正则表达式与字符集
菜鸟教程关于java正则表达式:http://www.runoob.com/java/java-regular-expressions.html
正则表达式
关于正则表达式,网上有很多的介绍,其中菜鸟教程中介绍很简洁实用。《Java nio中文版》而很全面。主要有以下类:
- Pattern:Pattern 类封装了正则表达式,它是你希望在目标字符序列中检索的模式。匹配正则表达式的代价可能非常高昂,因为可能排列数量巨大,尤其是模式反复应用的情况。大部分正则表达式处理器首先会编译表达式,然后利用编译好的表达式在输入中进行模式检测。
- Matcher:Matcher 类为匹配字符序列的正则表达式模式提供了丰富的 API。Matcher 实例常常通过对 Pattern 对象调用 matcher( )方法来创建的
不编译匹配,更多的用于校验当前字符串是否匹配正则表达式
import java.util.regex.*;
class RegexExample1{
public static void main(String args[]){
String content = "I am noob " +
"from runoob.com.";
String pattern = ".*runoob.*";
boolean isMatch = Pattern.matches(pattern, content);
System.out.println("字符串中是否包含了 'runoob' 子字符串? " + isMatch);
}
}编译匹配,更多是用于获得匹配组的信息,其中需要关注的是group(0)表示整个字符串,而groupCount 却不包括group(0):
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches
{
public static void main( String args[] ){
// 按指定模式在字符串查找
String line = "This order was placed for QT3000! OK?";
String pattern = "(\\D*)(\\d+)(.*)";
// 创建 Pattern 对象
Pattern r = Pattern.compile(pattern);
// 现在创建 matcher 对象
Matcher m = r.matcher(line);
if (m.find()) {
System.out.println("Found value: " + m.group(0) );
System.out.println("Found value: " + m.group(1) );
System.out.println("Found value: " + m.group(2) );
System.out.println("Found value: " + m.group(3) );
} else {
System.out.println("NO MATCH");
}
System.out.println(m.groupCount());
}
}字符集
字符与Unicode代理
以下来自:
《Java nio中文版》
https://blog.csdn.net/mazhimazh/article/details/17708001
https://blog.csdn.net/guxiaonuan/article/details/78678043
https://www.ibm.com/developerworks/cn/java/j-unicode/
字符集类
Charset封装编码的字符集编码方案,用来表示与作为字节序列的字符集不同的字符序列。
编码字符集
编码字符集是一个字符集,它为每一个字符分配一个唯一数字。Unicode 标准的核心是一个编码字符集,字母“A”的编码为0041和字符“€”的编码为20AC。Unicode标准始终使用十六进制数字,而且在书写时在前面加上前缀“U+”,所以“A”的编码书写为“U+0041”。
字符集编码类
CharsetEncoder:编码引擎,把字符序列转化成字节序列。之后字节序列可以被解码从而重新构造源字符序列。
字符集解码器类
CharsetDecoder:解码引擎,把编码的字节序列转化为字符序列。
字符集供应商 SPI
CharsetProvider SPI:通过服务器供应商机制定位并使 Charset 实现可用,从而在运行时环境中使用。
代码点code point
代码点是指可用于编码字符集的数字。编码字符集定义一个有效的代码点范围,但是并不一定将字符分配给所有这些代码点。有效的 Unicode代码点范围是 U+0000 至 U+10FFFF
代码单元
代码单元可以理解为字符编码的一个基本单元,最常用的代码单元是字节(即8位),但是16位和32位整数也可以用于内部处理。
增补字符
16 位编码的所有 65536 个字符并不能完全表示全世界所有正在使用或曾经使用的字符。于是,Unicode 标准已扩展到包含多达 1112064 个字符。那些超出原来的16 位限制的字符被称作增补字符。
出现的问题
Java的char类型是固定16bits的。代码点在U+0000 — U+FFFF之内到是可以用一个char完整的表示出一个字符。但代码点在U+FFFF之外的,一个char无论如何无法表示一个完整字符。这样用char类型来获取字符串中的那些代码点在U+FFFF之外的字符就会出现问题。
如何解决
因此,Java 平台不仅需要支持增补字符,而且必须使应用程序能够方便地做到这一点。Java Community Process 召集了一个专家组,以期找到一个适当的解决方案。该小组被称为JSR-204专家组,使用Unicode 增补字符支持的Java技术规范请求的编号。
此时如果要表示unicode值时,可以有几种实现,utf-8、utf-16、utf-32。utf-8与utf-16都是变长的。utf-8用1到6个字节编码Unicode字符。 utf-16比起utf-8,好处在于大部分字符都以固定长度的字节 (2字节) 储存,超过两个字节的Unicode,使用4个字节表示,但utf-16却无法兼容于ASCII编码。UTF-32对每个字符都使用4字节,就空间而言,是非常没有效率的。
在java内部运行时,char使用的utf-16进行传递的。
当我在查看CharSequence时发现codePoint,可以看出CharSequence.length()返回的是char的长度,并不管几个2个字节还是4个字节作为一个字符,只是将2个字节作为一个长度。
CharSequence
由下面的API可以看出,CharSequence是一个接口,另外红线圈出的D表示的是使用default修饰的方法,这是jdk1.8中添加的特性,使得接口中的方法也可以有实现。
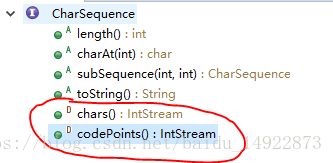
在接口定义中的两个default方法如下:
/**
* Returns a stream of {@code int} zero-extending the {@code char} values
* from this sequence. Any char which maps to a surrogate code
* point is passed through uninterpreted.
*
* If the sequence is mutated while the stream is being read, the
* result is undefined.
*
* @return an IntStream of char values from this sequence
* @since 1.8
*/
public default IntStream chars() {
class CharIterator implements PrimitiveIterator.OfInt {
int cur = 0;
public boolean hasNext() {
return cur < length();
}
public int nextInt() {
if (hasNext()) {
return charAt(cur++);
} else {
throw new NoSuchElementException();
}
}
@Override
public void forEachRemaining(IntConsumer block) {
for (; cur < length(); cur++) {
block.accept(charAt(cur));
}
}
}
return StreamSupport.intStream(() ->
Spliterators.spliterator(
new CharIterator(),
length(),
Spliterator.ORDERED),
Spliterator.SUBSIZED | Spliterator.SIZED | Spliterator.ORDERED,
false);
}
/**
* Returns a stream of code point values from this sequence. Any surrogate
* pairs encountered in the sequence are combined as if by {@linkplain
* Character#toCodePoint Character.toCodePoint} and the result is passed
* to the stream. Any other code units, including ordinary BMP characters,
* unpaired surrogates, and undefined code units, are zero-extended to
* {@code int} values which are then passed to the stream.
*
*
If the sequence is mutated while the stream is being read, the result
* is undefined.
*
* @return an IntStream of Unicode code points from this sequence
* @since 1.8
*/
public default IntStream codePoints() {
class CodePointIterator implements PrimitiveIterator.OfInt {
int cur = 0;
@Override
public void forEachRemaining(IntConsumer block) {
final int length = length();
int i = cur;
try {
while (i < length) {
char c1 = charAt(i++);
if (!Character.isHighSurrogate(c1) || i >= length) {
block.accept(c1);
} else {
char c2 = charAt(i);
if (Character.isLowSurrogate(c2)) {
i++;
block.accept(Character.toCodePoint(c1, c2));
} else {
block.accept(c1);
}
}
}
} finally {
cur = i;
}
}
public boolean hasNext() {
return cur < length();
}
public int nextInt() {
final int length = length();
if (cur >= length) {
throw new NoSuchElementException();
}
char c1 = charAt(cur++);
if (Character.isHighSurrogate(c1) && cur < length) {
char c2 = charAt(cur);
if (Character.isLowSurrogate(c2)) {
cur++;
return Character.toCodePoint(c1, c2);
}
}
return c1;
}
}
return StreamSupport.intStream(() ->
Spliterators.spliteratorUnknownSize(
new CodePointIterator(),
Spliterator.ORDERED),
Spliterator.ORDERED,
false);
}