程序员C语言快速上手——高级篇(十)
文章目录
- 高级篇
- 内存管理
- 内存四区
- 内存分配
- 动态内存管理
- 指针高级
- 二维数组
- 二级指针
- 函数指针
- 函数指针的声明
- 函数指针的赋值与使用
- 函数指针的传递
- void*指针
- 欢迎关注我的公众号:编程之路从0到1
高级篇
内存管理
C语言程序加载到内存中,通常可人为划分为栈(stack)、堆(heap)、代码段(text)、数据段(data)、bss 段、常量存储区等区域部分,在这个基础上,人们习惯在逻辑上将C语言程序的内存模型归纳为四大区域。请注意,这四大区域只是逻辑上的划分,实际上对于内存而言,它只是一片连续的存储单元,并不存在什么物理上的区域划分。我们了解C语言内存四区,可以加深对C语言的理解,特别是C语言的内存管理的理解。
内存四区
-
栈(stack)
用于保存函数中的形参、返回地址、局部变量以及函数运行状态等数据。栈区的数据由编译器自动分配、自动释放,无需程序员去管理和操心。 当我们调用一个函数时,被称为函数入栈,指的就是为这个函数在栈区中分配内存。 -
堆(heap)
堆内存由程序员手动分配、手动释放,如果不释放,只有当程序运行结束后,操作系统才会去回收这片内存。C语言所谓的动态内存管理,指的就是堆内存管理,这也是C语言内存管理的核心内容。 -
静态全局区
又被人称为数据区、静态区。它又可细分为静态区和常量区。主要用来存放全局变量、静态变量以及常量。该区域内存,只有在程序运行结束后才会被操作系统回收。被形象的比喻为与整个程序同生共死,也就是说只要程序没有退出,这部分内存数据就一直存在。 -
代码区
用于存放程序编译链接后生成的二进制机器码指令。由操作系统管理,程序员无需关心。
内存分配
C语言内存分配的三种形式
-
静态/全局内存
静态声明的变量和全局变量都使用这部分内存。在程序开始运行时分配,终止时消失。区别:所有函数都能访问全局变量,静态变量作用域则只局限于定义它的函数内部 -
自动内存
在函数内声明,函数调用时创建(分配在栈中),作用域局限于该函数内部,函数执行完则释放。 -
动态内存
内存分配在堆上,用完需手动释放,使用指针来引用分配的内存,作用域局限于引用内存的指针
为什么需要在堆上面分配动态内存?
在前面的章节中,我们一直使用自动内存,也就是栈内存,这并不影响C程序的编写,那么我们为什么还要去使用动态内存,而且还要很麻烦的去手动管理动态内存呢?
-
栈区的内存大小通常都比较小,具体大小视编译器不同而有所区别,通常可能会在2M大小左右。当我们在处理大文件、图片、视频等数据时,2M显然是不够用的,我们可能需要更大块的内存空间。通常的,堆内存空间大小是没有限制的,只要你电脑的内存条足够大,你就可以向操作系统申请足够大的堆内存空间使用。
-
栈内存的使用有一定特殊性。通常当函数调用结束后就会退栈,那么函数中的局部变量也就不复存在了。当我们需要一个变量或数组有更长的生命周期时,堆内存是更好的选择。
-
全局变量虽然有与程序相同的生命周期,但无法动态的确定大小。例如将数组声明为全局数组变量,那么就必须在声明时静态指定数组的长度。假如我们用一个数组来存放会员注册信息,那么我们根本不能在编译时确定数组的具体长度,显然的,我们需要一个可以动态增长的内存区域。不断有新会员注册,那么我们的数组长度也需要增长。
动态内存管理
在C语言内存分配的三种形式中,真正能由程序员来控制管理的只有在堆上面分配的动态内存,这也是我们需要关注的重点内容。
先看一个示例:
// 定义一个函数,返回局部变量的地址
int *fn(){
int i = 10;
return &i;
}
int main(){
// 对fn函数返回的指针进行解引用
printf("%d",*fn());
return 0;
}
以上示例会报错退出,显然的,我们是不能返回一个局部变量的地址的,局部变量在函数调用结束会就会释放,因此在局部变量作用域之外去操作它的地址是非法操作。
使用动态内存
#include 运行正常,打印结果:
16
申请动态内存之后,如果不手动释放,它就会一直存在,直到程序退出。
可以看到malloc的函数原型 void *malloc(size_t _Size); 它返回一个void *类型指针,这是一个无类型或者说是通用类型指针,它可以指向任意类型,因此我们在使用它的返回值时,首先做了强制类型转换。该函数只有一个无符号整数参数,用来传入我们想要申请的内存大小,单位是字节。上例中我们传入的是一个int类型的大小,通常是4字节。需要特别注意,当使用malloc分配动态内存时,如果失败,它会返回NULL指针,因此使用时需判断。
在使用动态内存时,一定要在用完后记得手动释放内存,否则易造成内存泄露
#include 与动态内存管理相关的主要有四个函数
| 函数 | 功能 |
|---|---|
malloc |
从堆上分配一块指定大小的内存,并返回分配的空间的起始地址,这里是一个void类型指针,如果系统内存不足以分配,则返回NULL。该函数不会清空所分配的内存空间中的内容,因此可能分配的空间会包含一些随机数据 |
calloc |
该函数的功能基本与malloc相同,主要的区别是,它分配堆内存时会进行清空,因此内存空间不会包含一些随机数据,当然,相应的,它的性能也略低于malloc,毕竟它多做了一个清理内存的工作。 |
realloc |
该函数用于重新分配内存大小,其使用情况,较以上两个函数要复杂。 该函数也不会对申请的内存空间进行任何初始化。 |
free |
该函数用于手动释放以上三个函数所申请的堆内存空间。它的参数是一个指向所分配的动态内存的指针。要注意,该函数只能用来释放以上三个函数申请的堆空间,它们需成对使用,不能用来释放任意内存空间。 |
calloc原型
void *calloc(size_t _NumOfElements,size_t _SizeOfElements);
第一个参数用来指定元素的个数,第二个参数指定一个元素所占内存大小。malloc函数的参数正好相当于它的两参数的乘积。
int *array = (int*)calloc(10,sizeof(int));
realloc原型
void *realloc(void *_Memory,size_t _NewSize);
它的第一个参数为指向原内存块的指针,第二个参数为重新请求的内存大小。
当我们使用malloc动态分配了一块内存空间,随着数据的增加,内存不够用时,就可以使用realloc调整原来分配的内存大小。
int main(){
// 分配10个元素大小的int数组
int *arr = (int*)malloc(10*sizeof(int));
if (arr == NULL){
printf("malloc:Not enough memory space!\n");
return -1;
}
// 将原数组扩展到20个元素大小
int *newArr = (int*)realloc(arr, 20*sizeof(int));
if(newArr == NULL){
printf("realloc:Not enough memory space!\n");
}else{
arr = newArr;
}
// do sometings
// 释放内存
free(arr);
return 0;
}
使用realloc函数需要注意,当原内存空间之后还有足够的内存可分配时,那么就会紧随原内存空间之后扩展空间,这样一来,realloc返回的void指针与指向原内存空间的指针相同;如果原内存空间之后没有足够的内存可扩展了,那么就在堆内存中其他的拥有足够空间的地方重新分配空间,并将原内存空间中的数据复制到新空间,只是这样一来,其他地方保存的原内存空间的地址就必须修改为realloc返回的新地址,且原内存空间会被释放,旧地址不可用。可以看到,该函数之所以如此复杂,其目的就是为了保证申请的空间都是一片连续的内存空间,而不是碎片化的内存。
关于realloc的使用总结
| 第一个参数 | 第二个参数 | 描述 |
|---|---|---|
NULL |
欲申请空间大小 | 功能等同malloc,申请新的堆空间 |
非NULL |
0 |
等同于free,释放原内存空间 |
非NULL |
比原内存空间小 | 在原内存空间基础上回收部分内存,相当于缩小空间 |
非 NULL |
比原内存空间大 | 在原内存空间之后扩展,或者在其他位置重新分配更大空间 |
-
realloc函数功能强大,可以用来申请新的堆空间,释放堆空间,调整原来的堆空间。它一个就能替代其他的三个函数 -
realloc函数如果返回NULL,则表明内存不足,申请新的堆空间或者将原空间调大失败。失败时,它不会对原来的堆空间造成影响
关于free的使用总结
当使用free函数释放内存后,指向原堆空间的指针并不会被清理或重置,这意味着指向原空间的指针中仍保存着一个不合法的地址,如果不小心再次使用了这个指针,就会造成无法预知的问题,因此在使用free释放内存后,还应当将原指针重置为NULL
arr = (int*)realloc(arr, 20*sizeof(int));
// 释放内存
free(arr);
// arr指针保存的地址已经不合法,需重置
arr = NULL;
指针高级
二维数组
如果数组中的元素也是数组,那么这样的数组就是二维数组,在逻辑上,仿佛有两个维度,实际上在内存中仍然是一片线性的连续的内存空间。
#include 调试
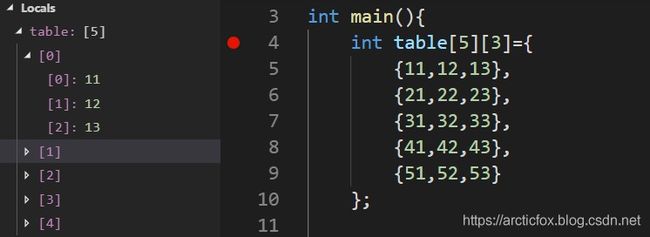
再来看元素内存地址的打印结果
22fe10
22fe10
22fe14
22fe18
22fe1c
可以发现二维数组很像一个二维表格,有行有列,但是从元素的内存地址可以看出,在内存中仍然是连续的一片。
关于二维数组的遍历
// 二维数组遍历
for (int i = 0; i < 5; i++){
for (int j = 0; j < 3; j++){
printf("%d\n",table[i][j]);
}
}
二级指针
所谓二级指针,就是一个指向指针的指针。
我们知道指针变量是用来保存一个普通变量的地址的,那么如果对一个指针变量取地址,并用另一个变量保存指针变量的地址,这种情况是否存在呢?
int main(){
int num = 16;
// 声明一个一级指针
int *p = #
// 声明一个二级指针,一个指向指针的指针
int **pp = &p;
printf("p=%x\n",p);
printf("pp=%x\n",pp);
printf("&pp=%x\n",&pp);
return 0;
}
打印结果:
p=22fe4c
pp=22fe40
&pp=22fe38
可以看到,凡是变量都有地址,即使是指针变量也是有地址的,这种使用两个*来声明的指向指针的变量,就是二级指针。一级指针存的是普通变量的内存地址,二级指针则是存的一个一级指针的内存地址。
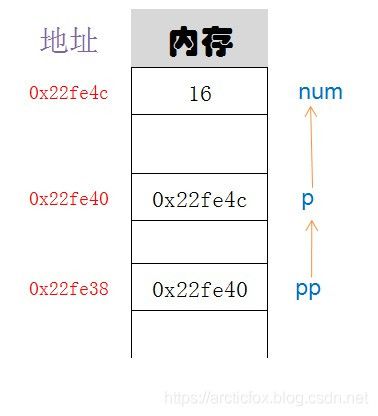
在遇到二级指针时,要获取原始变量的值,就需要使用两个*进行解引用,如上例中的**p可获取num的值,如使用一个*解引用,获得的只是指针p的地址而已。
除了二级指针,自然还可以有三级指针、四级指针等等,三级指针极为少用,四级指针及之后面就没有意义了。除了二级指针有较强的实用意义,其他的基本可以忽略。
引出了二级指针,有人一定会问,二级指针到底有什么用处,在哪里使用?下面看一个示例
int main(){
// 使用二维数组保存英文歌单
char songs[10][50]={
"My love",
"Just one last dance",
"As long as you love me",
"Because of you",
"God is a girl",
"Hero",
"Yesterday once more",
"Lonely",
"All rise",
"One love"
};
for (size_t i = 0; i < 10; i++){
printf("%s\n",songs[i]);
}
return 0;
}
在C语言中,字符串是用字符数组来表示的,那么字符串数组也必然是一个二维数组,如上。在字符串的章节中讲过,C语言字符串也可以使用char*来表示,那么字符串数组也就可以使用二级指针char **来表示了。
void printStrings(char **s,int len){
char **start = s;
// 使用二级指针来遍历字符串数组
for (;s < start + len;s++){
printf("%s\n",*s);
}
}
int main(){
// 声明一个char*类型的数组,它的元素是一个char*指针
char* songs[10]={
"My love",
"Just one last dance",
"As long as you love me",
"Because of you",
"God is a girl",
"Hero",
"Yesterday once more",
"Lonely",
"All rise",
"One love"
};
// 一个指针数组的数组名,实际上就是一个二级指针
char **p = songs;
printStrings(p,10);
return 0;
}
可以用一句话来解释一级指针和二级指针的使用区别:
一级指针是用来修改所指向的内存空间中的值,二级指针是用来修改一级指针指向的内存空间。

二级指针的实际运用
#include 打印结果
520
520
Because of you
God is a girl
Hero
函数指针
在上面的内存四区中提到了代码区,而函数就是一系列指令的集合,因此它也是存放在代码区。既然存放在内存中,那么就会有地址。我们知道数组变量实际上也是一个指针,指向数组的起始地址,结构体指针也是指向第一个成员变量的起始地址,而函数指针亦是指向函数的起始地址。
所谓函数指针,就是一个保存了函数的起始地址的指针变量。
函数指针的声明
声明格式:
【返回值类型】 (*变量名) (【参数类型】)
实例
// 分别声明四个函数指针变量 f1、f2、f3、f4
int (*f1)(double);
void (*f2)(char*);
double* (*f3)(int,int);
int (*f4)();
函数指针的赋值与使用
当一个函数的原型与所声明的函数指针类型匹配,那么就可以将一个函数名赋值给函数指针变量。
int count(double val){
printf("count run\n");
return 0;
}
void printStr(char *str){
printf("printStr run\n");
}
double *add(int a,int b){
printf("add run\n");
return NULL;
}
int get(){
printf("get run\n");
return 0;
}
int main(){
// 声明函数指针并初始化为NULL
int (*f1)(double) = NULL;
void (*f2)(char*) = NULL;
double* (*f3)(int,int) = NULL;
int (*f4)() = NULL;
// 为函数指针赋值
f1 = &count;
f2 = &printStr;
f3 = &add;
f4 = &get;
// 使用函数指针调用函数
f1(0.5);
f2("f2");
f3(1, 3);
f4();
return 0;
}
函数名同数组名一样,它本身就是一个指针,因此可以省略取地址的操作,直接将函数名赋值给指针
f1 = count;
f2 = printStr;
f3 = add;
f4 = get;
函数指针的传递
// 加法函数
int add(int a,int b){
return a +b;
}
// 减法函数
int sub(int a, int b){
return a-b;
}
// 计算器函数。将函数指针做形式参数
void calculate(int a,int b, int(*proc)(int,int)){
printf("result=%d\n",proc(a,b));
}
int main(){
// 算加法,传入加法函数
calculate(10,5,add);
// 算减法,传入减法函数
calculate(10,5,sub);
return 0;
}
可以看到,将函数指针作为参数传递,可以使得C语言编程变得更加灵活强大。而在Python、JavaScript等编程语言中,当前流行的函数式编程范式,即将一个函数作为参数传入到另一函数中执行,实际上有些古老的C语言中早就能实现了。
除此之外,C语言还有其他的一些奇技淫巧,虽然看起来实现得不够优雅,但也足以证明C语言无所不能。
以上在函数的形参中直接定义函数指针看起来不够简洁优雅,每次都得写一大串,实际上还有更简洁的方式,这就需要借助typedef
// 定义一个函数指针类型,无需起新的别名
typedef int(*proc)(int,int);
// 使用函数指针类型 proc 声明新的函数指针变量 p
void calculate(int a,int b, proc p){
printf("result=%d\n",p(a,b));
}
函数指针实用小结
- 利用函数指针可以实现函数式编程
- 将函数指针存入数组中,可以像Java、Python这样,实现函数回调通知机制
- 将结构体与函数指针结合,可以模拟面向对象编程中的类。实际上Go语言就是这样做的,Go语言没用类机制,就是使用结构体模拟面向对象编程。
void*指针
前面几次提到通用类型指针void*,它可以指向任意类型,但对于void*指针到底是什么没有做深入的探讨。事实上,只有理解了void*指针,才能真正理解C语言指针的本质,才能使用void*指针实现一些奇技淫巧。
首先思考一个问题,指针仅仅是用来保存一个内存地址的,所有的内存地址都只是一个号码,那么指针为什么还需要类型呢?理论上所有的指针都应该是同一种类型才对呀?
先写个代码探索一番
int main(){
short num = 18;
char *pChar = (char*)#
int *pInt = (int*)#
printf("pChar=%x pInt=%x\n",pChar,pInt);
printf("*pChar=%d *pInt=%d\n",*pChar,*pInt);
return 0;
}
分别强制使用char*指针和int*指针来保存short num的地址,打印结果如下:
pChar=22fe3e ---- pInt=22fe3e
*pChar=18 ---- *pInt=-29491182
可以看到,保存地址是OK的,但是解引用获取值就会存在问题。由此我们基本可以推断一个事实,指针用来保存变量的内存地址与变量的类型无关,任何类型指针都可以保存任何一个地址;指针之所以需要类型,只与该指针的解引用有关。
short是2个字节,char是1个字节,int是4个字节,而指针保存的是第一个字节的地址,当指针声明为short时,编译器就知道从当前这个地址往后取几个字节作为一个整体。如果指针没有具体类型,那么编译器根本无法判断应从当前这个字节往后取几个字节。如上例,*pInt解引用后结果错误,这就是因为原类型是short2字节,而使用int*指针去解引用会超出short本身的两字节内存,将紧随其后的两字节内存也强制读取了,访问了不合法的内存空间,这实际上是内存越界造成的错误值。
当我们不确定指针所指向的具体数据类型时,就可以使用void*类型来声明,当我们后续确定了具体类型之后,就可以使用强制类型转换来将void*类型转换为我们需要的具体类型。
接触过Java等具有泛型的面向对象编程语言的人,可能马上就会联想到泛型,是的,C语言没有泛型,但是利用void*指针的特点,我们可以使用一些技巧来模拟泛型编程。
再看一个示例
// 交换两个变量的值
void swap(int *a,int *b){
int tmp =*a;
*a = *b;
*b = tmp;
}
int main(){
int n = 6, l=8;
swap(&n, &l);
printf("n=%d l=%d\n",n,l);
return 0;
}
以上swap函数是交换两个int类型变量的值,如果需要交换char、short或double类型呢?岂不是每一种类型都需要写一个函数吗?像Java这样的编程语言存在泛型,我们可以定义泛型,而不需要在函数声明时指定具体类型,当调用的时候传入的是什么类型,函数就计算什么类型,我们看一下C语言如何实现
// 交换两个变量的值
void swap(void* a, void *b, int size){
// 申请一块指定大小的内存空间做临时中转
void *p = (void*)malloc(size);
// 内存拷贝函数,拷贝指定的字节数
memcpy(p, a, size);
memcpy(a, b, size);
memcpy(b, p, size);
// 释放申请的内存空间
free(p);
}
int main(){
int n = 6, l=8;
// 传入int型指针
swap(&n, &l,sizeof(int));
printf("n=%d l=%d\n",n,l);
// 传入short型指针
short x=10,y=80;
swap(&x, &y,sizeof(short));
printf("x=%d y=%d\n",x,y);
return 0;
}
打印结果:
n=8 l=6
x=80 y=10
欢迎关注我的公众号:编程之路从0到1
