torch与tensorflow adam收敛速度对比(bert文本分类)
@[TOC](torch与tensorflow adam收敛速度对比(bert文本分类))
工作中一直使用tf2,但是现在很多新的模型都是基于torch实现的,这样很难快速(麻烦)copy一些最新的模型应用到工程实践中。一直想全部基于torch来开发,这样引进新技术相对方便一些。
基于之前的关系抽取demo,简单实现了现有项目的torch代码,但是发现在数据集上并没有优化, 具体是: 经过3个epoch,训练和验证集loss并未有大的变化(数据集到千万级,每个epoch需要时间太长).
开始一步一步排查问题,最终发现并非没有优化,而是adam在两个框架下其收敛速度是有明显差别的
具体便实现了下面一个小的demo来比较两个框架优化过程。预训练模型使用哈工大中RoBERTa-wwm-ext, Chinese。
整体上模型最简化,就是bert + maxpool+dense(3)这样的最简单分类模型。
另外为了保证一致性,这里也对torch中的dense层应用与tf一致的权重初始化方式。
另外两adam优化器默认参数eps不一致,这里设置torch保持与tf一致。
除了bert(但是都是采用预训练权重),模型其余部分已经尽量保持一致。
为控制模型一致,这里保持训练数据batchsize一致,并且关闭shuffle。
只包含训练数据,优化目标就是在训练数据上快速拟合。(bert模型很大,数据只有100条,很快就可以过拟合)
具体代码数据见github
鄙人实验结论: adam优化器(默认设置)优化效果: tf > torch
证实: adam > sgd
后文贴上code并粘贴结果记录
test_tf.py
#!/usr/bin/env python
# coding: utf-8
import os
import json
import numpy as np
os.environ['TF_KERAS'] = '1'
import tensorflow as tf
from keras_bert import load_trained_model_from_checkpoint
GPU = '4'
pretrained_path = '../basedata/chinese_roberta_wwm_ext_L-12_H-768_A-12'
train_data_path = 'data/sample.json'
os.environ["CUDA_VISIBLE_DEVICES"] = GPU
config_path = os.path.join(pretrained_path, 'bert_config.json')
checkpoint_path = os.path.join(pretrained_path, 'bert_model.ckpt')
SEQ_LEN = 256
def load_from_json(filename):
print('loading data from json :', filename)
wordids, segmentids, labels = [], [], []
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i % 100000 == 0 and i != 0:
print('载入数据:%d ' % i)
item = json.loads(line.strip())
labels.append(item['label'])
wordids.append(item['wordids'])
wordids = np.array(wordids)
segmentids = np.zeros_like(wordids)
labels = tf.keras.utils.to_categorical(labels)
return [wordids, segmentids], labels
def create_model(bert_train=False):
bert = load_trained_model_from_checkpoint(
config_path, checkpoint_path,
training=False,
trainable=bert_train,
seq_len=SEQ_LEN, )
inputs = bert.inputs[:2]
dense = bert.get_layer('Encoder-12-FeedForward-Norm').output
dense = tf.keras.layers.Lambda(lambda x: x[:, 1:-1, :])(dense)
dense = tf.keras.layers.GlobalMaxPool1D()(dense)
output2 = tf.keras.layers.Dense(
units=3, activation='softmax', name='3cls')(dense)
return tf.keras.models.Model(inputs, output2)
model = create_model(bert_train=True)
for layer in model.layers:
layer.trainable = True
train_X, train_Y = load_from_json(train_data_path)
optimizer = tf.keras.optimizers.Adam(2e-5)
# optimizer = tf.keras.optimizers.SGD(learning_rate=2e-5, momentum=0.9)
loss = tf.keras.losses.CategoricalCrossentropy()
model.compile(optimizer, loss=loss)
model.fit(train_X, train_Y,
epochs=100, batch_size=32, shuffle=False)
test_torch.py
#!/usr/bin/env python
# coding: utf-8
import math
from tqdm import tqdm
from utils import RunningAverage
import torch.optim as optim
from transformers import BertModel, BertConfig
from transformers.optimization import AdamW
import torch.nn.functional as F
from torch import nn
import torch
import numpy as np
import json
import os
import time
GPU = '5'
pretrained_path = '../basedata/chinese_roberta_wwm_ext_pytorch'
train_data_path = 'data/sample.json'
config_path = os.path.join(pretrained_path, 'bert_config.json')
SEQ_LEN = 256
os.environ["CUDA_VISIBLE_DEVICES"] = GPU
def initialize_weights(net):
def weights_init(m):
# torch.nn.init.xavier_uniform_(m.weight)
limit=pow(6/(768+3),0.5)
torch.nn.init.uniform_(m.weight,-limit,limit)
for m in net.children():
if m != net.bert:
if type(m) == nn.Linear:
m.apply(weights_init)
class RunningAverage():
"""A simple class that maintains the running average of a quantity"""
def __init__(self):
self.steps = 0
self.total = 0
def update(self, val):
self.total += val
self.steps += 1
def __call__(self):
return self.total / float(self.steps)
class DataGenerator():
@staticmethod
def load_from_json(filename):
wordids, labels = [], []
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i % 100000 == 0 and i != 0:
print('载入数据:%d ' % i)
item = json.loads(line.strip())
labels.append(item['label'])
wordids.append(item['wordids'])
return wordids, labels
def __init__(self):
self.data, self.labels = self.load_from_json(train_data_path)
self.batchsize = 32
self.size = math.ceil(len(self.data) / self.batchsize)
def get_data(self):
for i in range(self.size):
ifrom = i * self.batchsize
ito = (i + 1) * self.batchsize
yield [torch.from_numpy(np.array(self.data[ifrom:ito])),
torch.from_numpy(np.array(self.labels[ifrom:ito]))]
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
config = BertConfig.from_pretrained(
os.path.join(pretrained_path, 'bert_config.json'))
self.bert = BertModel(config)
self.fc1 = nn.Linear(768, 3)
self.loss = nn.CrossEntropyLoss()
if GPU != '':
self.cuda()
def forward(self, words):
dense = torch.max(self.bert(words)[0][:, 1:-1, :], 1)[0]
dense = self.fc1(dense)
return dense
model = Model()
initialize_weights(model)
for i in model.bert.parameters():
i.requires_grad=True
model.train()
optimizer = optim.Adam(model.parameters(), lr=2e-5, eps=1e-7)
# optimizer = optim.SGD(model.parameters(), lr=2e-5,momentum=0.9)
data_gen = DataGenerator()
for epoch in range(1, 100):
loss_avg = RunningAverage()
pbar = tqdm(total=data_gen.size)
for [words, labels] in data_gen.get_data():
if GPU != '':
words = words.cuda()
labels = labels.cuda()
outputs = model(words)
loss = model.loss(outputs, labels)
model.zero_grad()
loss.backward()
optimizer.step()
loss_avg.update(loss.cpu().item())
pbar.update(1)
pbar.set_postfix(
{
'epoch': epoch, 'loss': '{:08.6f}'.format(loss_avg())})
pbar.close()
实验结果
使用adam
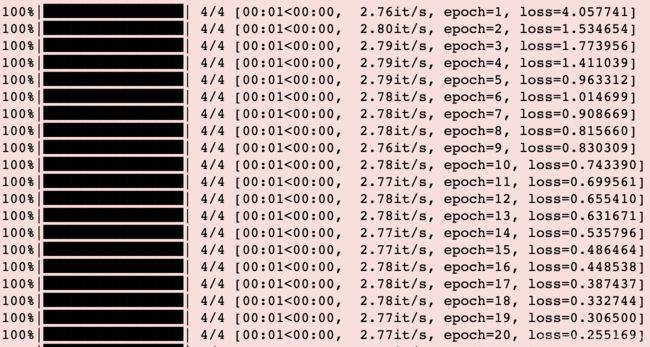
tensorflow经过20epoch, loss达到0.0486。

torch结果,在20 epoch, loss仅仅达到0.25,而tf loss到0.25只用了9 epoch。
torch的loss 达到0.048时已经时33epoch。
使用sgd
使用sgd的结果就比adam差很多(这里没有调整参数,仅参考)
tensorflow结果

torch结果

下面是公众号,欢迎扫描二维码,谢谢关注,谢谢支持!
公众号名称: Python入坑NLP
本公众号主要致力于自然语言处理、机器学习、coding算法以及Python的一些知识分享。本人只是小菜,希望记录自己学习、工作过程的同时,大家一起进步。欢迎交流、分享。
