filebeat+kafka+Flink+ElasticSearch+springboot+高德地图热力图项目
原文地址 https://www.jianshu.com/p/c148bf91c3ac
2019.05.26
由于近期在研究ELK和最新的实时计算框架Flink,所以把以前热力图项目flume+kafka+SparkStreaming+mysql+ssm+高德地图热力图项目换组件重构一下。效果不会变好,可能更麻烦,性能更低,纯属应用一下最近研究的新组件和新计算框架。
项目环境:
filebeat 6.2.0
kafka 0.8.2
Flink 1.6.1
ElasticSearch 6.4.0
springboot 2.1.5
scala 2.11
项目顺序:
1.python写个脚本模拟下数据。正常情况的真实数据是,我们每个人的手机会不停发送你的经纬度,比如你坐火车到别的省份会收到一条短信,例如:山东省济南市欢迎您。就是这个道理。
import random
import time
phone = [
"13869555210",
"18542360152",
"15422556663",
"18852487210",
"13993584664",
"18754366522",
"15222436542",
"13369568452",
"13893556666",
"15366698558"
]
location = [
"123.449169, 41.740567",
"123.450169, 41.740705",
"123.451169, 41.741405",
"123.452169, 41.741805",
"123.453654, 41.742405",
"123.454654, 41.742805",
"123.455654, 41.743405",
"123.458654, 41.743705"
]
def sample_phone():
return random.sample(phone, 1)[0]
def sample_location():
return random.sample(location, 1)[0]
def generator_log(count=10):
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
f = open("/var/log/lyh.log", "a+")
while count >= 1:
query_log = "{phone}\t{location}\t{date}".format(phone=sample_phone(), location=sample_location(),
date=time_str)
f.write(query_log + "\n")
# print query_log
count = count - 1
if __name__ == '__main__':
while True:
generator_log(100)
time.sleep(5)
把代码上传到linux环境运行,脚本功能向/var/log/lyh.log文件内 每隔5秒随即生成100条数据。内容就是电话号码+经纬度+时间,后期用Flink实时处理时候需要拿到经纬度信息。
2.用filebeat组件抓取/var/log/lyh.log文件中不停增加的数据,然后输出到kafka中
filebeat是ELK日志收集系统体系里抓取日志的插件,我们这里为了应用一下用他来抓取我们上面Python脚本生成的数据。
修改filebeat.yml配置文件,配置监控抓取信息的文件,和输出的位置
filebeat.prospectors:
- type: log #抓取信息后以log格式json字符串输出
paths:
- /var/log/lyh.log #监控抓取数据的文件
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#如果不适用logstash对日志进行过滤,也可以直接输出到es
#output.elasticsearch:
# hosts: ["172.24.112.17:9200"]
# #输出到kafka
output.kafka:
hosts: ["hadoop1:9092", "hadoop2:9092", "hadoop3:9092"]
topic: 'log'
注意:filebeat和kafka的版本一定要兼容否者报错,具体哪个版本之间互相兼容参考官方文档https://www.elastic.co/guide/en/beats/filebeat/6.4/kafka-output.html
启动filebeat命令
sudo -u elk ./filebeat -e -c filebeat.yml -d "publish"
3.编写Flink代码。从kafka消费数据,清洗数据拿到自己要的数据,存入到ElasticSearch中
pom依赖:
junit
junit
4.11
test
org.scala-lang
scala-library
2.11.8
org.apache.flink
flink-core
1.6.1
org.apache.flink
flink-clients_2.11
1.6.1
org.apache.flink
flink-scala_2.11
1.6.1
org.apache.flink
flink-streaming-scala_2.11
1.6.1
org.apache.flink
flink-connector-kafka-0.8_2.11
1.6.1
log4j
log4j
1.2.17
com.alibaba
fastjson
1.2.36
org.apache.flink
flink-connector-elasticsearch6_2.11
1.6.1
Flink代码:
import java.text.SimpleDateFormat
import java.util.{Date, Properties}
import com.alibaba.fastjson.JSON
import org.apache.flink.streaming.connectors.kafka._
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink
import org.apache.http.HttpHost
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.Requests
object Flink_kafka {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 非常关键,一定要设置启动检查点!!
env.enableCheckpointing(5000)
//配置kafka信息
val props = new Properties()
props.setProperty("bootstrap.servers", "192.168.199.128:9092,192.168.199.131:9092,192.168.199.132:9092")
props.setProperty("zookeeper.connect", "192.168.199.128:2181,192.168.199.131:2181,192.168.199.132:2181")
props.setProperty("group.id", "test")
//读取数据,第一个参数是kafka的topic,也就是上面filebeat配置文件里面设定的topic叫log
val consumer = new FlinkKafkaConsumer08[String]("log", new SimpleStringSchema(), props)
//设置只读取最新数据
consumer.setStartFromLatest()
//添加kafka为数据源
//18542360152 116.410588, 39.880172 2019-05-24 23:43:38
val stream = env.addSource(consumer).map(
x=>{
JSON.parseObject(x)
}
).map(x=>{
x.getString("message")
}).map(x=>{
val jingwei=x.split("\\t")(1)
val wei=jingwei.split(",")(0).trim
val jing=jingwei.split(",")(1).trim
//调一下时间格式,es里面存储时间默认是UTC格式日期,+0800是设置成北京时区
val sdf=new SimpleDateFormat("yyyy-MM-dd\'T\'HH:mm:ss.SSS+0800")
val time=sdf.format(new Date())
val resultStr=wei+","+jing+","+time
resultStr
})
stream.print() //数据清洗以后是这种样子 123.450169,41.740705,2019-05-26T19:03:59.281+0800
//把清洗好的数据存入es中,数据入库
val httpHosts = new java.util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("192.168.199.128", 9200, "http"))//es的client通过http请求连接到es进行增删改查操作
val esSinkBuilder = new ElasticsearchSink.Builder[String](
httpHosts,
new ElasticsearchSinkFunction[String]{ //参数element就是上面清洗好的数据格式
def createIndexRequest(element: String):IndexRequest={
val json = new java.util.HashMap[String, String]
json.put("wei", element.split(",")(0))
json.put("jing", element.split(",")(1))
json.put("time", element.split(",")(2))
return Requests.indexRequest()
.index("location-index")
.`type`("location")
.source(json)
}
override def process(element: String, runtimeContext: RuntimeContext, requestIndexer: RequestIndexer): Unit = {
requestIndexer.add(createIndexRequest(element))
}
}
)
//批量请求的配置;这将指示接收器在每个元素之后发出请求,否则将对它们进行缓冲。
esSinkBuilder.setBulkFlushMaxActions(1)
stream.addSink(esSinkBuilder.build())
env.execute("Kafka_Flink")
}
}
注意:ES存储时间时候的格式和时区问题
elasticsearch原生支持date类型,json格式通过字符来表示date类型。
所以在用json提交日期至elasticsearch的时候,es会隐式转换,把es认为是date类型的字符串直接转为date类型。
date类型是包含时区信息的,如果我们没有在json代表日期的字符串中显式指定时区,对es来说没什么问题,
但是如果通过kibana显示es里的数据时,就会出现问题,数据的时间会晚8个小时。
kibana在通过浏览器展示的时候,会通过js获取当前客户端机器所在的时区,也就是东八区,所以kibana会把从es得到的日期数据减去8小时。
最佳实践方案就是:往es提交日期数据时,直接提交带有时区信息的日期字符串,
如:“2016-07-15T12:58:17.136+0800”。 这个是世界协调时间(UTC)格式-es默认支持的格式
java格式化:
String FULL_FORMAT="yyyy-MM-dd\'T\'HH:mm:ss.SSS+0800";
Date now=new Date();
new SimpleDateFormat(FULL_FORMAT).format(now)
4.目前数据已经入库,用springboot创建一个web项目,从es里查出数据,在前台高德热力图组件里动态展示
整个web项目的pom依赖:
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-tomcat
provided
org.springframework.boot
spring-boot-starter-test
test
javax.servlet
jstl
org.apache.tomcat.embed
tomcat-embed-jasper
org.elasticsearch.client
elasticsearch-rest-high-level-client
6.4.3
org.apache.logging.log4j
log4j-core
2.11.1
com.alibaba
fastjson
1.2.36
4.1我们要从es中查出距离当前时间20秒以内的所有数据,并且按经纬度聚合统计数量。
es的查询语句:
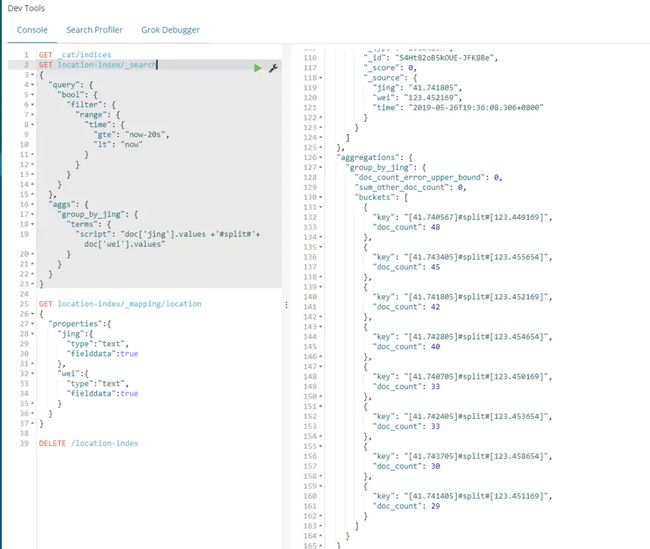
QQ截图20190526193643.png
使用聚合查询之前要先设置一下mapping,把jing和wei的属性fielddata设置成true,默认是false。不改成true进行聚会查询会报错。
上面语句是先查出距离当前时间20秒内的所有数据,然后根据jing和wei数据进行聚合也就是sql里的group by,聚会以后统计总数。意思就是当前经纬度内的总人数,数越大代表该区域人越多。
web代码里面我们要把上述查询语句通过es的api换成java代码实现。
先创建一个Location实体类,来存放查询出来的数据,总数,经度,纬度。
public class Location {
private Integer count;
private double wei;
private double jing;
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public double getWei() {
return wei;
}
public void setWei(double wei) {
this.wei = wei;
}
public double getJing() {
return jing;
}
public void setJing(double jing) {
this.jing = jing;
}
}
写一个es的工具类,创建和es连接的client,一些基本增删改查方法,以及上面查询语句的java代码实现
import com.test.flink_web_show.controller.Location;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.script.ScriptType;
import org.elasticsearch.script.mustache.SearchTemplateRequest;
import org.elasticsearch.script.mustache.SearchTemplateResponse;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class RestClientUtils {
private RestHighLevelClient client = null;
public RestClientUtils() {
if (client == null){
synchronized (RestHighLevelClient.class){
if (client == null){
client = getClient();
}
}
}
}
private RestHighLevelClient getClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.199.128", 9200, "http"),
new HttpHost("192.168.199.128", 9201, "http")));
return client;
}
public void closeClient(){
try {
if (client != null){
client.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/*------------------------------------------------ search Api 多条件查询 start ----------------------------------------------*/
/**
* 查询模板
* @throws Exception
*/
public List searchTemplate(String indexName, String JsonStr, Map scriptParams) throws Exception{
//Inline Templates
SearchTemplateRequest request = new SearchTemplateRequest();
request.setRequest(new SearchRequest(indexName));
request.setScriptType(ScriptType.INLINE);
request.setScript(JsonStr);
request.setScriptParams(scriptParams);
//Synchronous Execution
SearchTemplateResponse response = client.searchTemplate(request, RequestOptions.DEFAULT);
//SearchTemplate Response
SearchResponse searchResponse = response.getResponse();
//Retrieving SearchHits 获取结果数据
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
float maxScore = hits.getMaxScore();
System.out.println("totalHits: " + totalHits);
System.out.println("maxScore: " + maxScore);
System.out.println("------------------------------------------");
SearchHit[] searchHits = hits.getHits();
/*for (SearchHit hit : searchHits) {
// do something with the SearchHit
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
System.out.println("index: " + index);
System.out.println("type: " + type);
System.out.println("id: " + id);
System.out.println("score: " + score);
System.out.println(sourceAsString);
System.out.println("------------------------------------------");
}*/
//得到aggregations下内容
ArrayList locations = new ArrayList<>();
Aggregations aggregations = searchResponse.getAggregations();
if(aggregations!=null){
Map aggregationMap = aggregations.getAsMap();
Terms companyAggregation = (Terms) aggregationMap.get("group_by_jing");
List buckets = companyAggregation.getBuckets();
for(Terms.Bucket bk:buckets){
Location location = new Location();
Object key = bk.getKey();
long docCount = bk.getDocCount();
System.out.println("key: "+key.toString());
System.out.println("doc_count: "+docCount);
String jingdu = key.toString().split("#split#")[0];
String substring_jing = jingdu.substring(1, jingdu.length() - 1);
location.setJing(Double.parseDouble(substring_jing));
String weidu = key.toString().split("#split#")[1];
String substring_wei = weidu.substring(1, weidu.length() - 1);
location.setWei(Double.parseDouble(substring_wei));
location.setCount((int)docCount);
locations.add(location);
}
}
return locations;
}
}
es的java api比较复杂具体参考我的另一篇简书ElasticSearch java API
Controller代码:
import com.alibaba.fastjson.JSON;
import com.test.flink_web_show.es_utils.RestClientUtils;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletResponse;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Controller
public class HomeController {
@RequestMapping("/")
public ModelAndView home()
{
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("index");
return modelAndView;
}
@RequestMapping("/get_map")
public void getMap(HttpServletResponse response) throws Exception{
RestClientUtils restClientUtils = new RestClientUtils();
String searchJSON="{\n" +
" \"query\": {\n" +
" \"bool\": {\n" +
" \"filter\": {\n" +
" \"range\": {\n" +
" \"{{time}}\": {\n" +
" \"{{gte}}\": \"{{value1}}\", \n" +
" \"{{lt}}\": \"{{now}}\"\n" +
" }\n" +
" }\n" +
" }\n" +
" }\n" +
" },\n" +
" \"aggs\": {\n" +
" \"{{group_by_jing}}\": {\n" +
" \"terms\": {\n" +
" \"script\": \"{{doc['jing'].values +'#split#'+ doc['wei'].values}}\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
Map map = new HashMap<>();
map.put("time","time");
map.put("gte","gte");
map.put("value1","now-20s");
map.put("lt","lt");
map.put("now","now");
map.put("group_by_jing","group_by_jing");
map.put("doc['jing'].values +'#split#'+ doc['wei'].values","doc['jing'].values +'#split#'+ doc['wei'].values");
List locations = restClientUtils.searchTemplate("location-index", searchJSON, map);
restClientUtils.closeClient();
String json = JSON.toJSONString(locations);
response.getWriter().print(json);
}
}
前台jsp代码:
<%--
Created by IntelliJ IDEA.
User: ttc
Date: 2018/7/6
Time: 14:06
To change this template use File | Settings | File Templates.
--%>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
高德地图
上述为全部代码部分
按顺序启动项目全部流程
启动zookeeper
zkServer.sh start
启动kafka
bin/kafka-server-start.sh config/server.properties
启动es
sudo -u elk bin/elasticsearch
启动filebeat
sudo -u elk ./filebeat -e -c filebeat.yml -d "publish"
启动Python脚本生成模拟数据
python phoneData_every5second.py
启动Flink项目,实时接收并处理数据存入到es
启动web项目完成动态地图展示
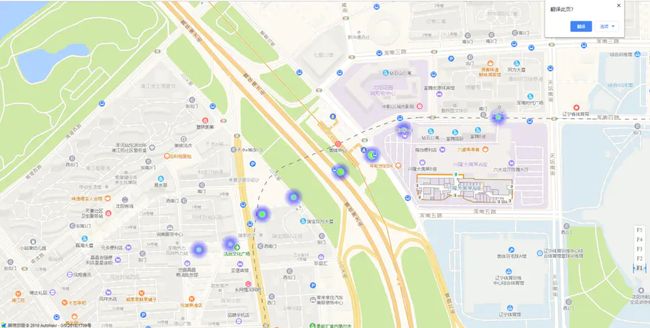
QQ截图20190526201432.png
不会截取gif动图,数据模拟也不是很好,图中的热力图圆圈颜色会根据模拟数据一直不停变化。
作者:__元昊__
链接:https://www.jianshu.com/p/c148bf91c3ac
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。