一文学会Scrapy-redis分布式爬虫项目,初级工程师与中级工程师分水岭之一
文章目录
- 一、Scrapy 简介
-
- (一)Scrapy 架构图
- (二)执行流程
- 二、Scrapy-redis 简介
-
- (一)安装
- (二)客户端和服务端命令
-
- 1、服务端命令
- 2、客户端命令
- 三、redis数据库
-
- 笔记文档摘要
-
- 1、redis特点:
- 2、redis数据类型
- 四、scrapy-redis 分布式
-
- 引入
- (一)分布式原理
- (二)指纹集合
- (三)调度队列
-
- 1、深度优先
- 2、广度优先
- (四)以问题整理思绪
-
- 1、scrapy和scrapy-redis 区别
- 2、为什么scrapy不能分布式调用?
- 3、什么就叫做优先级队列,为什么他能调度我们scrapy各种url?
- 五、scrapy-redis 分布式项目部署(案例-淘车网)
-
- (一)scrapy 单台主机
-
- 1、目标网址与功能需求
- 2、开发步骤
- (二)scrapy-redis 分布式
-
- 开发步骤:
- 部署流程概述:
- 六、尾声
本文截取思维导图部分阐述,Scrapy-redis分布式爬虫项目详细讲解展示

本人自己整理的思维导图 github下载链接:https://github.com/wenwenc9/data_bank.git
内容,从入门到项目开发,全栈方向,个人技术经验总结等等。


一、Scrapy 简介
Scrapy 是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架, 用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 内容以及各种图片,非常方便。
Scrapy 使用了 Twisted(其主要对手是 Tornado)异步网络框架来处理网络通讯,可以加快 我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成 各种需求。
scrapy的优点
1、简化开发
2、加快爬取速度
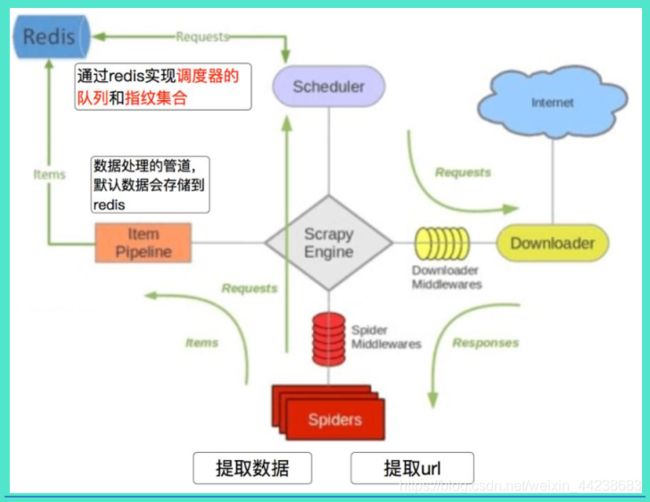
(一)Scrapy 架构图
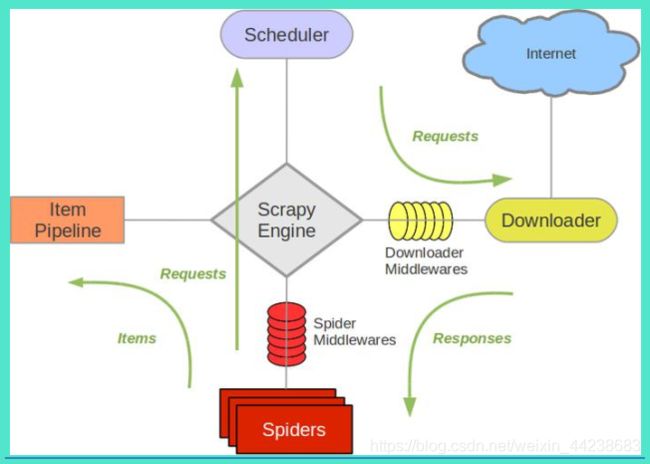

Scrapy Engine(引擎):负责 spider、ItemPipeline、Downloader、Scheduler 中间的通讯, 信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的 Request 请求,并按照一定的方式进 行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载 Scrapy Engine(引擎)发送的所有 Requests 请求,并将 其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 spider 来处理。
spider(爬虫):它负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要 的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器)。
Item Pipeline(管道):它负责处理 spider 中获取到的 Item,并进行后期处理(详细分析、 过滤、存储等)。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能 的组件。
SpiderMiddlewares(spider 中间件):你可以理解为是一个可以自定义扩展和操作引擎 和 spider 中间通信的功能组件(比如进入 spider 的 Response 和从 spider 出去的 Requests)。
(二)执行流程
整个流程通俗而言:
引擎:Hi!spider,你要处理哪一个网站?
spider:老大要我处理 xxxx.com。
引擎:你把第一个需要处理的 URL 给我吧。
spider:给你,第一个 URL 是 xxxxxxx.com。
引擎:Hi!调度器,我这有 request 请求你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的 request 请求给我。
调度器:给你,这是我处理好的 request。
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个 request 请求
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个 request 下载失败了。然后引擎告诉调度器,这个 request 下载失败了,你记录一下,我们待会儿再下载)
引擎:Hi!spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你 自己处理一下(注意!这儿 responses 默认是交给 def parse()这个函数处理的)
spider:(处理完毕数据之后对于需要跟进的 URL),Hi!引擎,我这里有两个结果,这 个是我需要跟进的 URL,还有这个是我获取到的 Item 数据。
引擎:Hi!管道我这儿有个 item 你帮我处理一下!调度器!这是需要跟进 URL 你帮我 处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
管道``调度器:好的,现在就做! 注意:只有当调度器中不存在任何 request 了,整个程序才会停止(也就是说,对于下载 失败的 URL,Scrapy 也会重新下载。)
二、Scrapy-redis 简介
单个电脑我们可以多线程来加快爬取速度
scrapy底层使用异步框架(多线程方式)来进行爬取。 速度很快
使用分布式来加快爬取的速度、—大数据
(一)安装
1、将压缩包解压到指定目录,就可以安装了(到c盘下,因为数据小的原因,并且解压后就简单Redis文件夹命名即可)

2、配置环境变量(windows电脑 path)

3、测试是否安装成功
redis-server

(二)客户端和服务端命令
一般情况下,redis石洞的时候才启动—其它时候都是关闭
1、服务端命令
这里介绍二种启动方式:
① 启动 redis-server 配置文件绝对路径下文件名

② redis-server redis.windows.conf
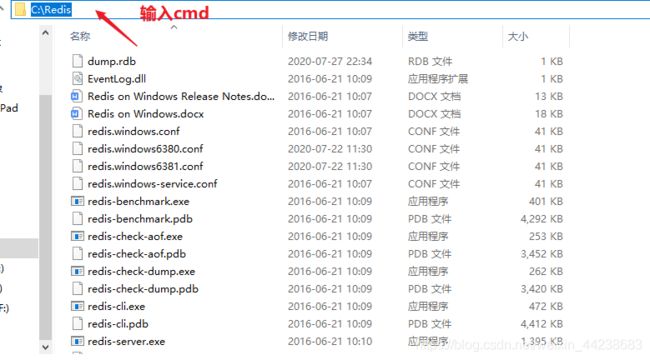

redis的配置文件
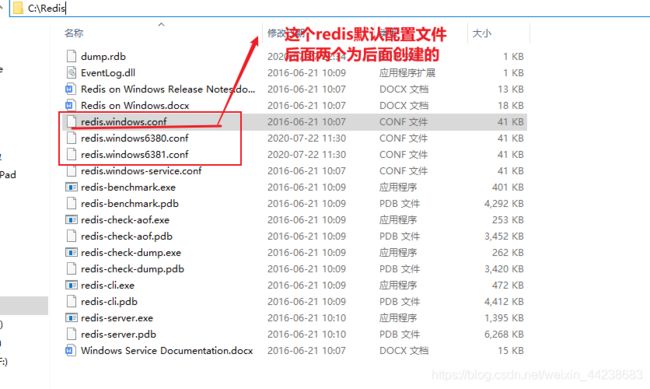
配置文件是redis非常重要的文件,这个文件包含对一个redis服务器的所有设置,我们只需要在这个配置文件中设置好一些信息,启动的时候只需要指定这个文件,那么这个redis服务就会按照我们设置进行启动
一个redis服务器就是一个配置文件
redis的默认端口是6379,这点很重要请记住。
以案例说明6380,9381为什么分别代表两个redis服务器
在6380和6381这个两个端口启动两个redis服务器
1、配置文件和数据是等价,所以我们首先需要复制两个配置,改个名字
复制原来的,改个后缀名即可,6380,6381

2、进入配置文件,更改对应文件的端口号(保存)
记事本打开6380,6381配置文件,更改端口。

3、指定配置文件进行启动指定数据库
如果出现内存不足,指定下即可(–maxheap 200m 指定占用内存200,针对启动错误 一般只要前面的命令即可)
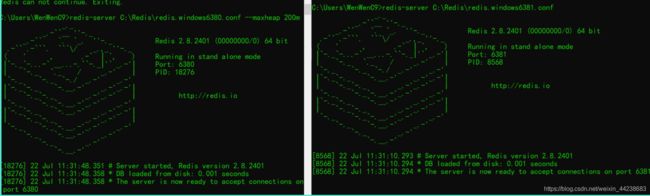
2、客户端命令
前提服务端已经打开
redis-cli -p 端口名
分别连接刚刚创建的6380和6381端口下的redis数据

三、redis数据库
本文使用redis数据可视工具如下,即通过此工具更好的展示

redis数据库有道云详细介绍
http://note.youdao.com/noteshare?id=c69ddd68d9a40a1f03221b09d4dad7cc&sub=31B4A310F2434D2F9465687DBC18DDB6
初学者一定要看上面的文档内容,再继续看下文,否则无法理解
我从笔记中摘出会在后文运用到的内容
笔记文档摘要
1、redis特点:
- redis的数据结构非常丰富,所以他的功能非常多
- 读写速度快
- 持久化
- 队列
2、redis数据类型
list
list最大功能是可以实现栈和队列(请记住这个,部署用到)

sets 集合
特点:
- Set是一个string类型无序集合,不允许重复
- 不允许重复添加
添加:
- sadd 成功返回1,失败返回0


有序集合 zset
特点:
- 成功返回1,失败返回0

- 在数据可视化工具中能够看到自动生成score字段

- 同样的是由sets升级而来,所以存入进去就1,失败0

命名空间
可以用于多个项目开发下,使用重复名称而不影响
在scarpy中也可以是分布式的保存主机,将主机开启的任务放到list中


上述总结文档所提及内容
list 具有栈和队列特性
sets集合 剔重
zset集合 提供score 自动排序
命名空间 应对可以在一个多个不同文件夹中 取相同名称的变量, 或者表名某个文件夹下存储什么
【弄清楚这些是什么?】 【再看后文】
四、scrapy-redis 分布式
引入
常规爬取一个网站,都是在一台电脑下完成:
- 单线程 简单网站
- 多线程 数据稍微多
可是以上方法,对于一个数据非常庞大的网站,一台电脑的速度,可能要爬好几天,那么如果能够多台电脑同时执行一个项目爬取脚本,爬取的数据存储到一块并且能够剔重那就好了!
于是出现分布式
(一)分布式原理
scrapy-redis分布式框架就是在scrapy基础上增加了redis组件,那么这个redis组件的功能就是scrapy和scrapy-redis主要区别
redis组件中有着指纹集合和调度队列
(二)指纹集合

传统爬取数据出现的问题:
- 目标网址的数据过于庞大
- 现在有电脑四台,如何联合爬取一个目标网址
- 每个电脑都是在爬取同一个网址,并且存储的数据不能重复,这个问题该如何解决?
- 使用多线程,多部电脑配合爬取,分配自己的爬取的任务范围,最后组合成总数据,难度大
list数据类型具有 栈和队列的特点(回顾下redis数据库中list特性)

- 这里的list就是当成python中list 通过range 获取值,并没有像pop弹出这个值,值还在【】中
- 栈 先入后出
- 队列 先入先出
- list是双向链表
针对传统问题,采用scrapy+redis数据库 即scrapy-redis
- 主机将任务放到 redis 数据库中,以list类型存储
- 这些任务如url,爬取一万个页面数据,一个一个存储redis库以list类型
- 【url1,url2,url3,。。。。。】
- 那么主机下发了任务(主机也能启动项目爬取数据),剩下的三台电脑为从机
- 从机也运行同一个项目,如主机是第一个访问爬取url1的数据,那么就会取出url1 (取出还在list中)
- 到redis数据库中,执行命令
sadd <指纹集合> url1 ,成功存入 响应结果 1表示之前没有 - 现在从机b也从list中取数据,从url1开始继续取,然后到redis数据库
执行命令 sadd <指纹集合> url1 ,数据重复 响应结果 0 - 那么从机b,就继续从list中,假如为url2 ,继续上面到redis中步骤,成功或失败
- 指纹集合是zset集合,遵从不可重复
(三)调度队列

1、深度优先
普通爬虫遵循的是 深度优先
比如爬取一个网站,分为三类 url
- 第一层 首页 url 图中描述为 0
- 第二层 首页有很多分页 url 图中描述为 1
- 第三层 分页面下有很多商品详情 url 图中描述为 2
那么普通爬虫,执行的事情必须从首页再到分页1列表再到某个商品详情,从上到下
2、广度优先
scrapy 遵循的是广度优先
即每一层的url爬取完毕,才到下一层,一层一层而来
scrapy-redis 分布式
从理论上,遵循一层一层爬取
但是分布式为多太电脑,如果A电脑在分页1,分页1有20个商品,A电脑才爬取完 4个 url
那么电脑B 可能会拿着这4个url,去执行下一步的操作(这一层还么没有爬取完毕 )
看似深度优先(违背广度优先),但是对于每台电脑而言,还是遵循广度优先,从已知获取的url,默认为一层
并且,最终以scrapy 的队列模式 0 1 2 优先级,转存到redis中zset,还是根据每一层(遵循广度优先),因为score的字段自动排序,任务优先级,遵从广度优先,即我
这也是为什么,能够看到在爬取每页url,时候,可能就获取到了某个商品详情信息
(四)以问题整理思绪
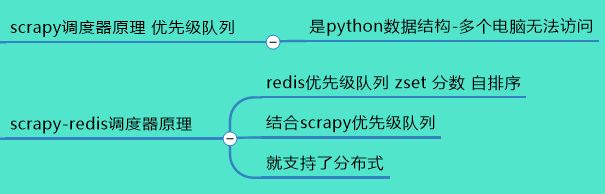
1、scrapy和scrapy-redis 区别
scrapy 如果将url1存入到变量 list中,为主机电脑的内存
外部电脑无法访问此变量
scrapy 将url1 存放到redis数据库list,外部电脑能够访问
并且,存储的url1,将入A电脑完成了,B电脑去数据库做指纹集合,发现A电脑已经取出url1做了指纹标记,那么就会跳过此url1.
2、为什么scrapy不能分布式调用?

3、什么就叫做优先级队列,为什么他能调度我们scrapy各种url?
因为redis数据库中存储为,zset集合,存入的时候
生成了一个score字段自动排序,参考调度队列图
五、scrapy-redis 分布式项目部署(案例-淘车网)
(一)scrapy 单台主机
项目代码,在我的github仓库,自取,环境依赖包在txt中。
https://github.com/wenwenc9/data_bank.git

1、目标网址与功能需求
目标网址: http://quanguo.taoche.com/all/ 淘车网

网页分析,实现功能:
每个地区下,每种车的,每一页详情信息
 底部分页图
底部分页图

在上面,明确了
目标网址:http://quanguo.taoche.com/all/
爬取数据: 每一个地区下,每种车的每一页的信息
2、开发步骤
创建一个scrapy项目(不会scrapy的去面壁)
scrapy startpeoject taoche 创建项目
scrapy crawl taoche_spider www 创建脚本

城市列表,汽车类型列表数据,已做处理,提前准备好(因为发现,每个城市,每个车类型的每一页是通过拼接url而成),意思真正意义上要实现的是分页功能

CITY_CODE = ['quanguo', 'shijiazhuang', 'tangshan', 'qinhuangdao', 'handan', 'xingtai', 'baoding', 'zhangjiakou',
'chengde', 'cangzhou', 'langfang', 'hengshui', 'taiyuan', 'datong', 'yangquan', 'changzhi', 'jincheng',
'shuozhou', 'jinzhong', 'yuncheng', 'xinzhou', 'linfen', 'lvliang', 'huhehaote', 'baotou', 'wuhai',
'chifeng', 'tongliao', 'eerduosi', 'hulunbeier', 'bayannaoer', 'wulanchabu', 'xinganmeng',
'xilinguolemeng', 'alashanmeng', 'changchun', 'jilin', 'hangzhou', 'ningbo', 'wenzhou', 'jiaxing',
'huzhou', 'shaoxing', 'jinhua', 'quzhou', 'zhoushan', 'tz', 'lishui', 'bozhou', 'chizhou', 'xuancheng',
'nanchang', 'jingdezhen', 'pingxiang', 'jiujiang', 'xinyu', 'yingtan', 'ganzhou', 'jian', 'yichun', 'jxfz',
'shangrao', 'xian', 'tongchuan', 'baoji', 'xianyang', 'weinan', 'yanan', 'hanzhong', 'yl', 'ankang',
'shangluo', 'lanzhou', 'jiayuguan', 'jinchang', 'baiyin', 'tianshui', 'wuwei', 'zhangye', 'pingliang',
'jiuquan', 'qingyang', 'dingxi', 'longnan', 'linxia', 'gannan', 'xining', 'haidongdiqu', 'haibei',
'huangnan', 'hainanzangzuzizhizho', 'guoluo', 'yushu', 'haixi', 'yinchuan', 'shizuishan', 'wuzhong',
'guyuan', 'zhongwei', 'wulumuqi', 'kelamayi', 'shihezi', 'tulufandiqu', 'hamidiqu', 'changji', 'boertala',
'bazhou', 'akesudiqu', 'xinjiangkezhou', 'kashidiqu', 'hetiandiqu', 'yili', 'tachengdiqu', 'aletaidiqu',
'xinjiangzhixiaxian', 'changsha', 'zhuzhou', 'xiangtan', 'hengyang', 'shaoyang', 'yueyang', 'changde',
'zhangjiajie', 'yiyang', 'chenzhou', 'yongzhou', 'huaihua', 'loudi', 'xiangxi', 'guangzhou', 'shaoguan',
'shenzhen', 'zhuhai', 'shantou', 'foshan', 'jiangmen', 'zhanjiang', 'maoming', 'zhaoqing', 'huizhou',
'meizhou', 'shanwei', 'heyuan', 'yangjiang', 'qingyuan', 'dongguan', 'zhongshan', 'chaozhou', 'jieyang',
'yunfu', 'nanning', 'liuzhou', 'guilin', 'wuzhou', 'beihai', 'fangchenggang', 'qinzhou', 'guigang',
'yulin', 'baise', 'hezhou', 'hechi', 'laibin', 'chongzuo', 'haikou', 'sanya', 'sanshashi', 'qiongbeidiqu',
'qiongnandiqu', 'hainanzhixiaxian', 'chengdu', 'zigong', 'panzhihua', 'luzhou', 'deyang', 'mianyang',
'guangyuan', 'suining', 'neijiang', 'leshan', 'nanchong', 'meishan', 'yibin', 'guangan', 'dazhou', 'yaan',
'bazhong', 'ziyang', 'aba', 'ganzi', 'liangshan', 'guiyang', 'liupanshui', 'zunyi', 'anshun',
'tongrendiqu', 'qianxinan', 'bijiediqu', 'qiandongnan', 'qiannan', 'kunming', 'qujing', 'yuxi', 'baoshan',
'zhaotong', 'lijiang', 'puer', 'lincang', 'chuxiong', 'honghe', 'wenshan', 'xishuangbanna', 'dali',
'dehong', 'nujiang', 'diqing', 'siping', 'liaoyuan', 'tonghua', 'baishan', 'songyuan', 'baicheng',
'yanbian', 'haerbin', 'qiqihaer', 'jixi', 'hegang', 'shuangyashan', 'daqing', 'yc', 'jiamusi', 'qitaihe',
'mudanjiang', 'heihe', 'suihua', 'daxinganlingdiqu', 'shanghai', 'tianjin', 'chongqing', 'nanjing', 'wuxi',
'xuzhou', 'changzhou', 'suzhou', 'nantong', 'lianyungang', 'huaian', 'yancheng', 'yangzhou', 'zhenjiang',
'taizhou', 'suqian', 'lasa', 'changdudiqu', 'shannan', 'rikazediqu', 'naqudiqu', 'alidiqu', 'linzhidiqu',
'hefei', 'wuhu', 'bengbu', 'huainan', 'maanshan', 'huaibei', 'tongling', 'anqing', 'huangshan', 'chuzhou',
'fuyang', 'sz', 'chaohu', 'luan', 'fuzhou', 'xiamen', 'putian', 'sanming', 'quanzhou', 'zhangzhou',
'nanping', 'longyan', 'ningde', 'jinan', 'qingdao', 'zibo', 'zaozhuang', 'dongying', 'yantai', 'weifang',
'jining', 'taian', 'weihai', 'rizhao', 'laiwu', 'linyi', 'dezhou', 'liaocheng', 'binzhou', 'heze',
'zhengzhou', 'kaifeng', 'luoyang', 'pingdingshan', 'jiyuan', 'anyang', 'hebi', 'xinxiang', 'jiaozuo',
'puyang', 'xuchang', 'luohe', 'sanmenxia', 'nanyang', 'shangqiu', 'xinyang', 'zhoukou', 'zhumadian',
'henanzhixiaxian', 'wuhan', 'huangshi', 'shiyan', 'yichang', 'xiangfan', 'ezhou', 'jingmen', 'xiaogan',
'jingzhou', 'huanggang', 'xianning', 'qianjiang', 'suizhou', 'xiantao', 'tianmen', 'enshi',
'hubeizhixiaxian', 'beijing', 'shenyang', 'dalian', 'anshan', 'fushun', 'benxi', 'dandong', 'jinzhou',
'yingkou', 'fuxin', 'liaoyang', 'panjin', 'tieling', 'chaoyang', 'huludao', 'anhui', 'fujian', 'gansu',
'guangdong', 'guangxi', 'guizhou', 'hainan', 'hebei', 'henan', 'heilongjiang', 'hubei', 'hunan', 'jl',
'jiangsu', 'jiangxi', 'liaoning', 'neimenggu', 'ningxia', 'qinghai', 'shandong', 'shanxi', 'shaanxi',
'sichuan', 'xizang', 'xinjiang', 'yunnan', 'zhejiang', 'jjj', 'jzh', 'zsj', 'csj', 'ygc']
# 品牌类型列表
CAR_CODE_LIST = ['southeastautomobile', 'sma', 'audi', 'hummer', 'tianqimeiya', 'seat', 'lamborghini', 'weltmeister',
'changanqingxingche-281', 'chevrolet', 'fiat', 'foday', 'eurise', 'dongfengfengdu', 'lotus-146', 'jac',
'enranger', 'bjqc', 'luxgen', 'jinbei', 'sgautomotive', 'jonwayautomobile', 'beijingjeep', 'linktour',
'landrover', 'denza', 'jeep', 'rely', 'gacne', 'porsche', 'wey', 'shenbao', 'bisuqiche-263',
'beiqihuansu', 'sinogold', 'roewe', 'maybach', 'greatwall', 'chenggongqiche', 'zotyeauto', 'kaersen',
'gonow', 'dodge', 'siwei', 'ora', 'lifanmotors', 'cajc', 'hafeiautomobile', 'sol', 'beiqixinnengyuan',
'dorcen', 'lexus', 'mercedesbenz', 'ford', 'huataiautomobile', 'jmc', 'peugeot', 'kinglongmotor',
'oushang', 'dongfengxiaokang-205', 'chautotechnology', 'faw-hongqi', 'mclaren', 'dearcc',
'fengxingauto', 'singulato', 'nissan', 'saleen', 'ruichixinnengyuan', 'yulu', 'isuzu', 'zhinuo',
'alpina', 'renult', 'kawei', 'cadillac', 'hanteng', 'defu', 'subaru', 'huasong', 'casyc', 'geely',
'xpeng', 'jlkc', 'sj', 'nanqixinyatu1', 'horki', 'venucia', 'xinkaiauto', 'traum',
'shanghaihuizhong-45', 'zhidou', 'ww', 'riich', 'brillianceauto', 'galue', 'bugatti',
'guagnzhouyunbao', 'borgward', 'qzbd1', 'bj', 'changheauto', 'faw', 'saab', 'fuqiautomobile', 'skoda',
'citroen', 'mitsubishi', 'opel', 'qorosauto', 'zxauto', 'infiniti', 'mazda', 'arcfox-289',
'jinchengautomobile', 'kia', 'mini', 'tesla', 'gmc-109', 'chery', 'daoda-282', 'joylongautomobile',
'hafu-196', 'sgmw', 'wiesmann', 'acura', 'yunqueqiche', 'volvo', 'lynkco', 'karry', 'chtc', 'gq',
'redstar', 'everus', 'kangdi', 'chrysler', 'cf', 'maxus', 'smart', 'maserati', 'dayu', 'besturn',
'dadiqiche', 'ym', 'huakai', 'buick', 'faradayfuture', 'leapmotor', 'koenigsegg', 'bentley',
'rolls-royce', 'iveco', 'dongfeng-27', 'haige1', 'ds', 'landwind', 'volkswagen', 'sitech', 'toyota',
'polarsunautomobile', 'zhejiangkaersen', 'ladaa', 'lincoln', 'weilaiqiche', 'li', 'ferrari', 'jetour',
'honda', 'barbus', 'morgancars', 'ol', 'sceo', 'hama', 'dongfengfengguang', 'mg-79', 'ktm',
'changankuayue-283', 'suzuki', 'yudo', 'yusheng-258', 'fs', 'bydauto', 'jauger', 'foton', 'pagani',
'shangqisaibao', 'guangqihinomotors', 'polestar', 'fujianxinlongmaqichegufenyouxiangongsi',
'alfaromeo', 'shanqitongjia1', 'xingchi', 'lotus', 'hyundai', 'kaiyi', 'isuzu-132', 'bmw', 'ssangyong',
'astonmartin']
分页不先做,后期做分页的时候,修改拼接url即可,先确保能完成前面的

新建一个my_settins.py ,里面为我自己的一些配置,当新建一个my_setting.py 时候会覆盖默认settings.py

import hashlib
CUSTOM_SETTINGS = {
#robotes协议
'ROBOTSTXT_OBEY': False,
#请求头
'DEFAULT_REQUEST_HEADERS' : {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
# 'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
},
#下载中间件
# 'DOWNLOADER_MIDDLEWARES' : {
# 'sh_company.user_agent_middle.User_Agent_Middle': 543,
# },
#pipelines
'ITEM_PIPELINES' :{
'taoche.pipelines.MongoPipeline': 300,
},
#数据库的url
'MONGO_URI' :'localhost',
#数据的名字
'MONGO_DATABASE' :'taoche',
}
def get_md5(value):
return hashlib.md5(value.encode('utf-8')).hexdigest()
def update_to_mongo(db,collectionName,id,url,item):
'''
:param db: db引用
:param collectionNmae: 集合名
:param id: item的更新字典
:param url: 生成id字段
:param item:
:return:
'''
if url:
item[id] = get_md5(item[url])
db[collectionName].update({
id:item[id]},{
'$set':dict(item)},True)
print(item)
else:
db[collectionName].update({
id: item[id]}, {
'$set': dict(item)}, True)
print(item)
taoche_spider.py 导入上面自定义配置文件 ,并且选择覆盖
其中完成,拼接url功能,导入city.py 拼接url,每个地区下每个车类型的第一页

获取某地区下某车类型第一页所有商品url

代码

替换创建项目默认带的piplines.py,使用下面的 ,管道处理数据的一种方式
import pymongo
from .my_settings import get_md5,update_to_mongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
'''
scrapy每个组件的入口
:param crawler:
:return:
'''
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
update_to_mongo(self.db,'car','car_id','car_url',item)
return item
items.py 编写校验字段
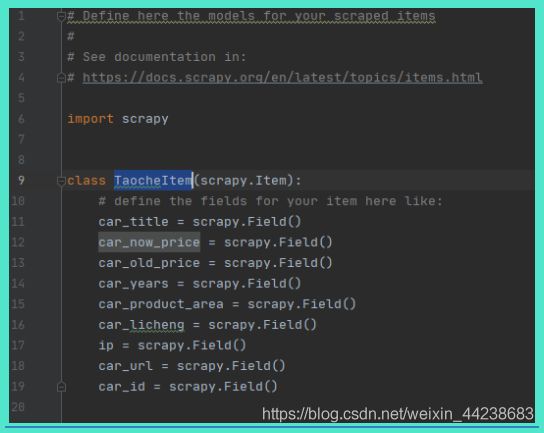
存储到 mongo 数据库
taohce_spider.py 导入item.py 并且 item = 类方法
my_setiings.py 开启管道配置
截止到这一步,上述项目已经完成,进行测试,启动项目 scrapy crawl taoche_spider
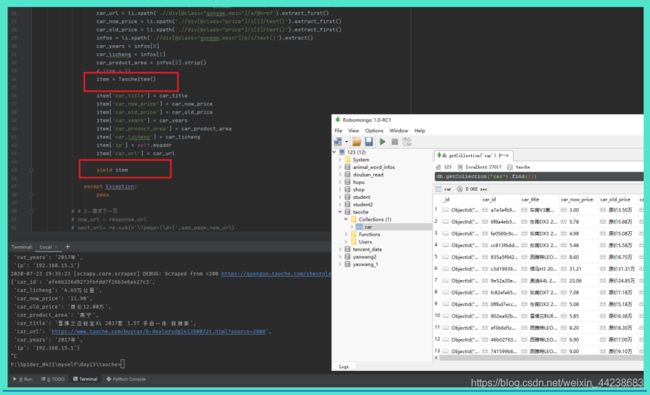
完成分页功能
my_sttings.py 新建一个方法,添加页数
分页这种东西直接在开始就可以直接写,为了以后长期开发,封装成方法,他不香嘛
左侧为taoche_spider.py 右侧为my_settings.py
taoche_spider.py 导入my_settins.py 的分页自增方法

测试数据,以保证做完分页功能,整体项目依然成功
(二)scrapy-redis 分布式
创建分布式的时候,记住,一定要一个scrapy完整项目
再对此项目改造
开发步骤:
1、拥有一个完整的项目
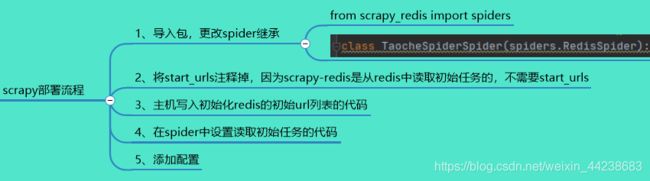
2、taoche_spider.py 导入包,修改继承类
from scrapy_redis import spiders
可以看到,原本是继承scrapy类

3、taoche_spider.py 注释掉start_url (新建redis_urls.py)
初始读取任务从scrapy到scrapy-redis,即主机,原本taoche项目,是在此处获取首页的url,第一层url
现在需要单独创建一个 list ,将其存入到其中,提供从机共享
主机:使用那台电脑上的redis和mongo,那台电脑就是主机 此时共享本机的redis数据库,mongo数据库
主机运行项目的时候,需要将redis服务器打开,前面已经说到了

redis_urls.py 存放了 首页第一层 url,参考指纹集合

从机需要将此处代码注释掉,主机项目别注释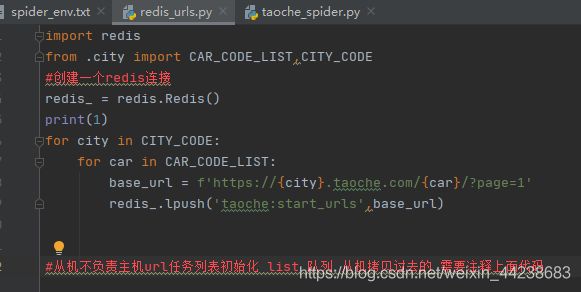
4、在taoche_spider.py中设置读取初始任务的代码,方法如下:
这里的redis-key就表示将来项目启动后就会从redis中的这个key所对应的列表中获取url
参考命名空间

5、my_settings.py 添加redis配置
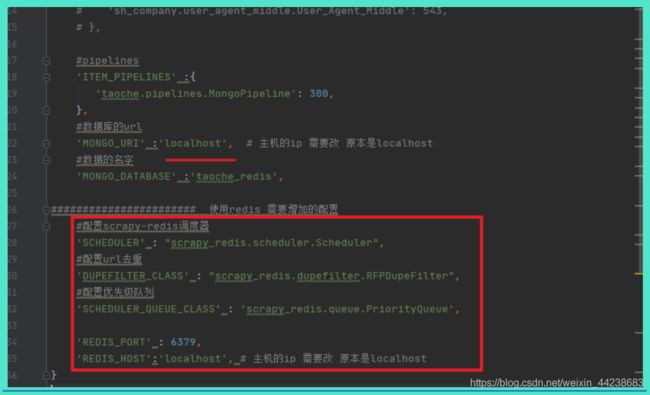
6、主机启动redis,从机将整个项目复制过去
从机,复制主机配置好的整个项目,截止到第5步的项目
修改redis_urls.py 将里面内容全部注释掉,因为这是主机干的活(主机要启动项目项目里面别注释)
my_settins.py 将localhost 的地址改成主机的IP地址
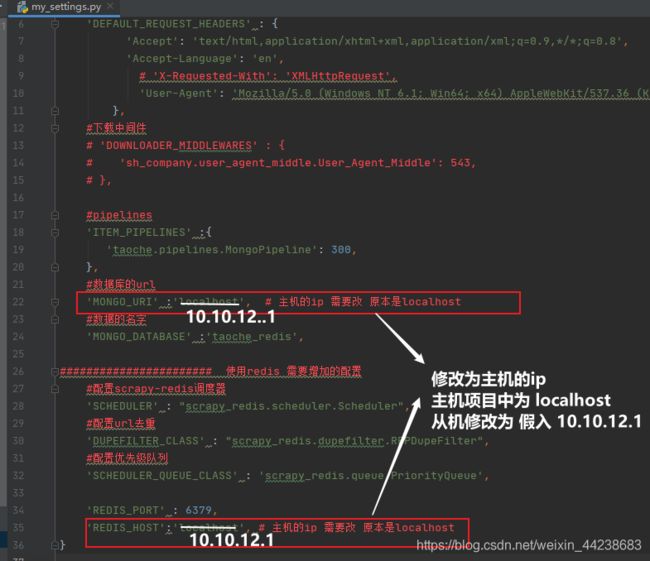
截止完这一步
主机运行主机的项目,从机运行从机的项目,就能实现多台电脑同时执行一个项目,爬取同一个目标
速度非常的快
部署流程概述:
简而言之:
同一个局域网下!!!
① 一个完整的scrapy项目
② 修改为scrapy-redis项目
③ 主机运行主机的项目【注意本机 localhost,和redis_urls.py 不要注释了】
④ 从机 复制好主机的项目【注释掉redis_urls.py 修改my_settings.py 中ip为主机ip】

六、尾声
项目可能复述的不清楚,存在问题,请下方评论
关于项目部署,可能整个过程以文字形式,并不能完全阐述清楚
如果需要此项目的视频,请留言
谢谢