Flink的常见算子和实例代码
算子们的目录
- 前言
- 简单实例:Map算子
-
- 依赖
- 引入包
- 模拟数据源
- 创建Flink上下文环境
- 引入生产的数据源
- 算子处理(Map)
- 打印结果和执行
-
- 不进行算子处理
- 进行算子处理
- 常见的几种算子和区别
-
- Map
- FlatMap
- Filter
-
- 算子代码
- 实现效果
- KeyBy
-
- 模拟数据对象代码
- 算子代码
- 实现效果
- Aggregations(聚合)
-
- 完整代码
- 实现效果(sum)
- 实现效果(min)
- 修改数据效果(min)
- Reduce
-
- 算子代码
- 实现效果
前言
注意:处理完数据后都是DataStream类型数据。
即DataStream / DataStreamSource -> DataStream。
有些算子不适合流式计算比如说聚合函数等。
简单实例:Map算子
依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
引入包
主要为flink-streaming-java这个依赖。
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
模拟数据源
import org.apache.flink.streaming.api.functions.source.SourceFunction;
//SourceFunction里面的类型可以自定义
public class MyStreamingSource implements SourceFunction<String> {
private boolean is_Running = true;
@Override
public void run(SourceContext ctx) throws Exception {
// TODO Auto-generated method stub
int i = 0;
String msg;
while(is_Running) {
msg = " made by Chang BiRenYuan : No." + i++;
ctx.collect(msg);
//每1秒一个数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
// TODO Auto-generated method stub
is_Running=false;
}
}
创建Flink上下文环境
// 创建Flink运行的上下文环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
引入生产的数据源
//获取数据源,自己生产
DataStreamSource<String> item = env.addSource(new MyStreamingSource()).setParallelism(1);
算子处理(Map)
//简单的Map处理
//要注意到流处理是单个单个数据来接收
//处理信息的输入和输出
SingleOutputStreamOperator<String> dealResult = item.map(new MapFunction<String, String>() {
@Override
public String map(String str) throws Exception {
// TODO Auto-generated method stub
int begin = str.indexOf(':');
int end = str.length();
String result = str.substring(begin,end);
return result;
}
});
打印结果和执行
//打印结果
//stream.print().setParallelism(1);
dealResult.print();
env.execute();
不进行算子处理

进行算子处理

常见的几种算子和区别
Map
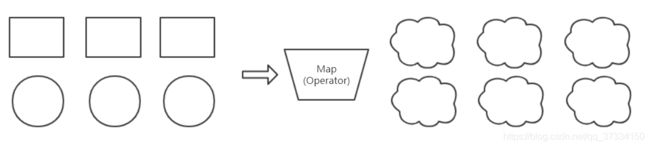
FlatMap
与Map不同,将输入部分转换为一个组/流输出,flat嘛,平坦,数据直接不再是一对一,而是变成一根绳上的蚂蚱。
推荐参考博文:一眼看穿flatMap和map的区别

Filter
筛选
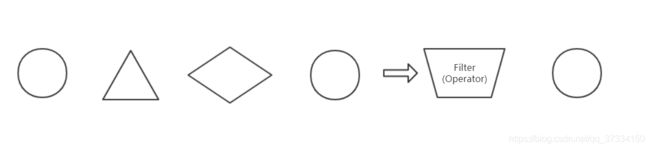
算子代码
SingleOutputStreamOperator<String> dealResult = item.filter(new FilterFunction<String>() {
@Override
public boolean filter(String str) throws Exception {
// TODO Auto-generated method stub
int begin = str.indexOf(':');
int end = str.length();
int num = Integer.valueOf(str.substring(begin, end));
return num/2==0;
}
});
实现效果

KeyBy
分组
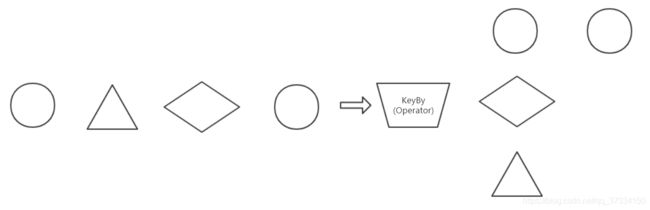
模拟数据对象代码
为了方便展示效果将前面的字符串数据源切换为了随机生成的用户画像。用户名称为随机生成,具体方法randomName网上有,就不贴了,免得本末倒置。
public class UserImage {
String name;
int groupId;
String groupName;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getGroupId() {
return groupId;
}
public void setGroupId(int groupId) {
this.groupId = groupId;
}
public String getGroupName() {
switch(this.groupId) {
case 1: this.groupName="草帽海贼团" ;break;
case 2: this.groupName="红桃A海贼团" ;break;
case 3: this.groupName="革命军" ;break;
default : this.groupName="路人团";break;
}
return this.groupName;
}
public void setGroupName(String groupName) {
this.groupName = groupName;
}
public UserImage() {
super();
name = randomName(true, 3);
groupId = (int) (Math.random()*3 + 1);
this.getGroupName();
}
@Override
public String toString() {
return "UserImage [name=" + name + ", groupId=" + groupId + ", groupName=" + groupName + "]";
}
}
算子代码
//随机用户画像数据源
DataStreamSource<UserImage> item =env.fromCollection(Arrays.asList(new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage(),
new UserImage()
));
//keyBy :KeyBy 函数时会把 DataStream 转换成为 KeyedStream,事实上 KeyedStream 继承了 DataStream,KeyedStream 中的元素会根据用户传入的参数进行分组。
DataStream<UserImage> dealResult = (DataStream<UserImage>) item.keyBy(new KeySelector<UserImage, String>(){
@Override
public String getKey(UserImage user) throws Exception {
// TODO Auto-generated method stub
return user.getGroupName();
}
});
实现效果
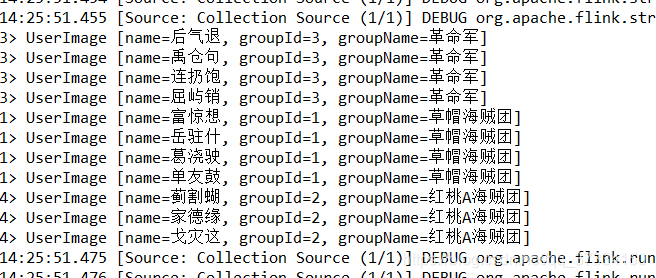
Aggregations(聚合)
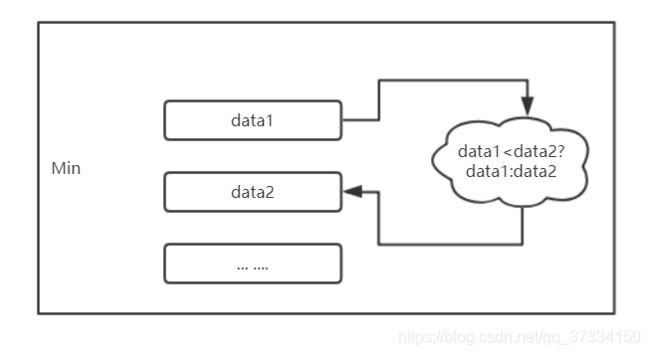
Aggregations 也需要先指定一个 key 进行聚合。
值得注意的是:sum算子的功能是对遍历元素进行累加:eg:第一个数据(1,2,3),(2,1,3) 那么keyBy(0).sum(2)就是输出(1,2,3),(2,1,6)。
而min和max则无法确定其它数据的大小,只能输出当前已知的最小值,相当于你排序的时候最小/大值排序。(1,2,2),(2,1,3),(3,2,1)如果min(1)则会输出(1,2,3),(1,2,3),(3,2,1)。
完整代码
// 创建Flink运行的上下文环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Tuplen有N个参数的元组,数组
List data = new ArrayList<Tuple2<Integer,Integer>>();
data.add(new Tuple2<>(5,1));data.add(new Tuple2<>(4,6));data.add(new Tuple2<>(5,4));data.add(new Tuple2<>(9,8));
data.add(new Tuple2<>(4,1));data.add(new Tuple2<>(6,5));data.add(new Tuple2<>(4,1));data.add(new Tuple2<>(9,9));
DataStreamSource items = env.fromCollection(data);
// 5 1
// 4 6
// 5 4
// 9 8
// 4 1
// 6 5
// 4 1
// 9 9
//筛选出第一个同字段分组中的最小数字。
items.keyBy(0).min(1).printToErr();
env.execute();
实现效果(sum)

实现效果(min)
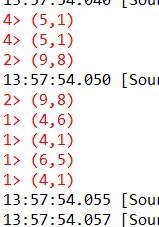
修改数据效果(min)
改(9,9)前面的(4,1)为(4,8)。
实现截图不变。

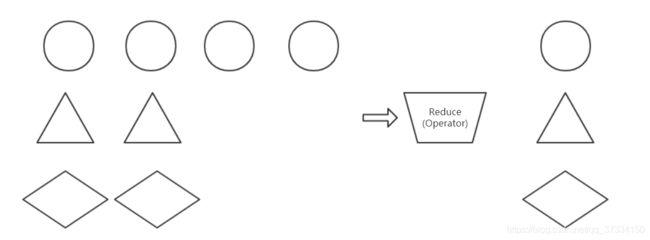
Reduce
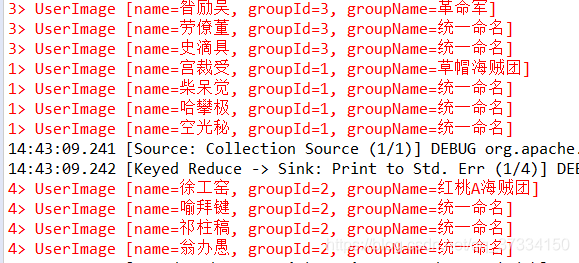
同样需要先keyBy才能进行Reduce操作,那么我们顺着KeyBy的代码直接增加即可,注意到同一个组名groupName的会被重新命名为“统一命名”,即每个不一样的组名只出现一次。
因为基于KeyBy,实际上就是分组后对重复的数据进行操作的算子。
算子代码
DataStream<UserImage> dealResult = (DataStream<UserImage>) item.keyBy(new KeySelector<UserImage, String>(){
@Override
public String getKey(UserImage user) throws Exception {
// TODO Auto-generated method stub
return user.getGroupName();
}
}).reduce(new ReduceFunction<UserImage>() {
@Override
public UserImage reduce(UserImage value1, UserImage value2) throws Exception {
// TODO Auto-generated method stub
value2.setGroupId(value1.getGroupId());
value2.setGroupName(value1.getGroupName());
value2.setGroupName("统一命名");
return value2;
}
});
实现效果
如果看懂了点个赞,评论鼓励一下,给编者点小动力,不做拿来主义者,谢谢啦~