Python3 图片文字识别翻译——调用百度AI、百度翻译和有道翻译的API
文章目录
- Python3 图片文字识别翻译——调用百度AI、百度翻译和有道翻译的API
- 一、演示
- 二、 API准备
- 三、 图片文字识别——调用百度AI文字识别API
- 四、 文字翻译
- 1. 百度翻译
- 请求
- 解析返回数据
- 2. 有道翻译(与百度翻译类似)
- 请求
- 解析返回数据
- 五、 获取剪贴板的图片
- 六、程序界面设计
- 七、功能实现
- 1. 按照设计图填充控件
- (1)窗体初始化
- (2)主体框架
- (3)左边Frame填充
- (4)中间Frame填充
- (5)右边Frame填充
- (6)底部Frame填充
- 2. 补充——设置代理(存在问题)
- (1)新建agent.py文件
- (2)主窗体调用设置代理弹窗
- (3)修改网络调用的函数(添加代理)
- 八、未解决的问题
- 如何保存代理配置?
- 界面控件问题
- 界面美化
- 参考
Python3 图片文字识别翻译——调用百度AI、百度翻译和有道翻译的API
一、演示
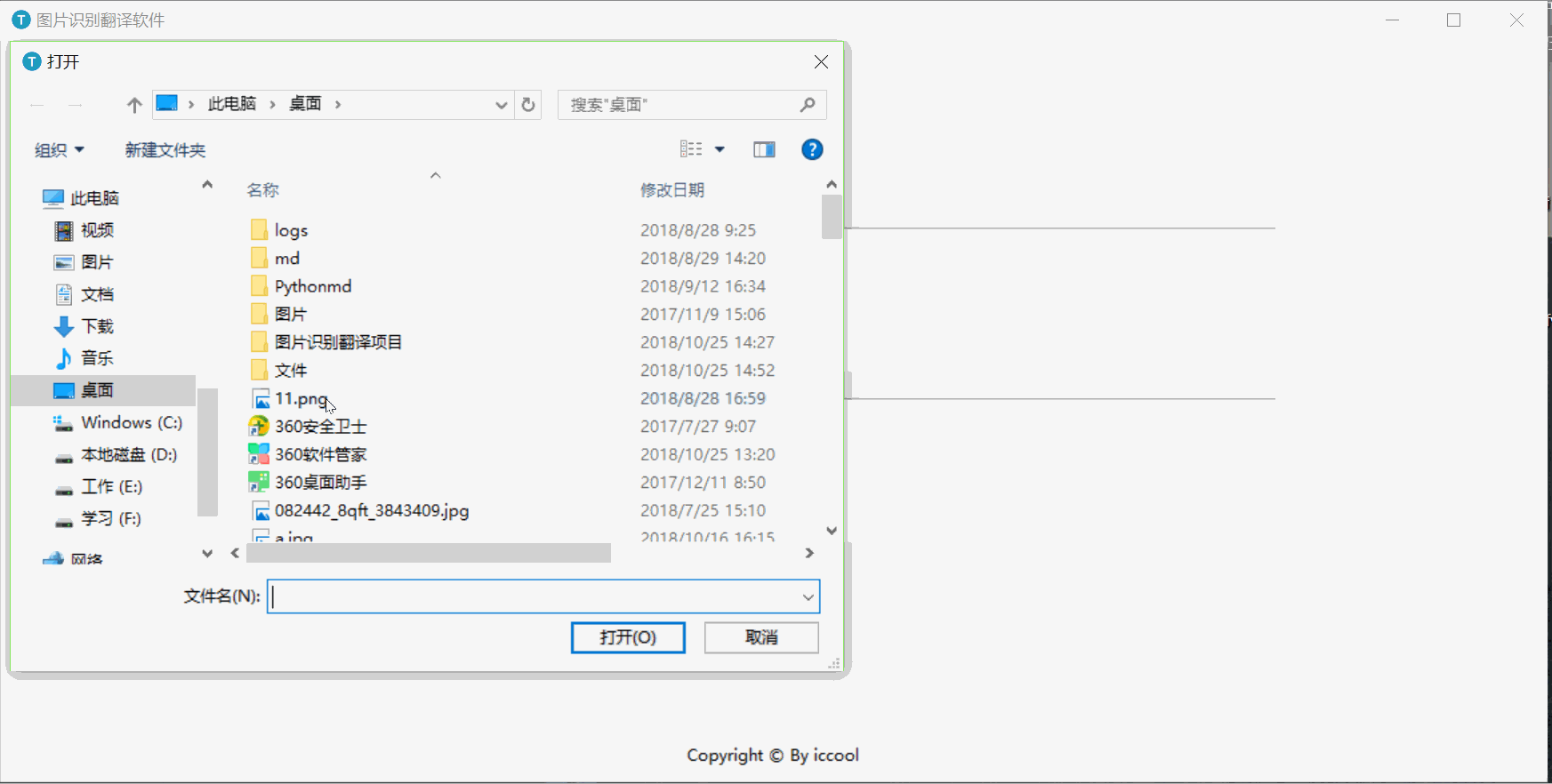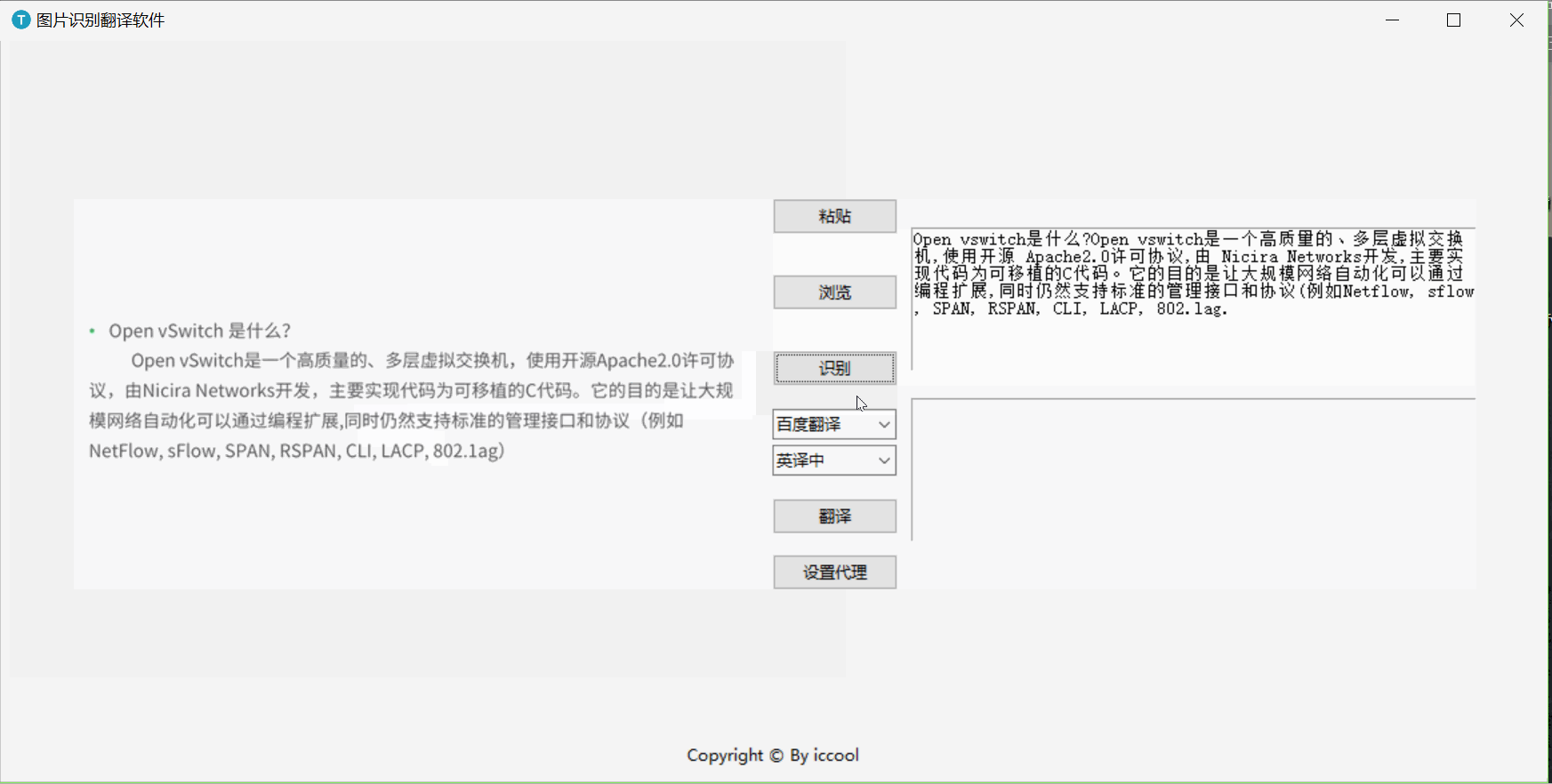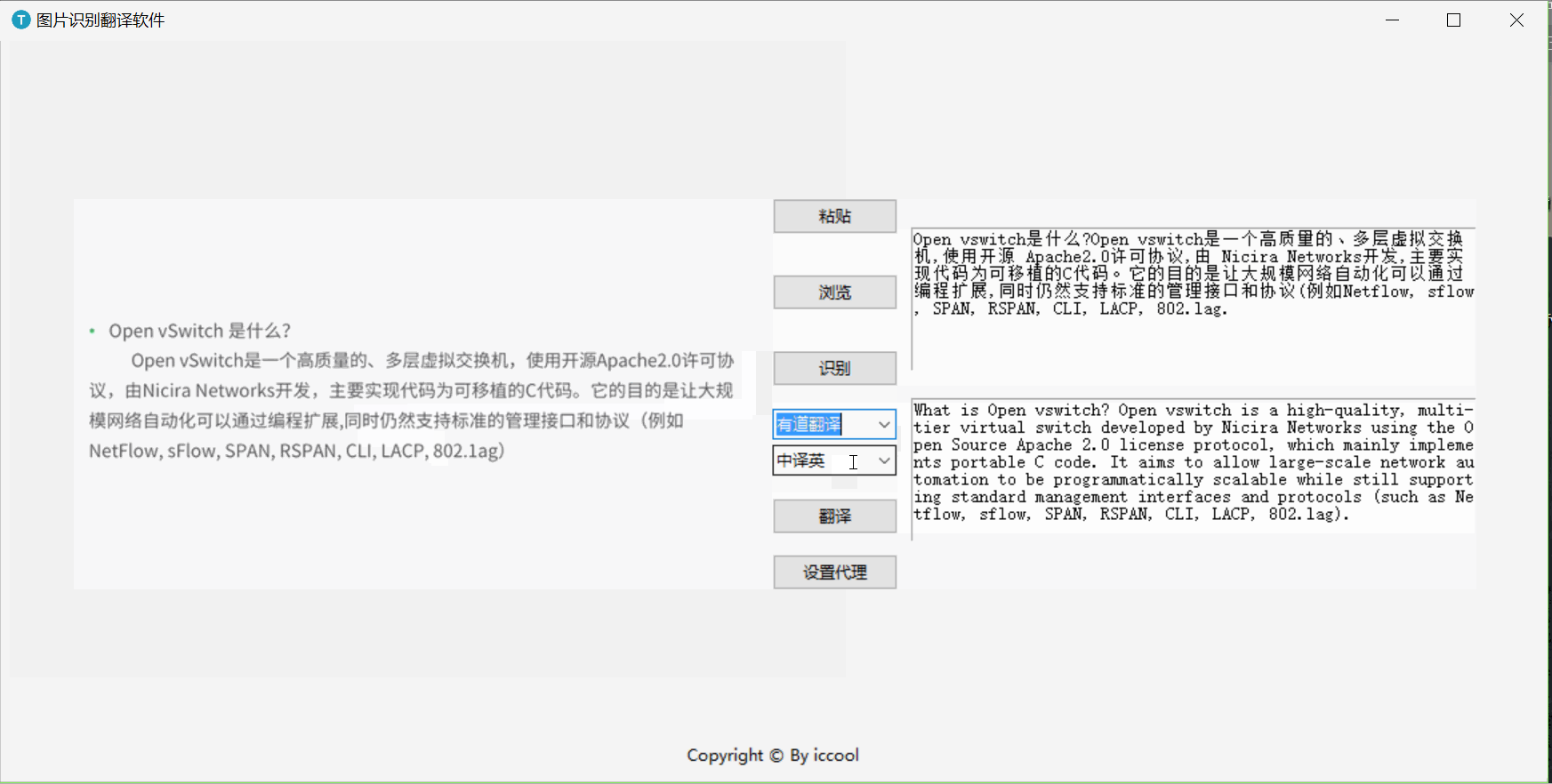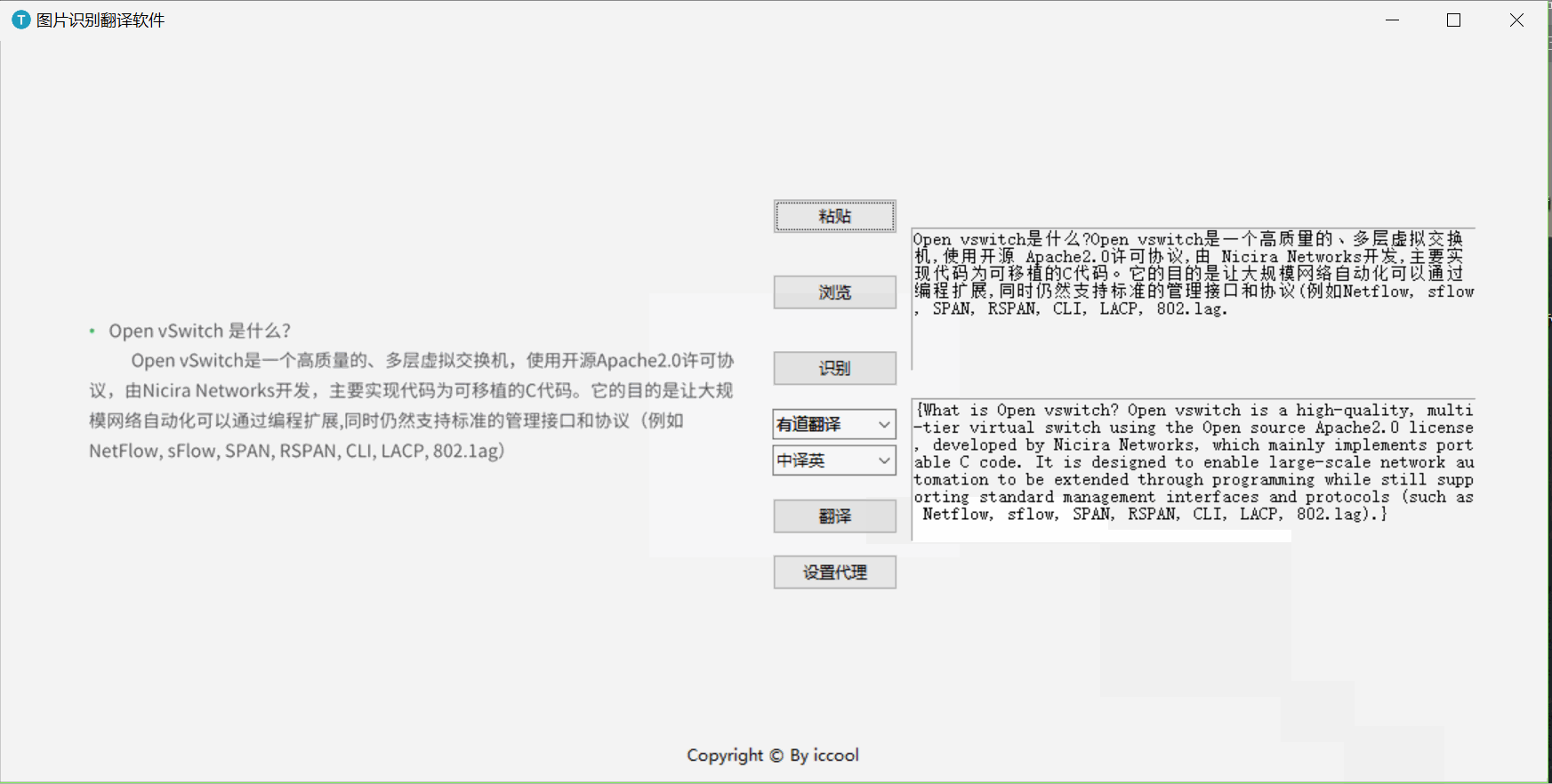
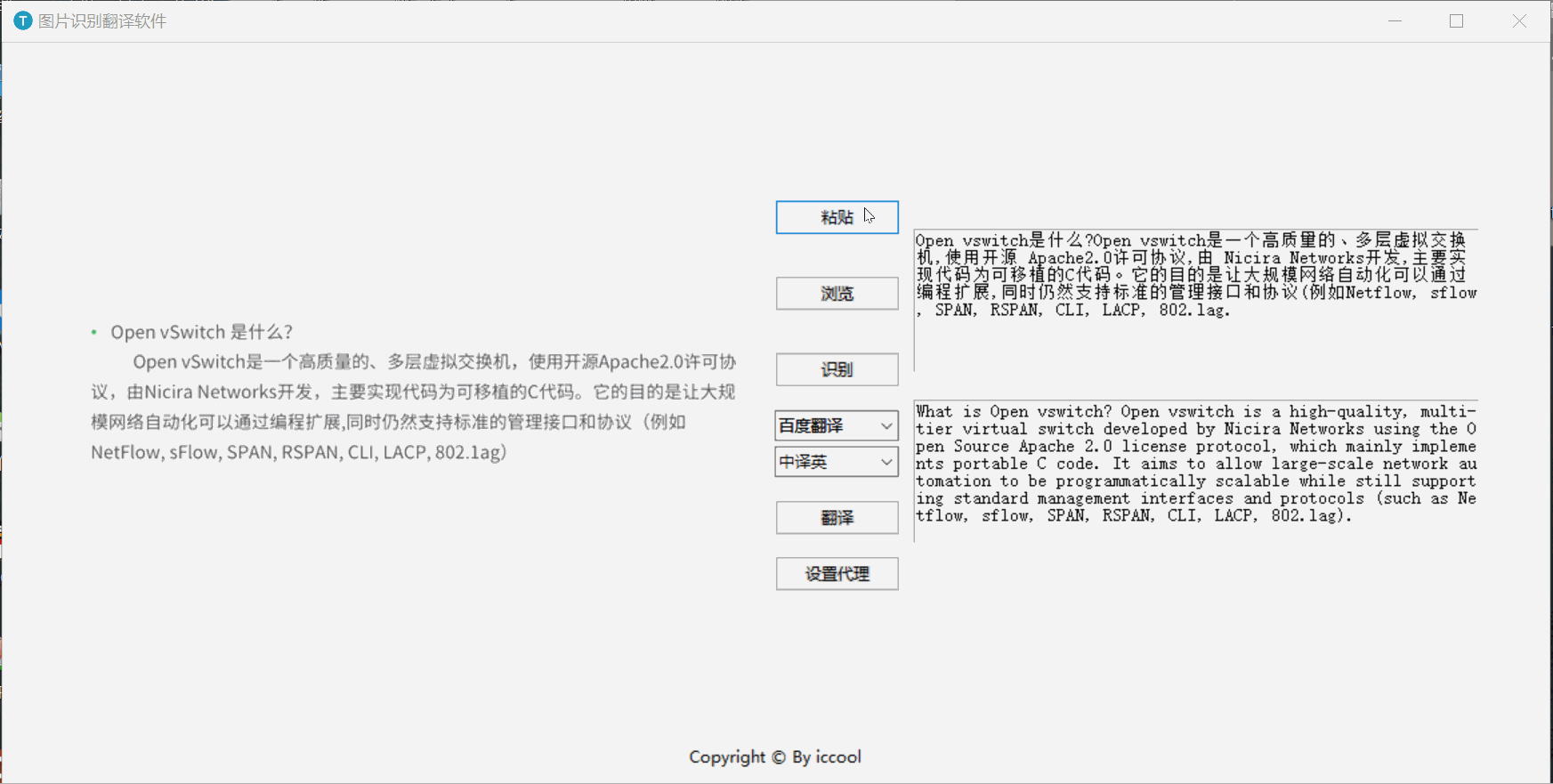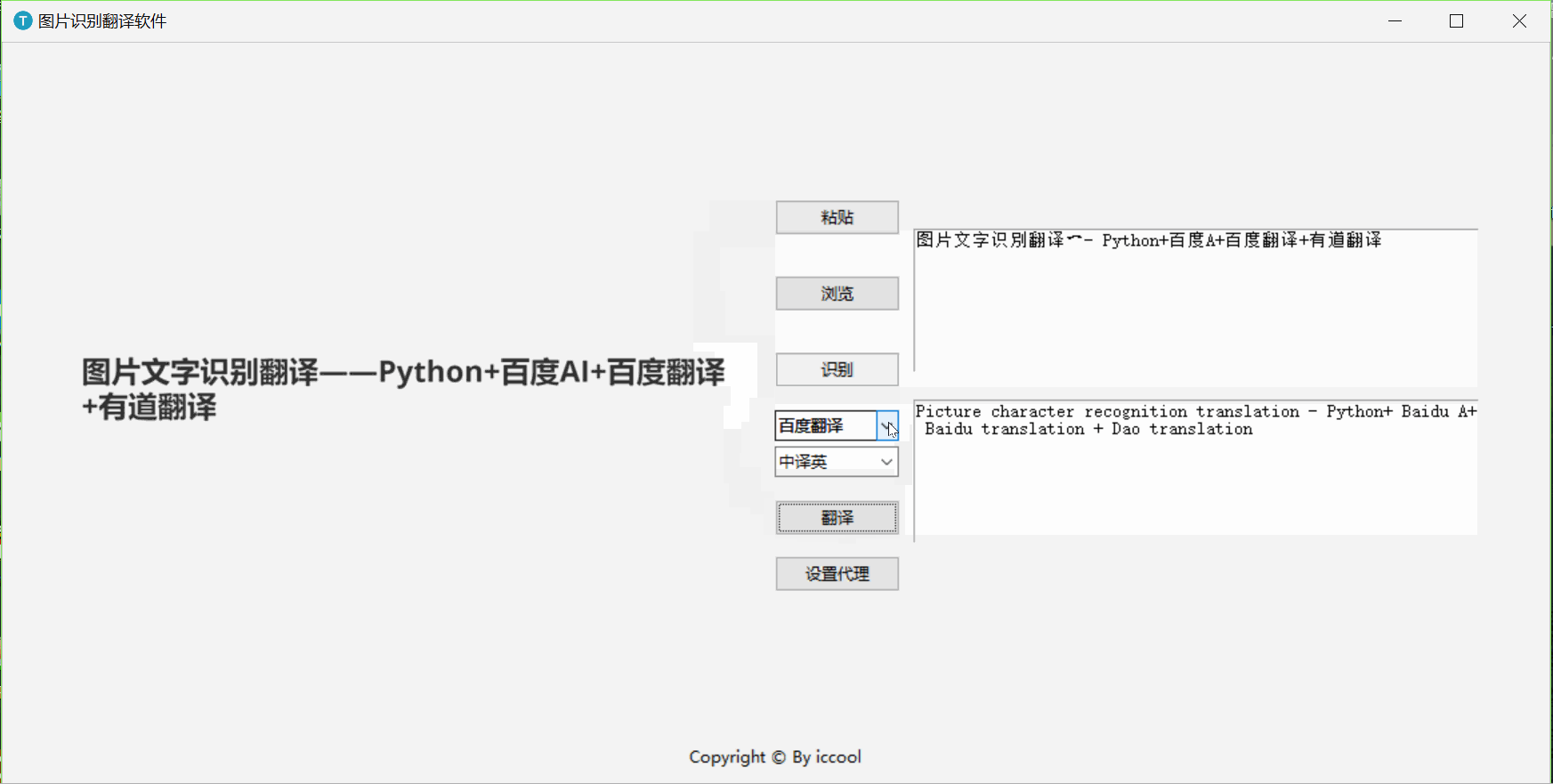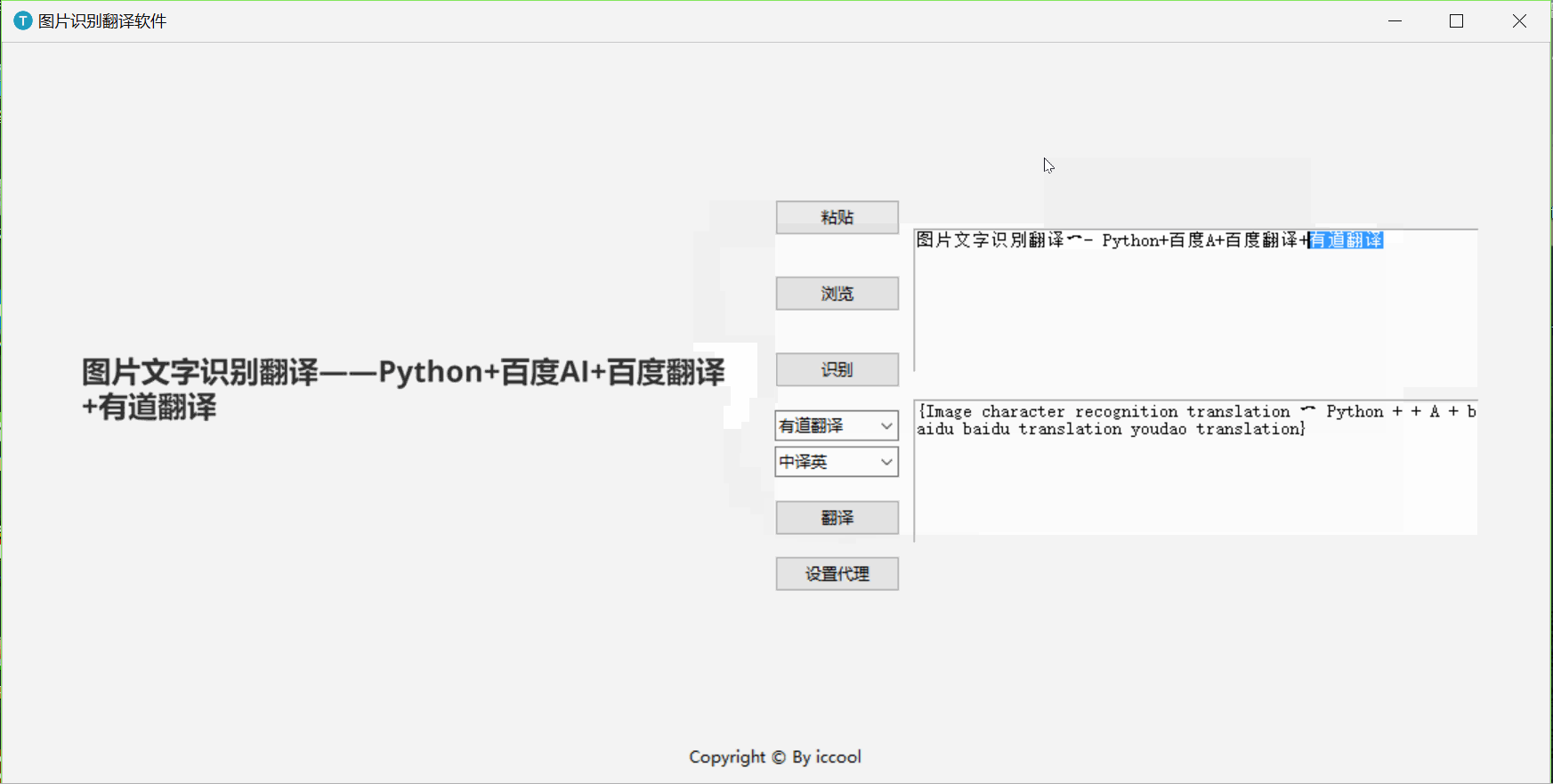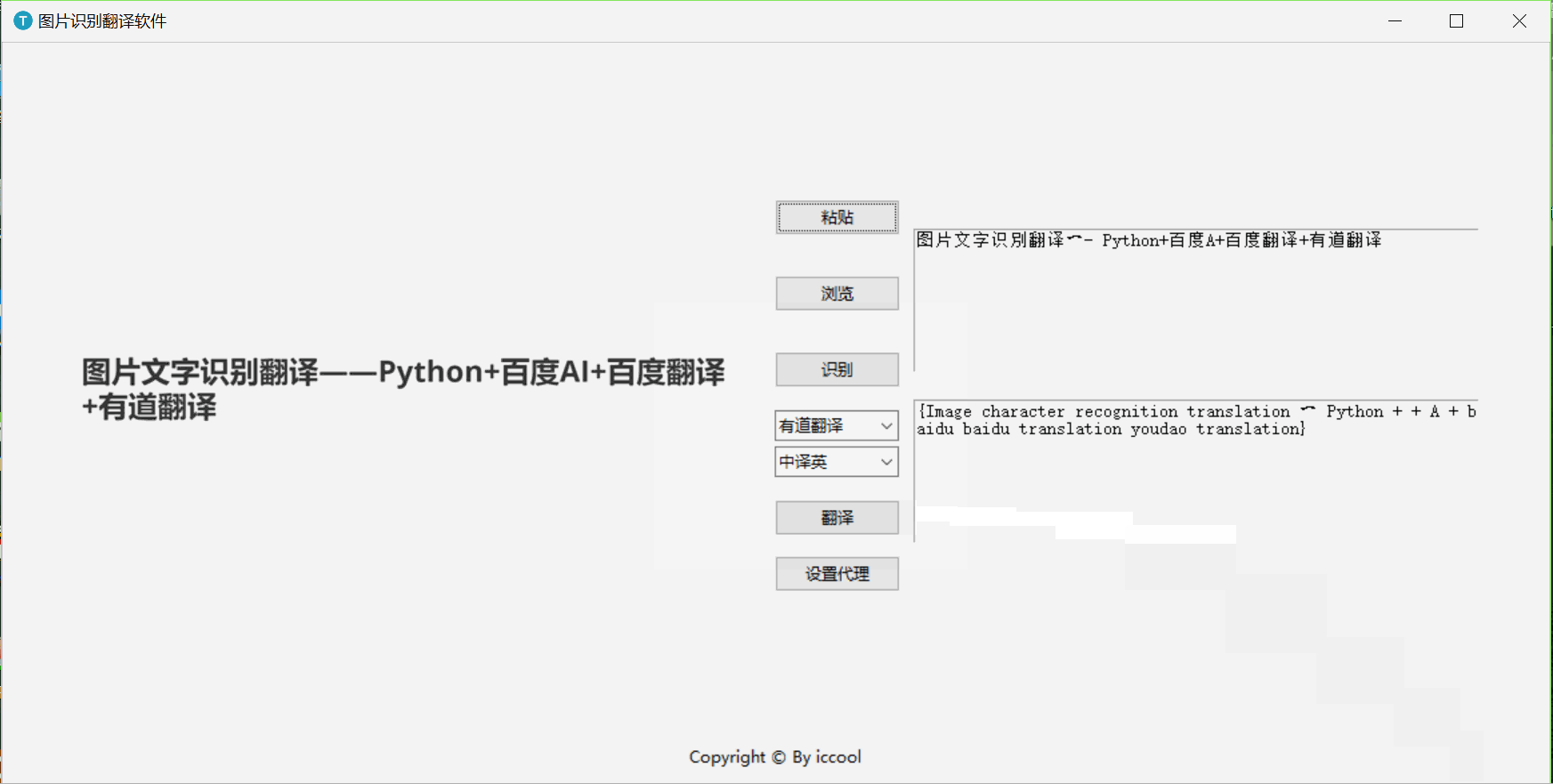
二、 API准备
-
百度AI
-
文字识别API
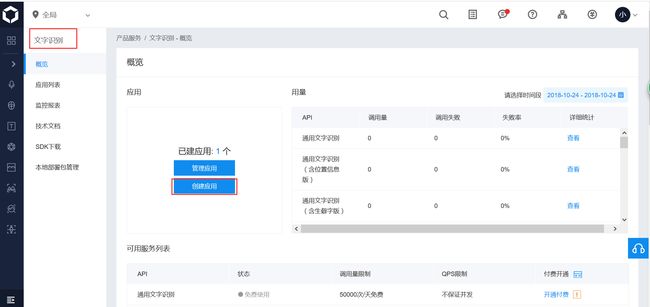
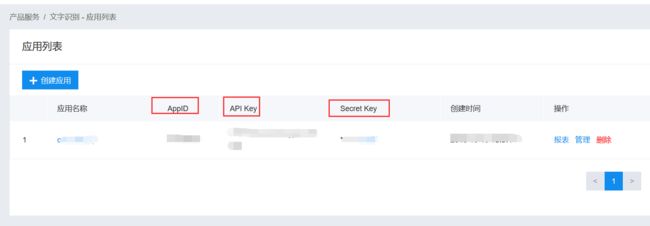
获取文字识别应用的AppID、API KEY、Secret Key
-
-
百度翻译开放平台
-
百度翻译API
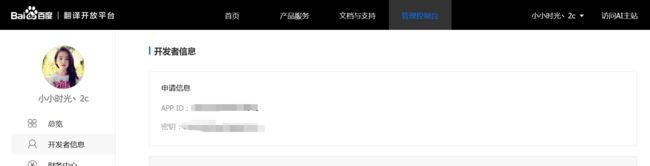
加入百度翻译开放平台,获取百度翻译应用的APP ID、密钥
-
-
有道智云
-
有道翻译API
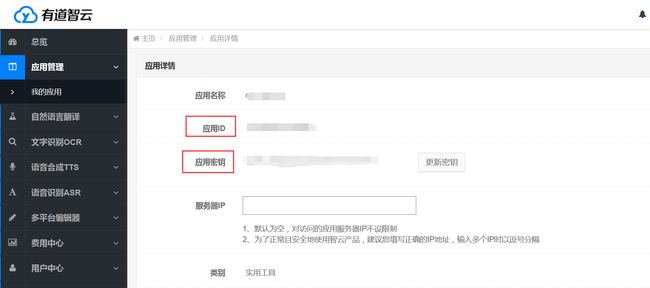
获取有道翻译应用的APP ID、密钥
-
三、 图片文字识别——调用百度AI文字识别API
阅读百度官方提供的API文档,图片的文字识别需要安装百度ai的包,pip install baidu-aip
- 获取连接client
- 读取图片
- 调用通用识别方法
- 接收返回结果
- 结果解析
# -*- coding: utf-8 -*-
__author__ = 'iccool'
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
""" 如果有可选参数 """
ai_options = {}
ai_options["language_type"] = "CHN_ENG"
ai_options["detect_direction"] = "true"
ai_options["detect_language"] = "true"
ai_options["probability"] = "true"
''' 获取百度api连接 '''
def getConnect(APP_ID, API_KEY, SECRET_KEY):
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# client.setProxies(proxies)
return client
''' 读取图片 '''
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
""" 调用通用文字识别, 图片参数为本地图片 """
def ocr_image(client, image):
message = client.basicGeneral(image, ai_options)
return message
image = 'example.jpg'
client = getConnect(APP_ID, API_KEY, SECRET_KEY)
message = ocr_image(client, image)
""" 调用通用文字识别, 图片参数为本地图片 """
# client.basicGeneral(image)
""" 带参数调用通用文字识别, 图片参数为本地图片 """
# client.basicGeneral(image, options)
返回结果示例
{
"log_id": 2471272194,
"words_result_num": 2,
"words_result":
[
{"words": " TSINGTAO"},
{"words": "青島睥酒"}
]
}
至此,简单版图片文字识别已完成,详细阅读官方文档
四、 文字翻译
1. 百度翻译
百度翻译API
请求
通用翻译API HTTP地址:http://api.fanyi.baidu.com/api/trans/vip/translate
通用翻译API HTTPS地址:https://fanyi-api.baidu.com/api/trans/vip/translate
完整请求示例为:http://api.fanyi.baidu.com/api/trans/vip/translate?q=apple&from=en&to=zh&appid=2015063000000001&salt=1435660288&sign=f89f9594663708c1605f3d736d01d2d4
下面我们需要拼接这个url请求,官方解释如下:
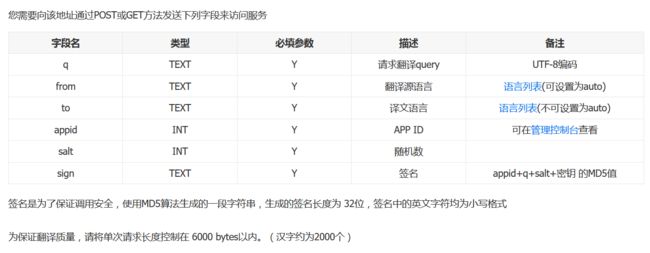
-
q:请求翻译query,例如文字识别出的文字
注:若翻译多个单词或者多段文本,需要发送请求之前对q字段做URL encode,
urllib.parse.quote(q) -
from:翻译源语言,语言选择代码见官方文档,常见的有:auto-自动检测,zh-中文,en-英文
-
to:译文语言 注:不可设置为auto
-
appid: APP ID
-
salt:随机数 例如 salt = random.randint(1, 65536)
-
sign:签名 appid+q+salt+密钥 的MD5值
def get_md5(data): sign = hashlib.md5(data.encode(encoding='UTF-8')).hexdigest() return sign data = appID + q + str(salt) + secretKEY sign = get_md5(data)
解析返回数据
返回示例
{
"from": "en",
"to": "zh",
"trans_result": [
{
"src": "apple",
"dst": "苹果"
}
]
}
| from | TEXT | 翻译源语言 |
|---|---|---|
| to | TEXT | 译文语言 |
| trans_result | MIXED LIST | 翻译结果 |
| src | TEXT | 原文 |
| dst | TEXT | 译文 |
注:若返回的是response.text,在解析时,需要将字符串转化为json,json_result = json.loads(result)
至此,百度通用翻译已完成,详细阅读官方文档
2. 有道翻译(与百度翻译类似)
有道翻译API
请求
有道翻译API HTTP地址:http://openapi.youdao.com/api
有道翻译API HTTPS地址:https://openapi.youdao.com/api
完整请求示例为:http://openapi.youdao.com/api?q=good&from=EN&to=zh_CHS&appKey=ff889495-4b45-46d9-8f48-946554334f2a&salt=2&sign=1995882C5064805BC30A39829B779D7B
| 字段名 | 类型 | 含义 | 必填 | 备注 |
|---|---|---|---|---|
| q | text | 要翻译的文本 | True | 必须是UTF-8编码 |
| from | text | 源语言 | True | 语言列表 (可设置为auto) |
| to | text | 目标语言 | True | 语言列表 (可设置为auto) |
| appKey | text | 应用 ID | True | 可在 应用管理 查看 |
| salt | text | 随机数 | True | |
| sign | text | 签名,通过md5(appKey+q+salt+应用密钥)生成 | True | appKey+q+salt+应用密钥的MD5值 |
| ext | 翻译结果音频格式,支持mp3 | false | mp3 | |
| voice | 翻译结果发音选择,0为女声,1为男声,默认为女声 | false | 0 |
* 来自官方文档
中英文语言代码:zh-CHS-中文,EN-英文,更多见 支持语言表
具体请求操作与百度翻译类似,就不赘述了。
解析返回数据
官方示例如下:
{
"errorCode":"0",
"query":"good", //查询正确时,一定存在
"translation": [ //查询正确时一定存在
"好"
],
"basic":{ // 有道词典-基本词典,查词时才有
"phonetic":"gʊd"
"uk-phonetic":"gʊd" //英式音标
"us-phonetic":"ɡʊd" //美式音标
"uk-speech": "XXXX",//英式发音
"us-speech": "XXXX",//美式发音
"explains":[
"好处",
"好的"
"好"
]
},
"web":[ // 有道词典-网络释义,该结果不一定存在
{
"key":"good",
"value":["良好","善","美好"]
},
{...}
]
],
"dict":{
"url":"yddict://m.youdao.com/dict?le=eng&q=good"
},
"webdict":{
"url":"http://m.youdao.com/dict?le=eng&q=good"
},
"l":"EN2zh-CHS",
"tSpeakUrl":"XXX",//翻译后的发音地址
"speakUrl": "XXX" //查询文本的发音地址
}
与百度翻译类似,若返回的是response.text,需要将字符串转化为json
接下来就是根据需要,解析json从而获得想要的结果。
至此,有道通用翻译已完成,详细阅读官方文档
五、 获取剪贴板的图片
from PIL import Image,ImageGrab
im = ImageGrab.grabclipboard()
if isinstance(im,Image.Image):
pass
ImageGrab.grabclipboard() 获取剪贴板的快照对象, 调用isinstance() 判断是否为图片。
-
如何将剪贴板的图片对象传入到百度文字识别函数中?
将读到的图片对象写入到内存字节缓冲区中,然后百度文字识别函数从内存字节缓冲区中读取到图片进行识别
# 获取剪贴板中的图片 def ocr_clipboard(): # 获取剪切板对象 im = ImageGrab.grabclipboard() # 如果是 Image对象 if isinstance(im, Image.Image): # 写入到内存中 mf = io.BytesIO() # 临时保存 im.save(mf, 'PNG') # 将流位置初始化到0 mf.seek(0)以上,将mf对象传给百度文字识别函数
# 读取图片 def ocr(imagePath): # 如果读取的是截图 内存字节流 if isinstance(imagePath,io.BytesIO): # 将流位置初识化到0 imagePath.seek(0) # 读取图片内容 image = imagePath.read() else: # 如果读到的本地图片地址 调用文件读取函数 image = get_file_content(imagePath)
六、程序界面设计
感觉整个项目过程中,属图形界面最花时间,也是最让我烦恼的。不过说到底还是对tkinter不熟悉,需要用的时候都是现查。虽然之前做过一个小demo–天气查询,基础功能已实现,看起来很low。
初始设计图如下:
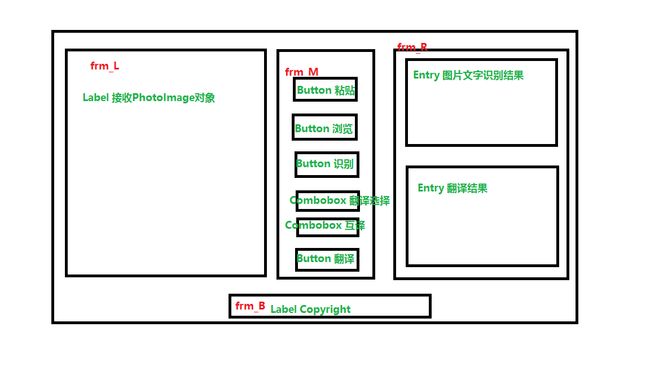
效果图如下(还存在一些问题):

七、功能实现
1. 按照设计图填充控件
(1)窗体初始化
root = tk.Tk()
# 获取窗体大小
# root.winfo_height()
# root.winfo_width()
# 设置窗口标题 TITLE
root.title(TITLE)
# 获取屏幕分辨率
cx_screen = GetSystemMetrics(0)
cy_screen = GetSystemMetrics(1)
# 设置 窗口大小
window_width = cx_screen * 0.8
window_height = cy_screen * 0.7
# 设置窗口起始位置
window_start_x, window_start_y = 20, 20
root.geometry('%dx%d+%d+%d' % (window_width, window_height, window_start_x, window_start_y))
# 设置图标
root.iconbitmap('trans.ico')
(2)主体框架
'''
左边的Frame 图片
中间的Frame 控制区域 粘贴 浏览 识别 下拉列表 翻译按钮
右边的Frame 上 显示识别出的文字 下 显示翻译出的结果
底部的Frame 版权信息
'''
frm = tk.Frame(root)
frm_L = tk.Frame(frm)
frm_M = tk.Frame(frm)
frm_R = tk.Frame(frm)
frm_B = tk.Frame(frm)
frm_L.grid(column=0, row=0)
frm_M.grid(column=1, row=0)
frm_R.grid(column=2, row=0)
frm_B.grid(column=0, row=1,columnspan=3)
(3)左边Frame填充
# 左 Frame
# 默认的图片控件的长宽
w_box = window_width * 0.5
h_box = w_box
lef = tk.Label(frm_L, width=30, height=30,text='')
lef.grid(column=0, row=0, padx=10)
(4)中间Frame填充
# 中 Frame
# 按钮 粘贴
b_paste = ttk.Button(frm_M, text='粘贴', width=12, command=lambda: ocr_clipboard(frm_L, w_box, h_box))
b_paste.grid(column=0, row=0, pady=15)
# 按钮 浏览
b_scan = ttk.Button(frm_M, text='浏览', width=12, command=lambda: scan_image(frm_L, w_box, h_box))
b_scan.grid(column=0, row=1, pady=15)
# 按钮 识别 传入图片的地址
b_ocr = ttk.Button(frm_M, text="识别", width=12, command=lambda: ocr_image(imagePath))
b_ocr.grid(column=0, row=2, pady=15)
# 下拉选择 翻译软件
soft_str = tk.StringVar()
soft_chosen = ttk.Combobox(frm_M, width=10, textvariable=soft_str)
soft_chosen['value'] = ('百度翻译', '有道翻译')
soft_chosen.grid(column=0, row=3, pady=2) # 设置其在界面中出现的位置 column代表列 row 代表行
soft_chosen.current(0)
soft_chosen.bind("<>" , show_msg(soft_str))
# 下拉选择 互译
lang_str = tk.StringVar()
lang_chosen = ttk.Combobox(frm_M, width=10, textvariable=lang_str)
lang_chosen['value'] = ('英译中', '中译英')
lang_chosen.grid(column=0, row=4, pady=2)
lang_chosen.current(0)
lang_chosen.bind("<>" , show_msg(lang_str))
# 按钮 翻译
b_trans = ttk.Button(frm_M, text='翻译', width=12, command=lambda: trans(soft_chosen.get(),lang_chosen.get(), label_ocr))
b_trans.grid(column=0, row=5, pady=15)
以上控件会涉及到一些函数
-
ocr_clipboard()
从剪贴板获取图片,第四章已经提到了,补充 图片自适应窗体大小
# 打开 内存字节流文件 图片 im_obj = Image.open(mf) # 图片自适应 pil_image_resized = resize(w_box, h_box, im_obj) # 将 缩放后的图片 传递给ImageTk tkImage = ImageTk.PhotoImage(image=pil_image_resized, size=30) # label显示图片 lb_image = tk.Label(frm_L, width=w_box, height=h_box, image=tkImage) lb_image.grid(column=0, row=0, padx=10)-
resize()
# 缩放图片 # 传入 图片控件的长宽和图片文件 def resize(w_box, h_box, pil_image): ''' resize a pil_image object so it will fit into a box of size w_box times h_box, but retain aspect ratio 对一个pil_image对象进行缩放,让它在一个矩形框内,还能保持比例 ''' # 获取图片的长宽 w, h = pil_image.size # 获取 图片控件与原始图片的缩放比例 f1 = 1.0 * w_box / w f2 = 1.0 * h_box / h # 比较 长宽 获取较小的值 factor = min([f1, f2]) # print(f1, f2, factor) # test # use best down-sizing filter width = int(w * factor) height = int(h * factor) # print(width,height) return pil_image.resize((width, height), Image.ANTIALIAS)
-
-
scan_image()
# 调用浏览文件函数 def scan_image(frm_L, w_box, h_box): # 打开文件 imagePath = filedialog.askopenfilename() if imagePath.endswith(('.png', 'jpg', 'jpeg', '.bmp')): pilImage = Image.open(imagePath) # 图片自适应 pil_image_resized = resize(w_box, h_box, pilImage) # 将 缩放后的图片 传递给tk tkImage = ImageTk.PhotoImage(image=pil_image_resized, size=30) # label显示图片 lb_image = tk.Label(frm_L, width=w_box, height=h_box, image=tkImage) print(w_box,h_box) lb_image.grid(column=0, row=0, padx=10) else: # 注如果打开文件时 点击'取消',返回 '' messagebox.showinfo(title='警告', message='请重新选择图片文件') -
ocr_image()
# 调用识别图片函数 def ocr_image(imagePath): text = ocr.ocr(imagePath) label_ocr.delete(1.0, tk.END) label_ocr.insert(1.0, text)-
ocr()
调用第二章中的百度图片文字识别
-
-
show_msg()
# 调用下拉框 返回下拉框选择值 def show_msg(obj): return obj.get() -
trans()
# 调用翻译函数 def trans(soft,lang, label_ocr): text = ocr.translate(soft, lang, label_ocr.get('1.0', tk.END)) label_trans.delete(1.0, tk.END) label_trans.insert('1.0', text)-
translate()
调用第三章中的文字翻译函数
-
(5)右边Frame填充
# 右 Frame
global label_ocr
label_ocr = tk.Text(frm_R, width=60, height=8, state='normal')
label_ocr.grid(row=0, pady=10, padx=10)
global label_trans
label_trans = tk.Text(frm_R, width=60, height=8, state='normal')
label_trans.grid(row=1, pady=10, padx=10)
(6)底部Frame填充
# 底部 版权 COPYRIGHT
copy_right = tk.Label(frm_B,width=20,height=2,text=COPYRIGHT)
copy_right.grid(row=0,column=0)
2. 补充——设置代理(存在问题)
在调用识别、翻译时都是需要网络的,在特殊情况下,本地网络需要走代理,这时需要灵活地设置代理功能。想法是设计一个类似微信客户端的代理设置界面(弹窗设置)。
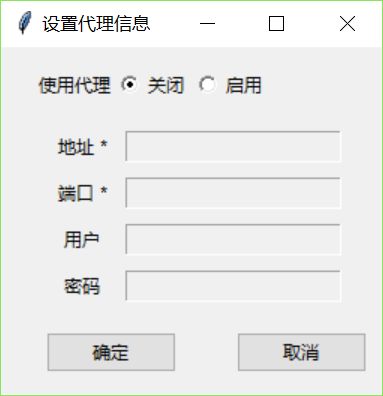

整体效果:

(1)新建agent.py文件
import tkinter as tk
from tkinter import ttk
# 设置代理 弹窗
class MyAgentDialog(tk.Toplevel):
def __init__(self):
super().__init__()
self.title('设置代理信息')
# 弹窗界面
self.setup_UI()
self.agent_info = None
def setup_UI(self):
# 顶部 Frame
frm_T = tk.Frame(self)
frm_T.grid(column=0,row=0,padx=10)
ttk.Label(frm_T, text='使用代理').grid(column=0, row=0, pady=15)
self.radVar = tk.IntVar()
r_no_use = tk.Radiobutton(frm_T, text='关闭', variable=self.radVar, value=0, command=lambda: self.close_agent())
r_no_use.grid(column=1, row=0)
r_use = tk.Radiobutton(frm_T, text='启用', variable=self.radVar, value=1, command=lambda: self.open_agent())
r_use.grid(column=2, row=0)
# 中部 Frame
frm_M = tk.Frame(self)
frm_M.grid(column=0, row=1, columnspan=3)
ttk.Label(frm_M, text='地址 *').grid(column=0, row=0, pady=5, padx=10, sticky='W')
self.s_addr = tk.StringVar()
self.e_addr = tk.Entry(frm_M, textvariable=self.s_addr, state='disabled')
self.e_addr.grid(column=1, row=0, columnspan=2, sticky='W,E')
ttk.Label(frm_M, text='端口 *').grid(column=0, row=1, pady=5)
self.s_port = tk.StringVar()
self.e_port = tk.Entry(frm_M, textvariable=self.s_port, state='disabled')
self.e_port.grid(column=1, row=1, columnspan=2)
ttk.Label(frm_M, text='用户').grid(column=0, row=2, pady=5)
self.s_user = tk.StringVar()
self.e_user = tk.Entry(frm_M, textvariable=self.s_user, state='disabled')
self.e_user.grid(column=1, row=2, columnspan=2)
ttk.Label(frm_M, text='密码').grid(column=0, row=3, pady=5)
self.s_passwd = tk.StringVar()
self.e_passwd = tk.Entry(frm_M, show='*', textvariable=self.s_passwd, state='disabled')
self.e_passwd.grid(column=1, row=3, columnspan=2)
# 底部Frame
frm_B = tk.Frame(self)
frm_B.grid(column=0, row=5, columnspan=3)
b_ok = ttk.Button(frm_B, text='确定', command=lambda: self.ok())
b_ok.grid(column=0, row=0, pady=15, padx=30)
b_cancel = ttk.Button(frm_B, text='取消', command=lambda: self.cancel())
b_cancel.grid(column=1, row=0, pady=15, padx=10)
# 关闭代理 Entry 不可编辑状态
def close_agent(self):
self.e_addr.config(state='disabled')
self.e_port.config(state='disabled')
self.e_user.config(state='disabled')
self.e_passwd.config(state='disabled')
# 开启代理 Entry 可编辑
def open_agent(self):
self.e_addr.config(state='normal')
self.e_port.config(state='normal')
self.e_user.config(state='normal')
self.e_passwd.config(state='normal')
# 确定按钮 Entry中的值
def ok(self):
self.agent_info = [self.s_addr.get(),self.s_port.get(),self.s_user.get(),self.s_passwd.get()]
self.destroy() # 销毁窗口
def cancel(self):
self.agent_info = None
self.destroy()
(2)主窗体调用设置代理弹窗
主窗体添加设置代理按钮
# 底部 设置代理
b_proxy = ttk.Button(frm_M,text="设置代理", width=12, command=lambda: self.set_proxy())
b_proxy.grid(column=0,row=6)
-
set_proxy()
def set_proxy(): # 接收返回数据 agent = get_info()-
get_info()
import agent def get_info(self): # 导入agent.py中的类 MyAgentDialog inputDialog = agent.MyAgentDialog() inputDialog.setup_UI() # 等待窗口 destroy 返回数据 inputDialog.wait_window() # 返回 agent数据 return inputDialog.agent_info
-
(3)修改网络调用的函数(添加代理)
在百度识图和翻译调用函数中,需要传输代理参数。具体如何添加就不多讲了,
# proxies = set_proxy(agent)
# 调用百度文字识别client
# client.setProxies(proxies)
# 翻译调用请求
# response = requests.get(myurl, headers=headers, proxies=proxies)
-
set_proxy()
解析agent,获取addr,port,user,passwd即可,注proxies是字典类型
八、未解决的问题
如何保存代理配置?
重新打开程序的时候,代理设置就会被初始化(初始化代理状态是关闭)。
如果是读取配置文件,那么程序运行后会生成一个config文件;但初衷是只打包成一个exe文件,双击即可运行。
界面控件问题
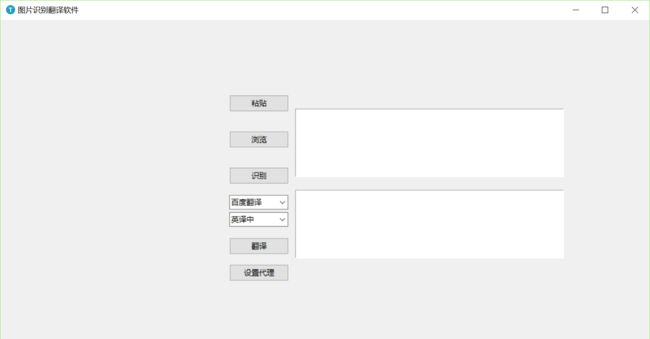
程序初始运行,窗体如上图所示,左侧图片控件内容为空时,未加载指定大小,若插入图片后,左侧Frame会扩展为指定大小,中部和右侧Frame会向右移动,见第五章的程序界面设计效果图;而且底部Frame未显示,需要手动向下放大才能显示Label(Copyright)。不知如何解决,tkinter的窗口调试太麻烦了。
界面美化
界面如同90年代的Windows 98风格(笑哭),太丑了(无力吐槽)。
以上问题欢迎提供解决方案
参考
Python图像处理库PIL的ImageGrab模块介绍
python界面上的图片缩放,根据窗口大小
tkinter Combobox组件
获取屏幕及桌面大小
Python tkinter模块弹出窗口及传值回到主窗口操作详解