机器学习: 01 决策树分类
文章目录
- 决策树演变
-
- 从LR 到决策树演变
- 决策树构建过程,如何停止生长?三个条件是什么
- 树模型属性选择?
- 回归树剪纸?如果让回归树无限制生长,会过拟合
- 决策树到随机森林
- 决策树分类案例
-
- 工具库导入
- 读取数据
- 特征工程处理
-
- 特征(属性)和目标
- 特征处理/特征工程
- 构建决策树分类器
- 可视化决策树
-
- 可视化方法1
- 可视化方法2
- 可视化方法3-推荐
- 决策树算法小结
-
- 决策树优点
- 决策树算法的缺点:
- 参考资料
决策树演变
从LR 到决策树演变
决策树构建过程,如何停止生长?三个条件是什么
树模型属性选择?
决策树?可以分类(预测离散数值)也可以做回归(预测连续数值)
回归树剪纸?如果让回归树无限制生长,会过拟合
决策树到随机森林
从LR 到决策树演变
- 学习过程:训练样本-> 属性划分(重点掌握节点分裂方法)
- 预测过程:根节点出发-> 通过属性划分结果判断-> 直到获取叶子结点
决策树构建过程,如何停止生长?三个条件是什么
- 当前节点包含样本全部属于某一类,无需划分
- 当前属性集空或者所有样本在所有属性上取值相同,无法划分
- 当前节点包含的样本集合为空,不能划分
树模型属性选择?
- 信息熵(entroy):衡量样本集合纯度一种指标,越小纯度越高

- 信息增益(ID3): 根节点信息熵-属性信息熵,结果是计算了一个下降的程度。

通过计算每个属性的信息增益Gain(D,a) ,信息增益越大,越优先分裂。依次类推,可以计算出所有属性分裂的优先级。
缺点:发现 划分后的信息熵和属性个数有关(属性越多,Gain 就越大,显然不合适)
- 信息增益率(C4.5): 和ID3 唯一优化,在Gain的基础上除以属性信息

- gini指数(CART树使用gini指数作为属性划分方法,二叉树)

回归树剪纸?如果让回归树无限制生长,会过拟合
解决方案:增加正则化项(叶子结点个数,限制了树的生成)

决策树到随机森林
- Bagging思想:降低过拟合,提升泛化能力
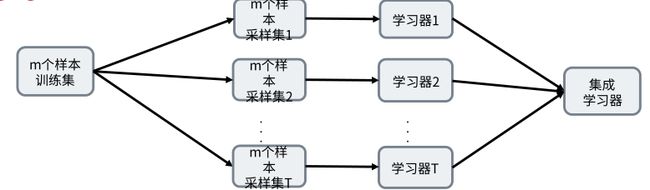
对数据集采样-> 每个样本集T训练学习器-> 集成学习器(分类:投票机制;回归:求平均)
- 随机森林:bagging的优化版本,随机森林采用CART树作为学习器
特点:样本随机,特征随机(不足:不能全部利用样本数据)
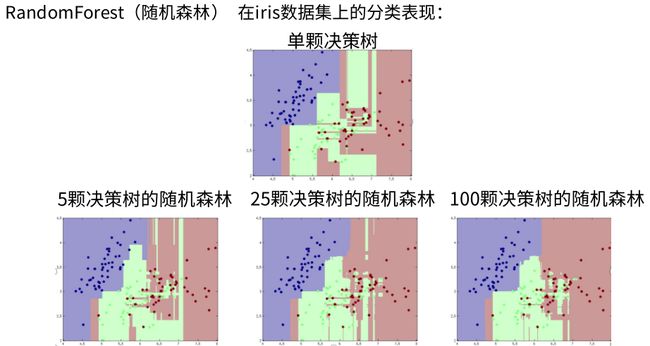
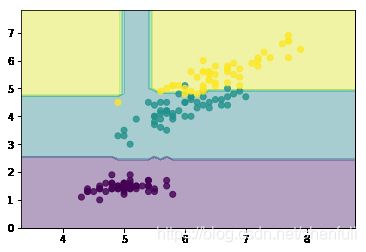
我们通过sklearn提供的RF算法通过iris数据集来看看不同的树个数对效果影响
from sklearn.ensemble import RandomForestClassifier
# 仍然使用自带的iris数据
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
def show(n_estimators=1):
# 训练模型,限制树的最大深度4
# n_estimators: 树的个数
clf = RandomForestClassifier(max_depth=4,n_estimators=n_estimators)
#拟合模型
clf.fit(X, y)
# 画图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
plt.show()
show(n_estimators=1)
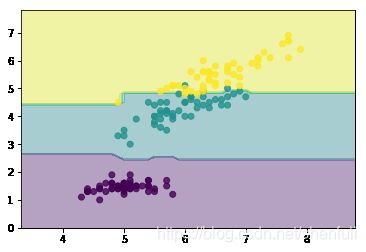
show(n_estimators=5)
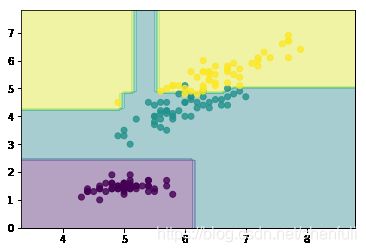
show(n_estimators=25)
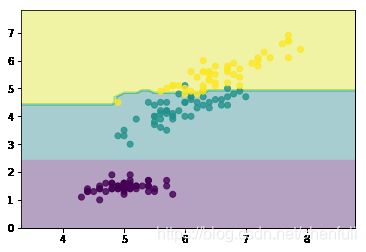
show(n_estimators=100)
决策树分类案例
- 决策树完成分类(多个树结果进行投票)
- 决策树完成回归(多个树决策结果求平均)
接下来我们通过sklearn库来演示一下决策树分类的应用
工具库导入
#用于数据处理和分析的工具包
import pandas as pd
#引入用于数据预处理/特征工程的工具包
from sklearn import preprocessing
#import决策树建模包
from sklearn import tree
# sklearn版本 信息,按照最新即可
import sklearn
print(sklearn.__version__)
0.23.2
读取数据
adult_data = pd.read_csv('./DecisionTree.csv')
#读取前5行,了解一下数据
adult_data.head(5)
| workclass | education | marital-status | occupation | relationship | race | gender | native-country | income | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | State-gov | Bachelors | Never-married | Adm-clerical | Not-in-family | White | Male | United-States | <=50K |
| 1 | Self-emp-not-inc | Bachelors | Married-civ-spouse | Exec-managerial | Husband | White | Male | United-States | <=50K |
| 2 | Private | HS-grad | Divorced | Handlers-cleaners | Not-in-family | White | Male | United-States | <=50K |
| 3 | Private | 11th | Married-civ-spouse | Handlers-cleaners | Husband | Black | Male | United-States | <=50K |
| 4 | Private | Bachelors | Married-civ-spouse | Prof-specialty | Wife | Black | Female | Cuba | <=50K |
# 分析每个字段信息 (字段名称、类型、记录数 )
adult_data.info()
RangeIndex: 32561 entries, 0 to 32560
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 workclass 32561 non-null object
1 education 32561 non-null object
2 marital-status 32561 non-null object
3 occupation 32561 non-null object
4 relationship 32561 non-null object
5 race 32561 non-null object
6 gender 32561 non-null object
7 native-country 32561 non-null object
8 income 32561 non-null object
dtypes: object(9)
memory usage: 2.2+ MB
# 分析数据维度大小(行,列)
adult_data.shape
(32561, 9)
# 分析数据全部列名称
adult_data.columns
Index(['workclass', 'education', 'marital-status', 'occupation',
'relationship', 'race', 'gender', 'native-country', 'income'],
dtype='object')
# 分析字段类别个数 (二分类问题)
import numpy as np
np.unique(label)
array([' <=50K', ' >50K'], dtype=object)
特征工程处理
一般情况下,主要数据类型
- 数值类型
- 类别数据
- 日期数据类型
特征(属性)和目标
feature_columns = [u'workclass', u'education', u'marital-status', u'occupation', u'relationship', u'race', u'gender', u'native-country']
label_column = ['income']
#区分特征和目标列
features = adult_data[feature_columns]
label = adult_data[label_column]
features.head(2)
| workclass | education | marital-status | occupation | relationship | race | gender | native-country | |
|---|---|---|---|---|---|---|---|---|
| 0 | State-gov | Bachelors | Never-married | Adm-clerical | Not-in-family | White | Male | United-States |
| 1 | Self-emp-not-inc | Bachelors | Married-civ-spouse | Exec-managerial | Husband | White | Male | United-States |
label.head(2)
| income | |
|---|---|
| 0 | <=50K |
| 1 | <=50K |
features = adult_data[feature_columns]
for f in feature_columns:
print('*' * 60)
print("{}->{}".format( f,np.unique(features[f])))
************************************************************
workclass->[' ?' ' Federal-gov' ' Local-gov' ' Never-worked' ' Private'
' Self-emp-inc' ' Self-emp-not-inc' ' State-gov' ' Without-pay']
************************************************************
education->[' 10th' ' 11th' ' 12th' ' 1st-4th' ' 5th-6th' ' 7th-8th' ' 9th'
' Assoc-acdm' ' Assoc-voc' ' Bachelors' ' Doctorate' ' HS-grad'
' Masters' ' Preschool' ' Prof-school' ' Some-college']
************************************************************
marital-status->[' Divorced' ' Married-AF-spouse' ' Married-civ-spouse'
' Married-spouse-absent' ' Never-married' ' Separated' ' Widowed']
************************************************************
occupation->[' ?' ' Adm-clerical' ' Armed-Forces' ' Craft-repair' ' Exec-managerial'
' Farming-fishing' ' Handlers-cleaners' ' Machine-op-inspct'
' Other-service' ' Priv-house-serv' ' Prof-specialty' ' Protective-serv'
' Sales' ' Tech-support' ' Transport-moving']
************************************************************
relationship->[' Husband' ' Not-in-family' ' Other-relative' ' Own-child' ' Unmarried'
' Wife']
************************************************************
race->[' Amer-Indian-Eskimo' ' Asian-Pac-Islander' ' Black' ' Other' ' White']
************************************************************
gender->[' Female' ' Male']
************************************************************
native-country->[' ?' ' Cambodia' ' Canada' ' China' ' Columbia' ' Cuba'
' Dominican-Republic' ' Ecuador' ' El-Salvador' ' England' ' France'
' Germany' ' Greece' ' Guatemala' ' Haiti' ' Holand-Netherlands'
' Honduras' ' Hong' ' Hungary' ' India' ' Iran' ' Ireland' ' Italy'
' Jamaica' ' Japan' ' Laos' ' Mexico' ' Nicaragua'
' Outlying-US(Guam-USVI-etc)' ' Peru' ' Philippines' ' Poland'
' Portugal' ' Puerto-Rico' ' Scotland' ' South' ' Taiwan' ' Thailand'
' Trinadad&Tobago' ' United-States' ' Vietnam' ' Yugoslavia']
特征处理/特征工程
features = pd.get_dummies(features)
features.head(2)
| workclass_ ? | workclass_ Federal-gov | workclass_ Local-gov | workclass_ Never-worked | workclass_ Private | workclass_ Self-emp-inc | workclass_ Self-emp-not-inc | workclass_ State-gov | workclass_ Without-pay | education_ 10th | ... | native-country_ Portugal | native-country_ Puerto-Rico | native-country_ Scotland | native-country_ South | native-country_ Taiwan | native-country_ Thailand | native-country_ Trinadad&Tobago | native-country_ United-States | native-country_ Vietnam | native-country_ Yugoslavia | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
2 rows × 102 columns
features.columns
Index(['workclass_ ?', 'workclass_ Federal-gov', 'workclass_ Local-gov',
'workclass_ Never-worked', 'workclass_ Private',
'workclass_ Self-emp-inc', 'workclass_ Self-emp-not-inc',
'workclass_ State-gov', 'workclass_ Without-pay', 'education_ 10th',
...
'native-country_ Portugal', 'native-country_ Puerto-Rico',
'native-country_ Scotland', 'native-country_ South',
'native-country_ Taiwan', 'native-country_ Thailand',
'native-country_ Trinadad&Tobago', 'native-country_ United-States',
'native-country_ Vietnam', 'native-country_ Yugoslavia'],
dtype='object', length=102)
构建决策树分类器
features.values
array([[0, 0, 0, ..., 1, 0, 0],
[0, 0, 0, ..., 1, 0, 0],
[0, 0, 0, ..., 1, 0, 0],
...,
[0, 0, 0, ..., 1, 0, 0],
[0, 0, 0, ..., 1, 0, 0],
[0, 0, 0, ..., 1, 0, 0]], dtype=uint8)
label.values
array([[' <=50K'],
[' <=50K'],
[' <=50K'],
...,
[' <=50K'],
[' <=50K'],
[' >50K']], dtype=object)
#初始化一个决策树分类器
## sklearn api: https://scikit-learn.org/stable/modules/tree.html#classification
## criterion 指定属性的分裂标准,默认gini.目前支持两种,另外一种: entropy 信息增益
## max_depth 设置决策树深度
clf = tree.DecisionTreeClassifier(criterion='gini', max_depth=4)
#用决策树分类器拟合数据
clf = clf.fit(features.values, label.values)
clf
DecisionTreeClassifier(max_depth=4)
len(clf.feature_importances_)
102
clf.predict(features.values)
array([' <=50K', ' <=50K', ' <=50K', ..., ' <=50K', ' <=50K', ' >50K'],
dtype=object)
# 分析每个特征的重要度,决策树 按照这个属性进行分裂(采用gini系数进行特征属性划分)
_dict = dict(zip(features.columns.tolist(),clf.feature_importances_))
_dict = sorted( _dict.items() ,key=lambda x:x[1],reverse=True )
_dict[:20]
[('marital-status_ Married-civ-spouse', 0.6497159469917805),
('occupation_ Exec-managerial', 0.13584561178496818),
('occupation_ Prof-specialty', 0.09386750154814742),
('education_ Bachelors', 0.04945186618501629),
('education_ Prof-school', 0.02255045705141144),
('education_ Doctorate', 0.019298655920747067),
('education_ Masters', 0.015211613351255782),
('workclass_ Self-emp-not-inc', 0.011316439614608353),
('marital-status_ Never-married', 0.0015902032281975528),
('gender_ Female', 0.0007149414109846913),
('native-country_ Haiti', 0.000436762912882742),
('workclass_ ?', 0.0),
('workclass_ Federal-gov', 0.0),
('workclass_ Local-gov', 0.0),
('workclass_ Never-worked', 0.0),
('workclass_ Private', 0.0),
('workclass_ Self-emp-inc', 0.0),
('workclass_ State-gov', 0.0),
('workclass_ Without-pay', 0.0),
('education_ 10th', 0.0)]
可视化决策树
# 导入可视化工具类
import pydotplus
from IPython.display import display, Image
# 注意,根据不同系统安装Graphviz2
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
dot_data = tree.export_graphviz(clf,
out_file=None,
feature_names=features.columns,
class_names = ['<=50k', '>50k'],
filled = True,
rounded =True
)
graph = pydotplus.graph_from_dot_data(dot_data)
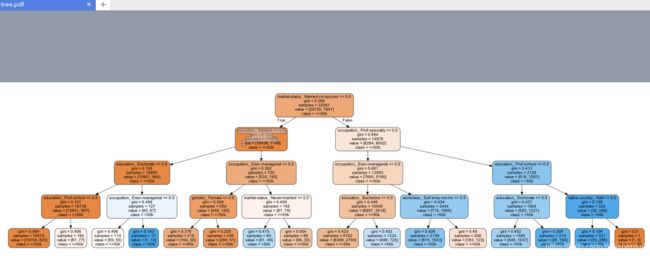
可视化方法1
现在可以将模型存入dot文件tree.dot,用graphviz的dot命令生成决策树的可视化文件
with open("tree.dot", 'w') as f:
tree.export_graphviz(clf,
out_file=f,
feature_names=features.columns,
class_names = ['<=50k', '>50k'],
filled = True,
rounded =True
)
注意,这个命令在命令行执行( 注意:配置环境变量PATH = C:/Program Files (x86)/Graphviz2.38/bin/ )
dot -Tpdf tree.dot -o tree.pdf
可视化方法2
是用pydotplus生成tree.pdf。这样就不用再命令行去专门生成pdf文件了
graph.write_pdf("tree.pdf")
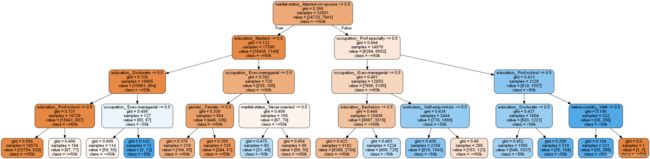
可视化方法3-推荐
display(Image(graph.create_png()))
决策树算法小结
决策树优点
- 简单直观,生成的决策树很直观
- 基本不需要预处理,不需要提前归一化,处理缺失值
- 使用决策树预测的代价是O(log2m)。 m为样本数
- 既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值
- 可以处理多维度输出的分类问题
- 相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
- 可以交叉验证的剪枝来选择模型,从而提高泛化能力
- 对于异常点的容错能力好,健壮性高
决策树算法的缺点:
- 决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
- 决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
- 寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
- 有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
- 如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善
参考资料
[1] cikit-learn决策树算法类库使用小结
https://www.cnblogs.com/pinard/p/6056319.html
[2] windows 下安装 graphviz-2.38
https://graphviz.gitlab.io/_pages/Download/windows/graphviz-2.38.msi