CFS完全公平调度算法 - per entity load tracking 几个重要的函数分析
kernel/sched/fair.c
负载衰减计算函数decay_load()
/*
* We choose a half-life close to 1 scheduling period.
* Note: The tables below are dependent on this value.
*/
#define LOAD_AVG_PERIOD 32
#define LOAD_AVG_MAX 47742 /* maximum possible load avg */
#define LOAD_AVG_MAX_N 345 /* number of full periods to produce LOAD_MAX_AVG */
/* Precomputed fixed inverse multiplies for multiplication by y^n */
static const u32 runnable_avg_yN_inv[] = {
0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6,
0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85,
0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581,
0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9,
0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80,
0x85aac367, 0x82cd8698,
};
/*
* Approximate:
* val * y^n, where y^32 ~= 0.5 (~1 scheduling period)
*/
//负载衰减计算,val * y^n, 将val的值衰减n次并返回(其中y^32 ~= 0.5,也就是约定了32ms之前调度实体的负载,对调度实体的累计负载的影响因子为0.5)
static __always_inline u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (!n)
return val;
else if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * k^(n%PERIOD)
* With a look-up table which covers k^n (n= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
val *= runnable_avg_yN_inv[local_n];
/* We don't use SRR here since we always want to round down. */
return val >> 32;
}
连续n个整周期的负载累计贡献值__compute_runnable_contrib()
/*
* Precomputed \Sum y^k { 1<=k<=n }. These are floor(true_value) to prevent
* over-estimates when re-combining.
*/
static const u32 runnable_avg_yN_sum[] = {
0, 1002, 1982, 2941, 3880, 4798, 5697, 6576, 7437, 8279, 9103,
9909,10698,11470,12226,12966,13690,14398,15091,15769,16433,17082,
17718,18340,18949,19545,20128,20698,21256,21802,22336,22859,23371,
};
/*
* For updates fully spanning n periods, the contribution to runnable
* average will be: \Sum 1024*y^n
*
* We can compute this reasonably efficiently by combining:
* y^PERIOD = 1/2 with precomputed \Sum 1024*y^n {for n = LOAD_AVG_MAX_N)) //如果n>=345,直接返回1024*(y + y^2 + y^3 + …… +y^n)的极限值47742。
return LOAD_AVG_MAX;
/* Compute \Sum k^n combining precomputed values for k^i, \Sum k^j */
//如果32<=n<=345,每递进32个衰减周期,负载贡献值衰减一半(y^32 = 1/2),并累加。
do {
contrib /= 2; /* y^LOAD_AVG_PERIOD = 1/2 */
contrib += runnable_avg_yN_sum[LOAD_AVG_PERIOD];
n -= LOAD_AVG_PERIOD;
} while (n > LOAD_AVG_PERIOD);
contrib = decay_load(contrib, n);// 最后衰减n中不能凑成32个衰减周期的剩余周期数
return contrib + runnable_avg_yN_sum[n];// n中不能凑成32个衰减周期的剩余周期数,单独计算衰减,并累加
}
更新调度实体的累计负载平均值__update_entity_runnable_avg()
/*
* We can represent the historical contribution to runnable average as the
* coefficients of a geometric series. To do this we sub-divide our runnable
* history into segments of approximately 1ms (1024us); label the segment that
* occurred N-ms ago p_N, with p_0 corresponding to the current period, e.g.
* [<- 1024us ->|<- 1024us ->|<- 1024us ->| ...
* p0 p1 p2
* (now) (~1ms ago) (~2ms ago)
*
* Let u_i denote the fraction of p_i that the entity was runnable.
*
* We then designate the fractions u_i as our co-efficients, yielding the
* following representation of historical load:
* u_0 + u_1*y + u_2*y^2 + u_3*y^3 + ...
*
* We choose y based on the with of a reasonably scheduling period, fixing:
* y^32 = 0.5
*
* This means that the contribution to load ~32ms ago (u_32) will be weighted
* approximately half as much as the contribution to load within the last ms
* (u_0).
*
* When a period "rolls over" and we have new u_0`, multiplying the previous
* sum again by y is sufficient to update:
* load_avg = u_0` + y*(u_0 + u_1*y + u_2*y^2 + ... )
* = u_0 + u_1*y + u_2*y^2 + ... [re-labeling u_i --> u_{i+1}]
*/
//更新调度实体的累计负载平均值
static __always_inline int __update_entity_runnable_avg(u64 now,
struct sched_avg *sa,
int runnable)
{
u64 delta, periods;
u32 runnable_contrib;
int delta_w, decayed = 0;
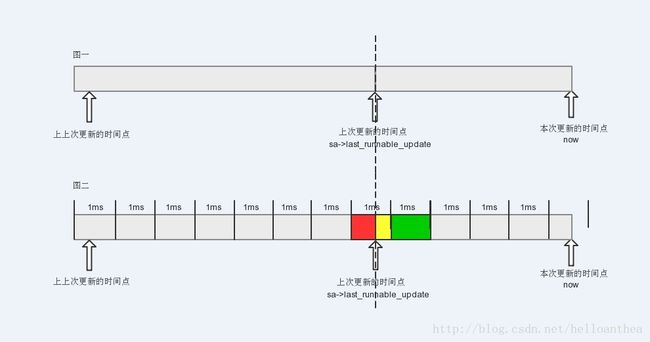
delta = now - sa->last_runnable_update;//delta,本次更新累计负载与上次更新累计负载的时间差,单位ns。
/*
* This should only happen when time goes backwards, which it
* unfortunately does during sched clock init when we swap over to TSC.
*/
if ((s64)delta < 0) {//如果delta为负,不需要更新累计负载,将累计负载更新时间刷新成最新时间,并返回0
sa->last_runnable_update = now;
return 0;
}
/*
* Use 1024ns as the unit of measurement since it's a reasonable
* approximation of 1us and fast to compute.
*/
delta >>= 10;//delta除以1024,将ns换算为us,用右移是为了提高效率。
if (!delta)//如果delta为0us,时间太短,则直接返回0,且不需要刷新累计负载更新时间。
return 0;
sa->last_runnable_update = now;//将累计负载更新时间刷新成最新时间。
/* delta_w is the amount already accumulated against our next period */
delta_w = sa->runnable_avg_period % 1024;//delta_w为上次更新调度实体的累计负载runnable_avg_period时,不能凑成1024us的剩余us,对应图二的红色部分,该部分已经被计算过累计负载。
if (delta + delta_w >= 1024) {//如果delta与delta_w的和大于等于1024us,说明至少一个周期(1024us)已经过去了
/* period roll-over */
decayed = 1; //将衰减标志decayed置位
/*
* Now that we know we're crossing a period boundary, figure
* out how much from delta we need to complete the current
* period and accrue it.
*/
delta_w = 1024 - delta_w; //这里是计算上次更新累计负载时,未被计算的剩余部分的累计负载,也就是(1024-delta_w),对应图二的黄色部分
if (runnable)
sa->runnable_avg_sum += delta_w;//如果是可运行的调度实体,才累加runnable_avg_sum
sa->runnable_avg_period += delta_w;//累加runnable_avg_period
delta -= delta_w;//计算除了(1024-delta_w)以外的剩余的delta
/* Figure out how many additional periods this update spans */
periods = delta / 1024;//计算本次更新与上次更新之间,总共跨越了几个周期,也就是有多少个周期(1024us)调度实体是一直运行的,对应图二的蓝色部分。
delta %= 1024;//本次更新中不能凑成1024us的剩余us,类似于上次更新中的delta_w,对应图二的绿色部分。
//分别对调度实体的runnable_avg_sum和runnable_avg_period执行衰减计算,即分别乘以y^(periods+1)
sa->runnable_avg_sum = decay_load(sa->runnable_avg_sum,
periods + 1);
sa->runnable_avg_period = decay_load(sa->runnable_avg_period,
periods + 1);
/* Efficiently calculate \sum (1..n_period) 1024*y^i */
runnable_contrib = __compute_runnable_contrib(periods);//调度实体在periods个周期(1024us)是一直运行的(u_i=1),所以直接计算y+y^2+y^3+……+y^period的累加值。
if (runnable)
sa->runnable_avg_sum += runnable_contrib;
sa->runnable_avg_period += runnable_contrib;
}
//如果delta与delta_w的和小于1024us,说明上次更新和这次更新还在同一个衰减周期(1024us)内,不需要执行衰减计算,直接将时间差加到runnable_avg_sum和runnable_avg_period即可。
/* Remainder of delta accrued against u_0` */
if (runnable)
sa->runnable_avg_sum += delta;//如果是可运行的调度实体,才累加runnable_avg_sum
sa->runnable_avg_period += delta;//累加runnable_avg_period
return decayed;//返回衰减标志
}