对象时不需要添加模块名
(2)如果考虑冲突问题,必须使用import-as模块语句来避免冲突 :import 模块名字 as 自定义小写名称
(3)尽量减少from-import*的使用,不利于调试
3、内建函数__import__()导入:
模块导入语法格式:
变量名 = __import__('模块名')
【例】之前的模块导入
test111 = __import__('test11')
print(test111.JieChengFunc(4))
4、Python模块搜索路径
Python在导入一个模块时,执行流程如下所述。
(1)创建一个初始值为空的模块对象。
(2)把该模块对象追加到sys.module对象中
(3)装载模块中的代码,必要时执行编译操作
事实上,上述搜索路径都包含在sys.path中。可以很方便地通过sys.path.append(新路径)
5.2.3 包
包是一个有层次的文件目录结构。每个模块对应文件,而包对应一个目录。使用标准的import和from-import语句可以导入包中的模块。
包目录下的第一个文件是__init__.py,之后是一些模块文件和子目录。假如子目录中也有__init__.py,那么是这个包的子包。
当把一个包作为模块导入时,实际上导入的是__init__.py文件。__init__.py文件中定义了包的属性和方法,也可以是一个空文件,但是必须存在。
#6文件
到目前为止,程序中所有要输入的数据都是从键盘输入,程序运行结果输出到显示器,所有输入和输出结果都无法永久保留。Python中的文件机制,使得程序的输入输出与存储器中的文件相关联。
6.1.1文件的打开和关闭
在Python中访问文件,必须首先使用内置方法open()打开文件,创建文件对象,再利用文件对象执行读写操作。
一旦创立文件对象,该对象便会记住文件的当前位置,以便执行读写操作。这个位置称为文件的指针。凡是以r、r+、rb+的读文件方式,或者以w、w+、wb+的写文件方式打开文件的文件,初始时,文件均指向文件的头部。
@1内置方法 open()
open()的语法格式如下:
fileObject.open(file_name[,access_mode[,buffering]])
功能:打开一个文件并返回文件对象。如果文件不能打开,抛出异常OSError
参数说明:
(1)file_name变量是要访问的文件名。文件所在的路径可以使用绝对路径或者相对路径。
(2)access_mode是打开文件的模式,可以是只读、写入、追加等。此参数是可选的,默认文件访问模式为只读(r),其他模式见表
(3)buffering表示缓冲区的策略选择。若为0,不使用缓冲区,直接读写,仅在二进制模式下有效
模式 描述
r 只读方式打开一个文件
rb 二进制方式打开一个只读文件
r+ 打开一个以存在的文件用于读写
w 打开文件进行写入,如果文件已经存在,将其覆盖;如果文件不存在,创建新文件
wb 以二进制打开一个文件用于写入。若已存在,将其覆盖;不存在,创建
W+ 用于读写,,,
wb+ 用于读写,,,
a 这个会指向内容的尾指针进行写操作
ab
a+
ab+
文件对象的相关属性
属性 描述
closed 如果文件已被关闭,返回True,否则返回False
mode 返回被打开文件的访问模式
name 返回文件名称
softspace
encoding 返回文件编码
newlines 返回文件用到的换行模式,是一个元组对象
【例】
import os
myfile = open("/home/pi/Code/Python/exercises/test2.py",'r+') #绝对路径使用没问题
print('wenjainming:{}' .format(myfile.name))
print('wenjainming:{}' .format(myfile.mode))
print('wenjainming:{}' .format(myfile.closed)) #False
print('wenjainming:{}' .format(myfile.encoding))
myfile.close()
print('wenjainming:{}' .format(myfile.closed)) #False6.1.2读文件
Python可以读取文本文件或二进制文件
1、read()
语法格式:
fileObject.read([count])
count参数是要读取的字节数大小,如果没有传入count,则尽可能读取更多的内容
2、readline()
fileObject.readlines([count])
把文件的每一行作为一个list的成员,并返回该listimport os
myfile = open("/home/pi/Code/Python/exercises/test2.py",'r+')
print('wenjainming:{}' .format(myfile.name))
print('wenjainming:{}' .format(myfile.mode))
print('wenjainming:{}' .format(myfile.closed))
print('wenjainming:{}' .format(myfile.encoding))
print('wenjainming:{}' .format(myfile.closed))
text = myfile.read()
print(text)
myfile.close()
myfile1 = open("/home/pi/Code/Python/exercises/Test3.py",'r+')
text = myfile1.read()
print(text)
myfile1.close()
6.1.3写文件
@1 write()方法
语法格式:
fileObject.write(str)
功能:把str写到文件中。write()并不会在str后面加上一个换行符。
参数说明:参数str是一个字符串,是要写入文件的内容。
@2 writelines()
fileObject.writelines(seq)
功能:把seq的内容全部写到文件中,而且不会在字符串的结尾添加换行符('\n')
@3 flush()方法
语法格式:
fileObject.flush()
功能:把缓冲区的内容写入硬盘
6.1.4文件的其他操作
Python的os模块提供了执行了文件处理操作的方法,比如重命名和删除文件。要是用这个模块,必须先导入它,然后才可以调用相关的功能。
@1 重命名文件
rename()方法语法格式:
os.name(oldname, newname)
@2 删除文件
remove()
os.remove(filename)
参数说明:filename是要删除的文件名
@3 清空文件
truncate()方法格式:
fileObject.truncate()
功能:清空文件对象所值文件的内容6.1.5pickle模块
此模块实现了基本的数据序列化和反序列化的功能,使用pickle模块,需要从二进制方式读写文件
1、dump()
语法格式:
pickle.dump(obj,file,[,protol])
功能:将对象obj保存在文件file中
2、load()方法:
语法格式:
pickle.load(file)
功能:从file文件中读取一个字符串,并将它重构为原来的read()和readline()接口
6.2目录操作
6.2.1目录与文件操作函数
文件是由操作系统来管理的,并通过文件夹的方式的来管理大量的文件。文件除了读写操作以外,还可以进行复制、移动、删除等操作。Python中对文件、文件夹进行操作时,可以使用os模块或shutil模块
os模块中常用的方法
方法 功能描述
os.getcwd() 得到当前目录,即当前Python脚本工作的目录路径
os.listdir(path)
os.remove(filename)
os.removedirs(path)
os.rename(oldname,newname)
os.exit() 终止当前进程
6.2.2目录的遍历
@1 使用os.popen(command,[,mode[,bufsize]])
6.3CSV文件
CSV文件由任意数目的记录组成,记录见以某种换行符间隔;每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。
如下是一个CSV文件。
101,张华,女,1994-03-21,18910011231,[email protected]
102,黎明,男,1995-05021,13710023245,[email protected]
6.3.2CSV文件的访问
CSV模块时Python的内置模块,用import语句导入后就可以使用。
1、reader()
csv.reader(csvfile,dialect = 'excel',**fmtparams)
参数说明:
(1)csvfile:必须是支持迭代的对象,可以是文件(file)对象或者列表(list)
(2)dialect 编码风格,默认是excel风格,用逗号","分隔。
(3)fmtparams 格式化参数
2、writer()方法
语法格式:
csv.writer(csvfile,dialect = 'excel',**fmtparams)
功能:写入CSV文件。
3、register_dialect()
功能:用来定义编码风格。
参数说明:
(1)name 定义编码风格的名字,默认是'excel',可以定义成'myexcel'
(2)[dialect,] **fmtparams 编码风格格式参数,如分隔符(默认是逗号)或引号
4、unregister_dialect()方法
语法格式:
csv.unregister_dialect(name)
功能:用于注销自定义的编码风格
参数说明:name为自定义编码风格的名字
例程中结果如下:

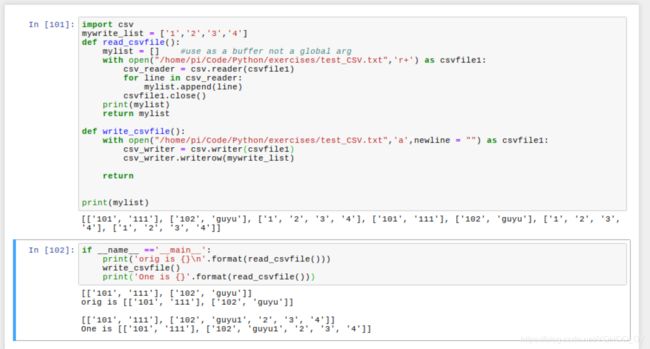
具体例程内容见下:
import csv
mywrite_list = ['1','2','3','4']
def read_csvfile():
mylist = [] #use as a buffer not a global arg
with open("/home/pi/Code/Python/exercises/test_CSV.txt",'r+') as csvfile1:
csv_reader = csv.reader(csvfile1)
for line in csv_reader:
mylist.append(line)
csvfile1.close()
print(mylist)
return mylist
def write_csvfile():
with open("/home/pi/Code/Python/exercises/test_CSV.txt",'a',newline = "") as csvfile1:
csv_writer = csv.writer(csvfile1)
csv_writer.writerow(mywrite_list)
return
print(mylist)
if __name__ =='__main__':
print('orig is {}\n'.format(read_csvfile()))
write_csvfile()
print('One is {}'.format(read_csvfile()))6.3.3Excel文件与CSV文件
CSV文件是文本形式的表格文件,Excel是备受欢迎的专业电子表格处理软件。很多表格是以Excel方式存储的。Python中可以直接导入其他相关库来操作Excel文件。这里使用xlrd模块和xlwt模块。