内部专家亲自揭秘!滴滴对象存储系统的演进之路
本文根据汪黎老师于第十届中国系统架构师大会(SACC 2018)的现场演讲《滴滴对象存储系统的架构演进实践》内容整理而成。
讲师介绍:

汪黎,博士,中国计算机学会存储专委委员,曾获中国计算机学会优秀博士论文、首届中国开源软件竞赛银奖等奖励。主要研发领域为文件系统、操作系统、分布式存储,为知名开源项目LVS、Ceph成员。曾任国防科技大学计算机学院副研究员,教研室主任,天河云存储研发负责人;现担任滴滴出行高级技术专家,滴滴云存储研发负责人。
正文:
大家好,我分享的题目是《滴滴对象存储系统的架构演进实践》。
首先,什么是对象存储系统?当前对象存储系统这个概念稍微有一点混淆。一般有两种定义方式:一种是通过存储系统本身的技术实现路线来将其定义为对象存储系统。比如经典的、在高性能计算常用的Lustre文件系统,它的后端就是一个典型的对象存储设计思想。现在非常流行的Ceph,它的后端RADOS也是对象存储的架构。另外一个定义方式,是从存储系统的应用场景来定义的——即某个存储系统适用于对象存储这个场景。而今天我想交流的,就是基于第二种定义方式的对象存储系统。
那么,对象存储的应用场景有什么特点?它一般存储的都是静态的、非结构化的数据,比较典型的有图片、音视频、网站的静态资源,还包括一些比如虚拟机的镜像,快照,以及备份数据等等。这样的数据,普遍具有一次写、不修改、多次读、较少删除的访问特点。另外,数据对外访问接口一般是通过HTTP的接口来访问,对延时的要求并不太高。但对象存储系统对海量数据存储要求是很高的,另外对数据可靠性的要求也很高。
滴滴对象存储系统GIFT V1.0
滴滴的对象存储系统,内部称为GIFT,是为了解决公司小文件存储问题而开发的对象存储系统,比如图片、网页静态资源等。 访问的方式为http://
这里简单介绍一下Facebook Haystack,这是一个比较经典的对象存储系统。Haystack是Facebook用于存储图片等小文件的对象存储系统,其核心思想是采用多对一的映射方式,把多个小文件采用追加写的方式聚合到一个POSIX文件系统上的大文件中,从而大大减少存储系统的元数据,提高文件的访问效率。当要存大量的小文件时,如果用传统的文件系统,一对一地去存小文件,存储空间利用率很低、查询的开销非常高。
另外介绍一下SeaweedFS的架构。它包含两个组件,一个是数据存储集群,即Volume Server Cluster,每个volume server对应一个磁盘,每个磁盘有一系列的volume文件,每个volume文件默认大小为30GB,用于存储小对象。每个volume文件对应一个index文件,用于记录volume中存储的小对象的偏移和长度,在volume server 启动时缓存在内存中。
这也是Haystack的一个重要设计思想,它做了一个两级的元数据映射,第一级把它映射到一个大文件,这样文件系统本身的元数据开销是很小的。第二次映射的时候,只需要在大文件内部去找它的偏移和长度。而且做完两级映射之后,可以使大文件里对应的小文件的元数据全部缓存在内存里面,这样就可以大大提高它的查找的效率。
另外一个组件称为Master Server Cluster,运行的是raft协议,维护集群的一致性状态,一般与volume server混部。volume server会向它上报自己的状态,然后它能够维护整个volume server cluster的拓扑。同时它还负责对象写入时volume server的分配,以及负责数据读取时volume id到volume server地址映射。
下面我们展开来讲SeaweedFS。首先上传过程,第一步是客户端先与master server cluster的leader通信,leader进行volume分配,给客户端返回一个fskey及volume server地址,fskey包含volume id,needle id及cookie三部分。Volume id跟volume server对应,needle id用于在一个volume内做索引,cookie用于安全考虑,大家有兴趣进一步了解的话,可以参看Haystack的论文。
第二步,客户端将文件及fskey发送给对应的volume server,该volume server为存储主副本的server,称为primary,primary将文件追加到对应的volume文件尾部,并将offset,length,needle id记录到对应的index文件。
Primary将文件写入后,将文件发送给两个存储副本的volume server,称为slave,待slave返回写入成功后,给客户端返回写入成功。
(如下图)
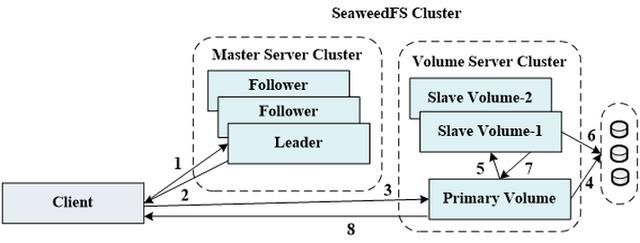
删除操作体现了Haystack的思想——它的删除是异步删除的。客户端用对象对应的fskey与master server中的leader通信,得到fskey中volume id对应的volume server地址。这实际上是做了一层间接,因为volume server有可能会挂掉,所以不能直接把volume server的地址给client。同时也便于master做一些负载均衡。每次读的时候也会首先跟leader通信,然后拿到volume server地址之后,再去访问主副本。然后主副本就会把这个对象做一个标记删除,它不会真正去删那个文件,不会真正从大文件里把那部分挖空。只是标记一下,不会做数据删除,Volume server会通过一个异步的compaction操作来回收数据。
异步compaction是什么?就是说这个大文件,每删一个文件就会留下一个空洞,如果Volume里面已经有很多的空洞了,现在决定要重新用这个资源,就会做一次compaction,就是把Volume里面剩余的、还没有删除的文件全部拷出来,重新把它拼成一个连续的文件,然后把其他的空洞对应的地方释放掉。
下载其实跟删除类似,首先客户端用对象对应的fskey与master server中的leader通信,得到fskey中volume id对应的volume server地址,然后访问volume server,volume server根据volume id,needle id访问对应volume文件的index文件,得到对象在volume文件内的偏移和长度。Volume server再访问对应volume文件,给client返回对象数据。
伴随业务增长下的第一次演进——GIFT V2.0
以上介绍就是GIFT最早的版本(V1)。随着本身数据文件量和业务量的增加,问题也越来越多。其中的一个表现是什么?随着业务量不断增加(TB -> PB),架构无法支持PB级存储。因为数据存储SeaweedFS是有中心设计模式,集群规模增大存在并发访问性能瓶颈问题。读写请求必须先经过master server,再访问volume server获取数据。master server运行raft协议,只有一个leader在工作,其它为follower。只有leader处理读写请求,存在单点性能瓶颈。在高并发的情况下,访问延迟明显的增加。然后就是,我们最早的设计,元数据的存储为单库设计,所以是所有用户集群共享的,造成QPS受限。
所以我们就对它做了一个架构的演进。主要的思想,首先在数据存储方面,我们从业务逻辑角度支持接入服务管理多个SeaweedFS集群,就是多个存储子集群。当一个SeaweedFS集群的容量达到阈值时,将其标记成只读,新数据写入其它集群。而且我们支持SeaweedFS集群的动态加入、动态注册。集群扩容过程为,首先一个新的SeaweedFS集群会向接入服务注册,然后接入服务将其加入可写集群列表,接入服务对上传文件的bucket, object信息做hash,选取一个可写集群,进行写入操作。这是从数据的角度解决QPS和存储容量的需求。
从元数据的角度,我们支持了支持多库分表模式,可对不同用户集群采用不同库,解决海量文件并发访问问题。下面具体介绍一下。从元数据的角度,我们做了一个分库和分表。首先我们可能有不同的Region,而不同的Region下面可能还有不同的用户集群(下图1)。我们除了有一个全局唯一的配置库以外,从对象的元数据库的角度,做了一个分库和分表的设计。(下图2)

(图1)

(图2)
具体到上传过程,用户指定了它在一个Bucket的下面一个object。首先会根据Bucket的信息,去查全局唯一的一张表,从这里查到Bucket对应的Region在什么地方,然后得到Region之后,才会同时去查Region作为关键字所对应的存储集群有哪些。这也是一张全局唯一的表,Region下面因为会有一系列的支持存储集群,就是SeaweedFS集群。进一步就会去做一个调度,然后决定去写入哪一个存储集群。
写完之后,SeaweedFS会返回一个fskey,我们需要存下来,fskey以及对象本身的一系列元数据存在什么地方。从元数据存储的角度来讲,每一个Region下面针对不同的用户集群有一个分库。查这张全局的表,我们可以得到Region下面真正存这些元数据的库是哪个,然后再去访问那个库。在那个库下面我们又进一步做了一个分表的设计,就是说这个库下面的所有这些对象的元数据,是有一系列的分表的,而分表的依据就是把Bucket和object联合起来,再做一次CRC,再模上整个分表的总数,就得到了它要存到哪个分表里面,然后就把它对应的这一系列的元数据存进去。这样就从元数据的角度去解决了整个集群的海量PB级可扩展的一个设计。(如下图)
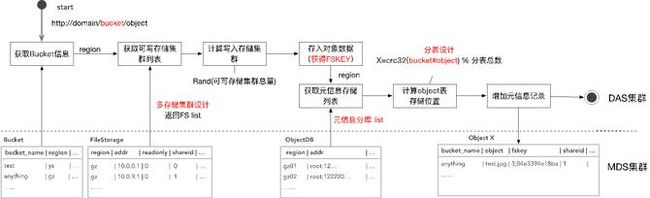
下载就是反过来,先拿到Bucket查这个表,得到它所在的Region,然后就得到它对应的元数据的数据库,用刚才说的CRC得到数据库下面都有是哪张分表。然后就可以从分表里得到它对应的元数据,元数据里面是记载了它所存储的数据存储集群的信息。拿到数据存储集群的信息以及fskey后再去访问对应的SeaweedFS集群,就可以得到对象的数据。整个就是这样的一个过程。(如下图)
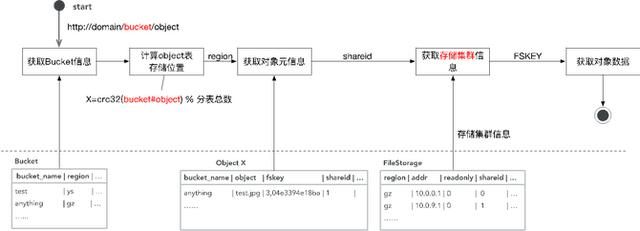
以上就是GIFT2.0版本的设计,它的可扩展性已经很不错了,已经能够支撑到一个PB级的存储。
昙花一现的GIFT V3.0与更好的V3.5
随着我们业务发展,有了新的需求,一个是之前我们这套系统主要提供对内服务,而我们现在还想支撑一个对外服务,这时我们可能就需要加入一些像计费、认证的逻辑,同时还需要去支持大文件的存储,就像我们刚才提到SeaweedFS其实更多是存小文件,所以我们又做了一个3.0版的一个设计。
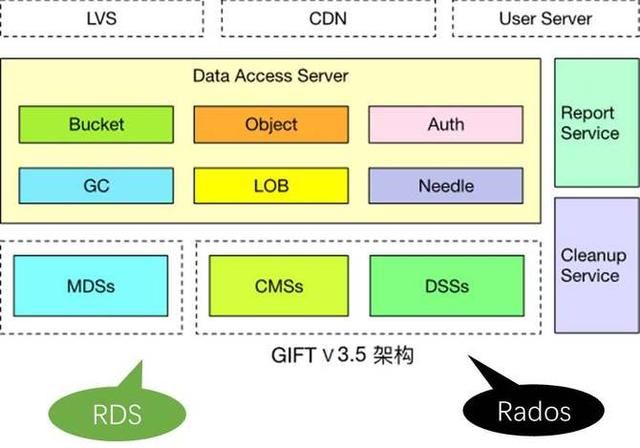
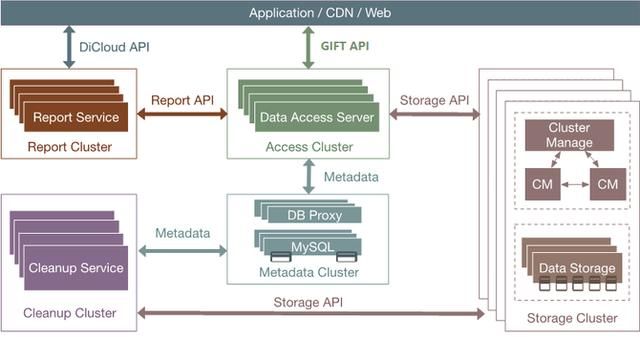
主要增加了一些功能组件:接入服务提供认证和数据操作接口;存储服务,小文件存储在SeaweedFS,大文件存储在HDFS;Report Service(上报服务)用来定时推送用户统计量信息;Cleanup Service(清除服务)用来删除过期数据;RDS主要用来存储object和fskey对应关系以及配置表信息。架构图如下:
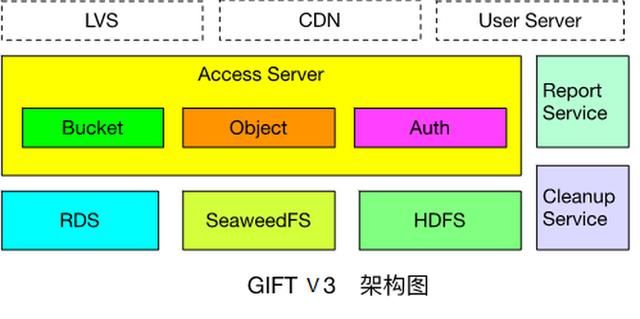
其实3.0这个版本存在的时间不是那么长,因为还觉得它存在一些问题:对于SeaweedFS,运维复杂,不支持故障自恢复、需手动恢复数据,且恢复以volume为粒度;不支持数据rebalance;Master server维护volume id与volume server的映射关系,为单节点,所有请求经过master server;不支持纠删码。
HDFS存在NN问题,它本身其实也是一个有中心化设计。而在GIFT应用场景下,元数据已由RDS存储处理,我们希望存储服务本身尽量保证可扩展性、高可靠性,不希望在这里还有一些元数据限制它的可扩展性,所以存储服务应尽量采用无中心化的模式。然后HDFS本身也不太适合小文件。虽然它本身的出错恢复有一些考虑,但我们觉得还是不够强,随着集群规模越大,出错恢复越慢。另外还有一个问题,整个架构中大小文件用两个系统去存,本身对我们的运维成本控制不太理想,所以我们进一步想把存储的后端再做一些迭代和优化。
之后,就是GIFT3.5版本。我们把存储底层换掉,采用CephRADOS object storage。Ceph大家比较熟悉,现在应该是开源的云计算场景下应用最多的存储组件。我们决定存储底层换成RADOS统一去支撑大小文件。用这样一个架构去支持大小文件,当然有一些逻辑需要我们自己做,比如说小文件的合并,就像刚才介绍的思路,跟Haystack、SeaweedFS都完全类似。
就是把一系列小文件聚合到一个RADOS的大对象里面,聚合的方式用追加写。大文件做分片。删除异步做GC。
下面介绍整个架构。当前的架构就是最前端有做负载均衡的LVS,当然也有CDN,因为提供对象存储,尤其对外服务,CDN是必不可少的组件。然后数据接入服务,这里面支持Bucket、Object的逻辑,还支持认证的逻辑,然后支持大文件LOB小文件Needle这样一些RADOS这一层的业务逻辑,要做聚合、做分片。然后新的组件有两个,一个是CMS,维护整个Ceph集群本身的拓扑一致性。DSS就是RADOS的一个存储组件,类似于刚才的volume server,主要是负责数据存储。MDS是提供元数据服务的。上报服务和清除服务还是延续3.0的设计。
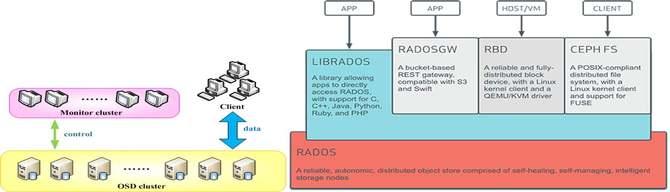
下面讲我们为什么要用RADOS。RADOS是国际上广泛部署使用的大规模分布式存储系统Ceph的底层存储组件,提供可伸缩、高可靠的对象存储。它的优势在于:高数据可靠性,数据冗余支持多副本或纠删码,支持scrub发现静默数据错误;无元数据服务、去中心化的设计,良好的横向扩展能力,支持PB级存储;运维简单,数据自恢复,集群自伸缩,数据自平衡;所有组件集群化设计,无单点故障。RADOS在生产环境的应用广泛。
下图是Ceph的架构,Client提供标准块、文件接口的访问能力,Monitor监视和维护集群状态和拓扑结构,OSD存储数据。
接下来具体介绍,在这样一个架构下一些具体问题的处理方式。第一个是怎么支撑大文件。对于一个大文件来讲,我们可以在业务这一层做分片。对于大于4M(可配置)以上大文件,存储到多个rados对象,提高大文件访问性能。因为一个大文件是分别存到了多个盘上面,在读取的时候就可以并发了。然后是小文件的设计思想,小文件合并存储到一个rados对象,rados对象元数据记录小文件在对象内的位置和偏移,小文件使用异步回收,通过顺序写提高性能。同时采用二级元数据方式减少元数据开销,提高空间利用率。
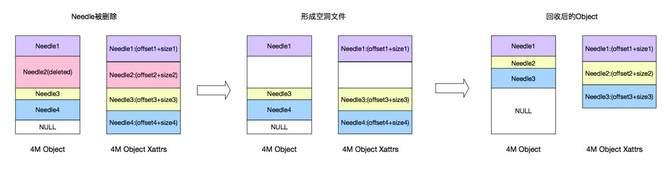
异步GC刚才也提到了,比如说已经有很多小文件,现在删了一个,中间就留下了一个空洞,当空洞越来越多的时候,到了一定的阈值,就重新去做一个拷贝,然后把剩下的数据聚合起来,重新形成一个连续的对象,把剩下的空间释放出来。(如下图)
这里还有一个上报服务的设计。因为我们要对外提供服务,所以我们需要定期上报用户的用量统计信息。这里我们利用了redis的分布式锁,上报服务可以在多个节点上同时运行,多个上报服务之间相互不感知,只通过redis分布式锁去做一个类似于抢占的模式,来保证不会上报有冲突,或者说同时去上报同一个用户信息。具体就是用到redis这样一个有续集的接口,针对每个用户,以用户的ID作为key,它的值就是这一次上报的时间。
那么每一个上报服务是怎么运行的?一来先用redis这个接口做一个排序,根据上次的上报时间做升序排列,最久没有上报的排在最前面,然后首先去抓列表里第一个元素来上报。因为大家都会做这个操作,因为大家相互不感知,但是来之前首先会加一把锁,如果加锁成功了,那就证明只有我会上报这个数据,别人就肯定不会上报。我就用redis分布式锁的机制,用一个set lock操作去尝试上这个锁。如果上锁成功,那么就上报数据,之后就重新把元素的值改成当前时间,然后再把锁清除。如果同时有另外一个上报服务也想上报这个数据,它会发现加锁失败,那么就自然跳过了上报,然后去找列表里的第二个元素上报,这样就保证了大家的一个互斥性。然后也保证了各个上报服务可以并行工作,提升上报的效率。(具体参考下图)

异地灾备的思想比较简单。(如下图)我们支持两机房,主要就是利用消息队列,主数据中心这边(A机房)存储完成之后,会向消息队列发送一个消息,告诉它我现在已经上传一个文件,包括访问的url是什么样的——这样一些信息。对应(B机房)这边的备份模块,它订阅了这样一个消息队列,就可以收到对应的发布消息。它知道A机房那边刚刚上传一个文件,访问的url,然后就可以用url把数据拉过来,存到这边,实现异地备份。

另外有一个比较棘手的问题。就是Ceph本身虽然确实比较好,但这种去中心化其实有一个通用的问题,就是当你集群扩容的时候,需要做数据迁移。这个问题跟一致性哈希类似,当集群扩容的时候,有些数据对应的哈希值就会改变,这就导致一个数据迁移。而数据迁移是我们非常不喜欢的,因为现在仅仅是做了一个扩容操作,就需要做大量的迁移,需要重新做平衡,这样会影响业务的性能。因为在后端的迁移操作会占用大量的IO带宽,所以这个问题我们也是想通过一个方式去解决。
简单介绍下Ceph的映射过程,它实际上是一个两级映射。首先一个Object的名字通过Hash映射到PG,PG(Placement Group)就是一个对象组。引入对象组的概念,避免了object与OSD的直接映射,减小了海量对象管理的复杂性,RADOS的许多操作是以PG为单位进行。
这个时候首先通过哈希映射到一个PGID上面,PGID再通过一个CRUSH算法,选出三组OSD(假如是三副本),其中第一个就是主的存储副本,其他为从副本。就是这样的一个过程。(如下图)

现在说刚才这个问题,Ceph本身的去中心化CRUSH算法确实好,自身可扩展性非常好。但带来问题就是集群扩容的时候,数据要迁移,会导致集群性能的抖动。那么我们解决的一个思路,就是想让它扩容的时候不迁移。思想其实还是跟我们之前解决SeaweedFS本身单集群性能的思想类似,就是在业务这一层多做一层调度。Ceph本身其实CRUSH规则的应用粒度是pool粒度的,每个pool可以指定不同的CRUSH对象映射规则。利用这一点,我们去增加一层基于pool的调度。具体的算法就是,如果现在急需扩容,加了一些集群的节点,我就新建一个pool,然后为pool去配一个CRUSH规则。
因为Ceph的对象放置规则是可以去描述的、可以指定的,那么我们就可以去写CRUSH规则,使得该pool的对象只分布在新增的节点上。在上传文件时进行pool调度,选择空间占用较少的pool,将文件写到选择的pool。由于已有的pool的集群节点不变,不会产生数据迁移。所以原来的数据都不会变,新来的数据只会到新的节点上面,主要是通过这样一个思想去解决迁移问题。
最后总结一下GIFT V3.5架构的特点 ,它具有:
1、良好的扩展性
·接入层无状态,支持通过负载均衡扩展
·元数据存储层通过分库分表方式支持横向扩展
·数据存储层通过无中心的设计和分集群方式支持横向扩展
2、良好的服务可用性
·接入层、元数据存储层、数据存储层都无单点失效问题
3、良好的数据可靠性
·数据多副本存储,可指定副本放置规则
·数据自恢复
以上主要就是我的一些分享,谢谢!