大数据实操篇 No.3-Hadoop HA高可用集群搭建
第1章 hadoop 高可用介绍
Hadoop高可用,除了数据存储的多副本机制之外,就是 Namenode和Resourcemanager的高可用。
在Hadoop2.0之前,Namenode只有一个,存在单点问题(虽然Hadoop1.0有SecondaryNamenode,CheckPointNode,BackupNode这些,但是单点问题依然存在),在Hadoop2.0引入了HA机制。Hadoop2.0的HA机制官方介绍了有2种方式,一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。
启动了Hadoop2.0的HA机制之后,SecondaryNameNode,CheckpointNode,BackupNode这些都不需要了。
Namenode的高可用依赖于:
JournalNode负责数据交换
ZKFailoverController(又简称为ZKFC),内部会启动HealthMonitor和ActiveStandbyElector组件;HealthMonito做Namenode的健康状态检测;ActiveStandbyElector负责和zookeeper连接做主备选举。
Resourcemanager高可用依赖于:
Resourcemanager内部的主备选择器,连接Zookeeper做主备选举。
第2章 集群规划
Zookeeper集群(笔者zookeeper是单独的集群,不和hadoop放在一起)
|
|
Zookeeper110 |
Zookeeper111 |
Zookeeper112 |
| QuorumPeerMain |
√ |
√ |
√ |
Hadoop集群
|
|
Hadoop100 |
Hadoop101 |
Hadoop102 |
| NameNode |
√ |
√ |
|
| DataNode |
√ |
√ |
√ |
| DFSZKFailoverController |
√ |
√ |
|
| JournalNode |
√ |
√ |
√ |
| ResourceManager |
|
√ |
√ |
| NodeManager |
√ |
√ |
√ |
第3章 集群部署
3.1 修改配置文件
3.1.1 修改core-site.xml
fs.defaultFS
hdfs://jed/
hadoop.tmp.dir
/opt/module/hadoop-3.1.2/data/tmp
ha.zookeeper.quorum
zookeeper110:2181,zookeeper111:2181,zookeeper112:2181
ipc.client.connect.max.retries
100
Indicates the number of retries a client will make to establisha server connection.
3.1.2 修改hdfs-site.xml
dfs.replication
3
dfs.nameservices
jed
dfs.ha.namenodes.jed
nn1,nn2
dfs.namenode.rpc-address.jed.nn1
hadoop100:9000
dfs.namenode.http-address.jed.nn1
hadoop100:50070
dfs.namenode.rpc-address.jed.nn2
hadoop101:9000
dfs.namenode.http-address.jed.nn2
hadoop101:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop100:8485;hadoop101:8485;hadoop102:8485/jed
dfs.journalnode.edits.dir
/opt/module/hadoop-3.1.2/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.jed
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/zihao/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
3.1.3 修改mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
mapreduce.jobhistory.address
hadoop102:10020
mapreduce.jobhistory.webapp.address
hadoop102:19888
mapreduce.map.memory.mb
512
mapreduce.map.java.opts
-Xmx512M
mapreduce.reduce.memory.mb
512
mapreduce.reduce.java.opts
-Xmx512M
3.1.4 修改yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
haoyarn
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop101
yarn.resourcemanager.hostname.rm2
hadoop102
yarn.resourcemanager.webapp.address.rm1
hadoop101:8088
yarn.resourcemanager.webapp.address.rm2
hadoop102:8088
yarn.resourcemanager.zk-address
zookeeper110:2181,zookeeper111:2181,zookeeper112:2181
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
3.2 初始化
3.2.1 格式化namenode
格式化hadoop100上的namenode,在namenode节点上操作(生产环境不要随便执行,很危险,格式化后,数据不客恢复)
$ hadoop namenode -format3.2.2 同步namenode元数据
同步namenode元数据到另一个nanenode节点(hadoop102)
$ scp -r /opt/module/hadoop-3.1.2/data/tmp hadoop101: /opt/module/hadoop-3.1.2/data/tmp或者直接用分发脚本分发
$ xsync /opt/module/adoop-3.1.2/data/tmp也可以在standby节点上主动同步
$ hadoop namenode -bootstrapStandby3.2.3 格式化DFSZKFailoverController (ZKFC)
任选一个namenode执行
$ hdfs zkfc -formatZK3.3 启动集群
3.3.1 先启动zookeeper集群
Namenode和Resourcemanager的高可用都依赖于zookeeper做主备切换,所以必须先启动zookeeper集群
3.3.2 启动JournalNode
可在每台hadoop机器上单独启动journalnode,也可绕过此步,直接启动hdfs(默认启动所有节点的Journalnode)
$ sbin/hadoop-daemon.sh start journalnode启动后进程
7311 JournalNode3.3.3 启动hdfs
[zihao@hadoop100 hadoop-3.1.2]$ sbin/start-dfs.sh
Starting namenodes on [hadoop100 hadoop101]
Starting datanodes
Starting journal nodes [hadoop100 hadoop101 hadoop102]
Starting ZK Failover Controllers on NN hosts [hadoop100 hadoop101]3.3.4启动yarn
[zihao@hadoop101 hadoop-3.1.2]$ sbin/start-yarn.sh
Starting resourcemanagers on [ hadoop101 hadoop102]
Starting nodemanagers在hadoop102上启动历史服务
$ sbin/mr-jobhistory-daemon.sh start historyserver*可以自己写一个统一脚本做群起
第4章 检查高可用各进程运行情况
4.1运行进程
[zihao@zookeeper110 apache-zookeeper-3.5.7-bin]$ xsh jps
-----------zookeeper110-----------
7415 QuorumPeerMain
7643 Jps
-----------zookeeper111-----------
7231 QuorumPeerMain
7391 Jps
-----------zookeeper112-----------
7160 QuorumPeerMain
7279 Jps
-----------hadoop100-----------
14690 NodeManager
18309 NameNode
18440 DataNode
18888 DFSZKFailoverController
18666 JournalNode
18942 Jps
-----------hadoop101-----------
13712 DataNode
13618 NameNode
11621 NodeManager
11494 ResourceManager
13977 DFSZKFailoverController
14011 Jps
13820 JournalNode
-----------hadoop102-----------
10544 DataNode
10711 Jps
9256 ResourceManager
9356 NodeManager
10652 JournalNode4.2 打开web界面
hdfs的namenode,一个为active,另一个为standby


yarn的resourcemanager,一个为active,另一个为standby
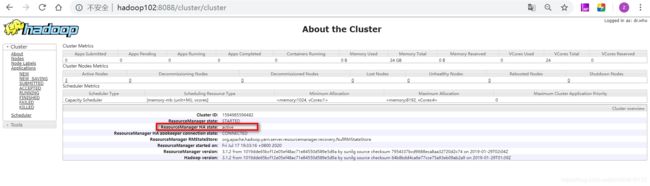

当active节点发生故障时,standby节点会立即被切换为active,可自己kill进程检查,到web界面上观察,或到zookeeper下节点查看节点状态。