航空公司客户价值分析-KMeans聚类
航空公司客户价值分析-KMeans聚类
import numpy as np
import pandas as pd
data = pd.read_csv(r'***\chapter7\demo\data\air_data.csv', encoding='utf-8')
data.head()
| MEMBER_NO | FFP_DATE | FIRST_FLIGHT_DATE | GENDER | FFP_TIER | WORK_CITY | WORK_PROVINCE | WORK_COUNTRY | AGE | LOAD_TIME | ... | ADD_Point_SUM | Eli_Add_Point_Sum | L1Y_ELi_Add_Points | Points_Sum | L1Y_Points_Sum | Ration_L1Y_Flight_Count | Ration_P1Y_Flight_Count | Ration_P1Y_BPS | Ration_L1Y_BPS | Point_NotFlight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 54993 | 2006/11/02 | 2008/12/24 | 男 | 6 | . | 北京 | CN | 31.0 | 2014/03/31 | ... | 39992 | 114452 | 111100 | 619760 | 370211 | 0.509524 | 0.490476 | 0.487221 | 0.512777 | 50 |
| 1 | 28065 | 2007/02/19 | 2007/08/03 | 男 | 6 | NaN | 北京 | CN | 42.0 | 2014/03/31 | ... | 12000 | 53288 | 53288 | 415768 | 238410 | 0.514286 | 0.485714 | 0.489289 | 0.510708 | 33 |
| 2 | 55106 | 2007/02/01 | 2007/08/30 | 男 | 6 | . | 北京 | CN | 40.0 | 2014/03/31 | ... | 15491 | 55202 | 51711 | 406361 | 233798 | 0.518519 | 0.481481 | 0.481467 | 0.518530 | 26 |
| 3 | 21189 | 2008/08/22 | 2008/08/23 | 男 | 5 | Los Angeles | CA | US | 64.0 | 2014/03/31 | ... | 0 | 34890 | 34890 | 372204 | 186100 | 0.434783 | 0.565217 | 0.551722 | 0.448275 | 12 |
| 4 | 39546 | 2009/04/10 | 2009/04/15 | 男 | 6 | 贵阳 | 贵州 | CN | 48.0 | 2014/03/31 | ... | 22704 | 64969 | 64969 | 338813 | 210365 | 0.532895 | 0.467105 | 0.469054 | 0.530943 | 39 |
5 rows × 44 columns
一、数据探索
explore = data.describe(percentiles = [], include = 'all').T
# percentils参数是指定计算多少的分位数,可不加该参数,此处是计算50%分位数,转置为了阅读方便
# describe()函数自动计算的的字段有count(非空值数),unique(唯一值数),top(频数最高者),freq(最高频数),mean(平均数),std, min, 50%, max
explore.head()
| count | unique | top | freq | mean | std | min | 50% | max | |
|---|---|---|---|---|---|---|---|---|---|
| MEMBER_NO | 62988 | NaN | NaN | NaN | 31494.5 | 18183.2 | 1 | 31494.5 | 62988 |
| FFP_DATE | 62988 | 3068 | 2011/01/13 | 184 | NaN | NaN | NaN | NaN | NaN |
| FIRST_FLIGHT_DATE | 62988 | 3406 | 2013/02/16 | 96 | NaN | NaN | NaN | NaN | NaN |
| GENDER | 62985 | 2 | 男 | 48134 | NaN | NaN | NaN | NaN | NaN |
| FFP_TIER | 62988 | NaN | NaN | NaN | 4.10216 | 0.373856 | 4 | 4 | 6 |
explore['null'] = len(data)-explore['count'] #生成一列空值数
explore.head()
| count | unique | top | freq | mean | std | min | 50% | max | null | |
|---|---|---|---|---|---|---|---|---|---|---|
| MEMBER_NO | 62988 | NaN | NaN | NaN | 31494.5 | 18183.2 | 1 | 31494.5 | 62988 | 0 |
| FFP_DATE | 62988 | 3068 | 2011/01/13 | 184 | NaN | NaN | NaN | NaN | NaN | 0 |
| FIRST_FLIGHT_DATE | 62988 | 3406 | 2013/02/16 | 96 | NaN | NaN | NaN | NaN | NaN | 0 |
| GENDER | 62985 | 2 | 男 | 48134 | NaN | NaN | NaN | NaN | NaN | 3 |
| FFP_TIER | 62988 | NaN | NaN | NaN | 4.10216 | 0.373856 | 4 | 4 | 6 | 0 |
#导入属性信息表
shuxing = pd.read_excel(r'***\chapter7\demo\data\客户信息属性说明.xls')
shuxing.head()
| 属性中文 | 属性英文 | 备注 | |
|---|---|---|---|
| 0 | 会员卡号 | MEMBER_NO | NaN |
| 1 | 入会时间 | FFP_DATE | 办理会员卡的开始的时间 |
| 2 | 第一次飞行日期 | FIRST_FLIGHT_DATE | NaN |
| 3 | 性别 | GENDER | NaN |
| 4 | 会员卡级别 | FFP_TIER | NaN |
#合并表
explore1 = pd.merge(explore, shuxing, left_index=True, right_on='属性英文' ,how ='left' )
explore1
| count | unique | top | freq | mean | std | min | 50% | max | null | 属性中文 | 属性英文 | 备注 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 62988 | NaN | NaN | NaN | 31494.5 | 18183.2 | 1 | 31494.5 | 62988 | 0 | 会员卡号 | MEMBER_NO | NaN |
| 1 | 62988 | 3068 | 2011/01/13 | 184 | NaN | NaN | NaN | NaN | NaN | 0 | 入会时间 | FFP_DATE | 办理会员卡的开始的时间 |
| 2 | 62988 | 3406 | 2013/02/16 | 96 | NaN | NaN | NaN | NaN | NaN | 0 | 第一次飞行日期 | FIRST_FLIGHT_DATE | NaN |
| 3 | 62985 | 2 | 男 | 48134 | NaN | NaN | NaN | NaN | NaN | 3 | 性别 | GENDER | NaN |
| 4 | 62988 | NaN | NaN | NaN | 4.10216 | 0.373856 | 4 | 4 | 6 | 0 | 会员卡级别 | FFP_TIER | NaN |
| 5 | 60719 | 3310 | 广州 | 9385 | NaN | NaN | NaN | NaN | NaN | 2269 | 工作地城市 | WORK_CITY | NaN |
| 6 | 59740 | 1185 | 广东 | 17507 | NaN | NaN | NaN | NaN | NaN | 3248 | 工作地所在省份 | WORK_PROVINCE | NaN |
| 7 | 62962 | 118 | CN | 57748 | NaN | NaN | NaN | NaN | NaN | 26 | 工作地所在国家 | WORK_COUNTRY | NaN |
| 43 | 62568 | NaN | NaN | NaN | 42.4763 | 9.88591 | 6 | 41 | 110 | 420 | NaN | AGE | NaN |
| 9 | 62988 | 1 | 2014/03/31 | 62988 | NaN | NaN | NaN | NaN | NaN | 0 | 观测窗口的结束时间 | LOAD_TIME | 选取样本的时间宽度,距离现在最近的时间。 |
| 10 | 62988 | NaN | NaN | NaN | 11.8394 | 14.0495 | 2 | 7 | 213 | 0 | 飞行次数 | FLIGHT_COUNT | 频数 |
| 11 | 62988 | NaN | NaN | NaN | 10925.1 | 16339.5 | 0 | 5700 | 505308 | 0 | 观测窗口总基本积分 | BP_SUM | 航空公里的里程就相当于积分,积累一定分数可以兑换奖品和免费里程。 |
| 12 | 62988 | NaN | NaN | NaN | 0 | 0 | 0 | 0 | 0 | 0 | 第一年精英资格积分 | EP_SUM_YR_1 | NaN |
| 13 | 62988 | NaN | NaN | NaN | 265.69 | 1645.7 | 0 | 0 | 74460 | 0 | 第二年精英资格积分 | EP_SUM_YR_2 | NaN |
| 14 | 62437 | NaN | NaN | NaN | 5355.38 | 8109.45 | 0 | 2800 | 239560 | 551 | 第一年总票价 | SUM_YR_1 | NaN |
| 15 | 62850 | NaN | NaN | NaN | 5604.03 | 8703.36 | 0 | 2773 | 234188 | 138 | 第二年总票价 | SUM_YR_2 | NaN |
| 16 | 62988 | NaN | NaN | NaN | 17123.9 | 20960.8 | 368 | 9994 | 580717 | 0 | 观测窗口总飞行公里数 | SEG_KM_SUM | NaN |
| 17 | 62988 | NaN | NaN | NaN | 12777.2 | 17578.6 | 0 | 6978.26 | 558440 | 0 | 观测窗口总加权飞行公里数(Σ舱位折扣×航段距离) | WEIGHTED_SEG_KM | NaN |
| 18 | 62988 | 731 | 2014/03/31 | 959 | NaN | NaN | NaN | NaN | NaN | 0 | 末次飞行日期 | LAST_FLIGHT_DATE | 最后一次飞行时间 |
| 19 | 62988 | NaN | NaN | NaN | 1.54215 | 1.787 | 0.25 | 0.875 | 26.625 | 0 | 观测窗口季度平均飞行次数 | AVG_FLIGHT_COUNT | NaN |
| 20 | 62988 | NaN | NaN | NaN | 1421.44 | 2083.12 | 0 | 752.375 | 63163.5 | 0 | 观测窗口季度平均基本积分累积 | AVG_BP_SUM | NaN |
| 21 | 62988 | NaN | NaN | NaN | 120.145 | 159.573 | 0 | 50 | 729 | 0 | 观察窗口内第一次乘机时间至MAX(观察窗口始端,入会时间)时长 | BEGIN_TO_FIRST | NaN |
| 22 | 62988 | NaN | NaN | NaN | 176.12 | 183.822 | 1 | 108 | 731 | 0 | 最后一次乘机时间至观察窗口末端时长 | LAST_TO_END | NaN |
| 23 | 62988 | NaN | NaN | NaN | 67.7498 | 77.5179 | 0 | 44.6667 | 728 | 0 | 平均乘机时间间隔 | AVG_INTERVAL | NaN |
| 24 | 62988 | NaN | NaN | NaN | 166.034 | 123.397 | 0 | 143 | 728 | 0 | 观察窗口内最大乘机间隔 | MAX_INTERVAL | NaN |
| 25 | 62988 | NaN | NaN | NaN | 540.317 | 3956.08 | 0 | 0 | 600000 | 0 | 观测窗口中第1年其他积分(合作伙伴、促销、外航转入等) | ADD_POINTS_SUM_YR_1 | NaN |
| 26 | 62988 | NaN | NaN | NaN | 814.689 | 5121.8 | 0 | 0 | 728282 | 0 | 观测窗口中第2年其他积分(合作伙伴、促销、外航转入等) | ADD_POINTS_SUM_YR_2 | NaN |
| 27 | 62988 | NaN | NaN | NaN | 0.319775 | 1.136 | 0 | 0 | 46 | 0 | 积分兑换次数 | EXCHANGE_COUNT | NaN |
| 28 | 62988 | NaN | NaN | NaN | 0.721558 | 0.185427 | 0 | 0.711856 | 1.5 | 0 | 平均折扣率 | avg_discount | NaN |
| 29 | 62988 | NaN | NaN | NaN | 5.76626 | 7.21092 | 0 | 3 | 118 | 0 | 第1年乘机次数 | P1Y_Flight_Count | NaN |
| 30 | 62988 | NaN | NaN | NaN | 6.07316 | 8.17513 | 0 | 3 | 111 | 0 | 第2年乘机次数 | L1Y_Flight_Count | NaN |
| 31 | 62988 | NaN | NaN | NaN | 5366.72 | 8537.77 | 0 | 2692 | 246197 | 0 | 第1年里程积分 | P1Y_BP_SUM | NaN |
| 32 | 62988 | NaN | NaN | NaN | 5558.36 | 9351.96 | 0 | 2547 | 259111 | 0 | 第2年里程积分 | L1Y_BP_SUM | NaN |
| 33 | 62988 | NaN | NaN | NaN | 265.69 | 1645.7 | 0 | 0 | 74460 | 0 | 观测窗口总精英积分 | EP_SUM | NaN |
| 34 | 62988 | NaN | NaN | NaN | 1355.01 | 7868.48 | 0 | 0 | 984938 | 0 | 观测窗口中其他积分(合作伙伴、促销、外航转入等) | ADD_Point_SUM | NaN |
| 35 | 62988 | NaN | NaN | NaN | 1620.7 | 8294.4 | 0 | 0 | 984938 | 0 | 非乘机积分总和 | Eli_Add_Point_Sum | NaN |
| 36 | 62988 | NaN | NaN | NaN | 1080.38 | 5639.86 | 0 | 0 | 728282 | 0 | 第2年非乘机积分总和 | L1Y_ELi_Add_Points | NaN |
| 37 | 62988 | NaN | NaN | NaN | 12545.8 | 20507.8 | 0 | 6328.5 | 985572 | 0 | 总累计积分 | Points_Sum | NaN |
| 38 | 62988 | NaN | NaN | NaN | 6638.74 | 12601.8 | 0 | 2860.5 | 728282 | 0 | 第2年观测窗口总累计积分 | L1Y_Points_Sum | NaN |
| 39 | 62988 | NaN | NaN | NaN | 0.486419 | 0.319105 | 0 | 0.5 | 1 | 0 | 第2年的乘机次数比率 | Ration_L1Y_Flight_Count | NaN |
| 40 | 62988 | NaN | NaN | NaN | 0.513581 | 0.319105 | 0 | 0.5 | 1 | 0 | 第1年的乘机次数比率 | Ration_P1Y_Flight_Count | NaN |
| 41 | 62988 | NaN | NaN | NaN | 0.522293 | 0.339632 | 0 | 0.514252 | 0.999989 | 0 | 第1年里程积分占最近两年积分比例 | Ration_P1Y_BPS | NaN |
| 42 | 62988 | NaN | NaN | NaN | 0.468422 | 0.338956 | 0 | 0.476747 | 0.999993 | 0 | 第2年里程积分占最近两年积分比例 | Ration_L1Y_BPS | NaN |
| 43 | 62988 | NaN | NaN | NaN | 2.72815 | 7.36416 | 0 | 0 | 140 | 0 | 非乘机的积分变动次数 | Point_NotFlight | NaN |
二、数据预处理
1、数据清洗
丢弃票价为空的记录
丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的记录
# (1)保留票价非空的数据 即'SUM_YR_1'不为空并且'SUM_YR_2'不为空
data_1 = data[(data['SUM_YR_1'].notnull())&(data['SUM_YR_2'].notnull())]
len(data_1) #剩下62299条数据
62299
# (2)保留票价非零的,或者,平均折扣率与总飞行公里数同时为0的
# 即'SUM_YR_1'不为0,或者'SUM_YR_2'不为0,或者平均折扣率与总飞行公里数同时为0 (即'SUM_YR_1'、'SUM_YR_2'都为0,同时平均折扣率与总飞行公里数同时为0,也保留)
index1 = data_1['SUM_YR_1']!=0
index2 = data_1['SUM_YR_2']!=0
index3 = (data_1['SEG_KM_SUM']==0)&(data_1['avg_discount']==0)
data_2 = data_1[(index1) | (index2) | (index3)] #或 的关系
len(data_2) #剩下62044条数据
62044
2、属性指标选取
根据航空公司客户价值LRFMC模型,选取与LRFMC指标相关的6个数据:
L客户关系长度:LOAD_TIME - FFP_DATE 其中LOAD_TIME为观测窗口的结束时间,FFP_DATE为入会时间(办理会员卡的开始的时间)
R消费时间间隔:LAST_TO_END 最后一次乘机时间至观察窗口末端时长
F客户在观测窗口内乘坐公司飞机的次数:FLIGHT_COUNT 飞行次数 单位:次
M客户在观测窗口内乘坐公司飞机的次数:SEG_KM_SUM 观测窗口总飞行公里数 单位:公里
C客户在观测窗口内乘坐舱位所对应的的折扣系数的平均值:avg_discount 平均折扣率
data_3 = data_2[['LOAD_TIME','FFP_DATE','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']].copy()
data_3.head()
#数据中Load_time和FFP_Date是字符串格式
| LOAD_TIME | FFP_DATE | LAST_TO_END | FLIGHT_COUNT | SEG_KM_SUM | avg_discount | |
|---|---|---|---|---|---|---|
| 0 | 2014/03/31 | 2006/11/02 | 1 | 210 | 580717 | 0.961639 |
| 1 | 2014/03/31 | 2007/02/19 | 7 | 140 | 293678 | 1.252314 |
| 2 | 2014/03/31 | 2007/02/01 | 11 | 135 | 283712 | 1.254676 |
| 3 | 2014/03/31 | 2008/08/22 | 97 | 23 | 281336 | 1.090870 |
| 4 | 2014/03/31 | 2009/04/10 | 5 | 152 | 309928 | 0.970658 |
data_3['LOAD_TIME'] = pd.to_datetime(data_3['LOAD_TIME'])
data_3['FFP_DATE'] = pd.to_datetime(data_3['FFP_DATE'])
data_3['L'] = data_3['LOAD_TIME'] - data_3['FFP_DATE']
data_3['R'] = data_3['LAST_TO_END']
data_3['F'] = data_3['FLIGHT_COUNT']
data_3['M'] = data_3['SEG_KM_SUM']
data_3['C'] = data_3['avg_discount']
data_3.head()
| LOAD_TIME | FFP_DATE | LAST_TO_END | FLIGHT_COUNT | SEG_KM_SUM | avg_discount | L | R | F | M | C | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2014-03-31 | 2006-11-02 | 1 | 210 | 580717 | 0.961639 | 2706 days | 1 | 210 | 580717 | 0.961639 |
| 1 | 2014-03-31 | 2007-02-19 | 7 | 140 | 293678 | 1.252314 | 2597 days | 7 | 140 | 293678 | 1.252314 |
| 2 | 2014-03-31 | 2007-02-01 | 11 | 135 | 283712 | 1.254676 | 2615 days | 11 | 135 | 283712 | 1.254676 |
| 3 | 2014-03-31 | 2008-08-22 | 97 | 23 | 281336 | 1.090870 | 2047 days | 97 | 23 | 281336 | 1.090870 |
| 4 | 2014-03-31 | 2009-04-10 | 5 | 152 | 309928 | 0.970658 | 1816 days | 5 | 152 | 309928 | 0.970658 |
为消除量纲影响,为后续聚类做准备,进行标准化
def data_Znorm(df, *cols):
df_n = df.copy()
for col in cols:
u = df_n[col].mean()
std = df_n[col].std()
df_n['Z'+col] = (df_n[col] - u) / std
return(df_n)
data_Z = data_Znorm(data_3, 'L','R','F','M','C')
data_Z.head()
| LOAD_TIME | FFP_DATE | LAST_TO_END | FLIGHT_COUNT | SEG_KM_SUM | avg_discount | L | R | F | M | C | ZL | ZR | ZF | ZM | ZC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2014-03-31 | 2006-11-02 | 1 | 210 | 580717 | 0.961639 | 2706 days | 1 | 210 | 580717 | 0.961639 | 1.435707 | -0.944948 | 14.034016 | 26.761154 | 1.295540 |
| 1 | 2014-03-31 | 2007-02-19 | 7 | 140 | 293678 | 1.252314 | 2597 days | 7 | 140 | 293678 | 1.252314 | 1.307152 | -0.911894 | 9.073213 | 13.126864 | 2.868176 |
| 2 | 2014-03-31 | 2007-02-01 | 11 | 135 | 283712 | 1.254676 | 2615 days | 11 | 135 | 283712 | 1.254676 | 1.328381 | -0.889859 | 8.718869 | 12.653481 | 2.880950 |
| 3 | 2014-03-31 | 2008-08-22 | 97 | 23 | 281336 | 1.090870 | 2047 days | 97 | 23 | 281336 | 1.090870 | 0.658476 | -0.416098 | 0.781585 | 12.540622 | 1.994714 |
| 4 | 2014-03-31 | 2009-04-10 | 5 | 152 | 309928 | 0.970658 | 1816 days | 5 | 152 | 309928 | 0.970658 | 0.386032 | -0.922912 | 9.923636 | 13.898736 | 1.344335 |
三、模型构建
1、客户聚类
采用K-Means聚类算法对客户数据尽心给客户分群,聚成5类(5类是按照经验判断出来的)
K-Means需要事先确定聚成几类,层次聚类不用,参考https://blog.csdn.net/LuohenYJ/article/details/79981269
函数参考https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
data_K = data_Z[['ZL','ZR','ZF','ZM','ZC']]
from sklearn.cluster import KMeans
kmodel = KMeans(n_clusters=5)
kmodel.fit(data_K)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=5, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
print(kmodel.cluster_centers_) #查看聚类中心
print(kmodel.labels_)
[[-0.31367829 1.68625847 -0.57401599 -0.53682019 -0.1733261 ]
[-0.70020646 -0.41488827 -0.16114258 -0.16095751 -0.25513154]
[ 0.48332845 -0.79938326 2.4832016 2.42472391 0.30863003]
[ 1.16066672 -0.37722119 -0.08691852 -0.09484404 -0.1559046 ]
[ 0.05184279 -0.00266813 -0.22680311 -0.23125407 2.19134701]]
[2 2 2 ... 1 0 0]
#生成聚类结果表,参考https://www.cnblogs.com/itdyb/p/5691958.html
r1=pd.Series(kmodel.labels_).value_counts() #得到每一类的聚类个数
r2=pd.DataFrame(kmodel.cluster_centers_) #得到聚类中心
print(r1)
print(r2)
1 24659
3 15740
0 12125
2 5336
4 4184
dtype: int64
0 1 2 3 4
0 -0.313678 1.686258 -0.574016 -0.536820 -0.173326
1 -0.700206 -0.414888 -0.161143 -0.160958 -0.255132
2 0.483328 -0.799383 2.483202 2.424724 0.308630
3 1.160667 -0.377221 -0.086919 -0.094844 -0.155905
4 0.051843 -0.002668 -0.226803 -0.231254 2.191347
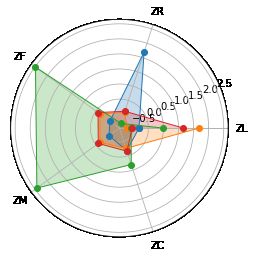
r=pd.concat([r1,r2],axis=1)
r.columns=['聚类个数'] + list(data_K.columns)
print(r)
# r.to_excel(resoutfile,index=False)
聚类个数 ZL ZR ZF ZM ZC
0 12125 -0.313678 1.686258 -0.574016 -0.536820 -0.173326
1 24659 -0.700206 -0.414888 -0.161143 -0.160958 -0.255132
2 5336 0.483328 -0.799383 2.483202 2.424724 0.308630
3 15740 1.160667 -0.377221 -0.086919 -0.094844 -0.155905
4 4184 0.051843 -0.002668 -0.226803 -0.231254 2.191347
#画雷达图
import matplotlib.pyplot as plt
labels = np.array(['ZL','ZR','ZF','ZM','ZC'])
angles = np.linspace(0, 2*np.pi, 5, endpoint=False) # 分割圆周长
angles = np.concatenate((angles, [angles[0]])) # 闭合
for i in range(4):
data_i = r2.iloc[i]
data_i.rename('i')
data_i = np.concatenate((data_i, [data_0[i]])) # 闭合
plt.polar(angles, data_i, 'o-', linewidth=1) #做极坐标系
plt.fill(angles, data_i, alpha=0.25)# 填充
plt.thetagrids(angles * 180/np.pi, labels) # 设置网格、标签
(,
)