Tensorflow object detection API--修改visualization_utils文件,裁剪并保存bounding box部分
任务描述:用Tensorflow object detection API检测出来的结果是一整张图片,想要把检测出的bounding box部分单独截取出来并保存
运行环境:spyder
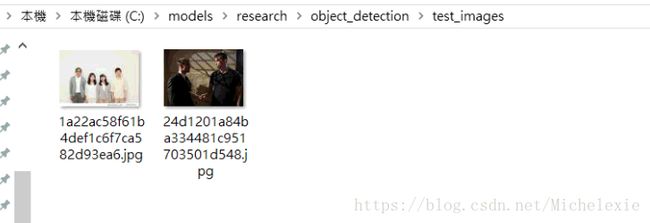
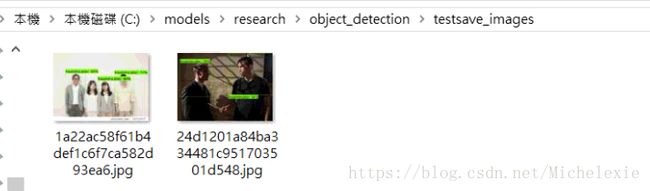
效果展示:
测试图片:test_images --> 检测图片:testsave_images --> 裁剪bounding box:test_cropped
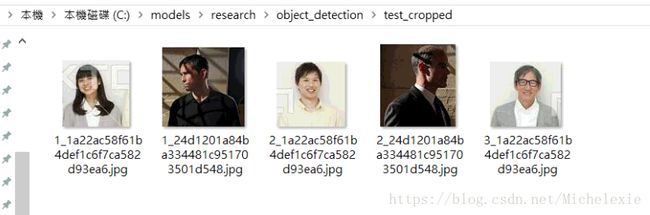
- 我的修改过后的test文件
# coding: utf-8
# # Object Detection Demo
# Welcome to the object detection inference walkthrough! This notebook will walk you step by step through the process of using a pre-trained model to detect objects in an image. Make sure to follow the [installation instructions](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md) before you start.
# # Imports
# In[19]:
from skimage import data_dir
import skimage.io as io
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if tf.__version__ < '1.4.0':
raise ImportError('Please upgrade your tensorflow installation to v1.4.* or later!')
# ## Env setup
# In[20]:
# This is needed to display the images.
#get_ipython().run_line_magic('matplotlib', 'inline') 我的电脑上这句如果不注释掉会报错
# ## Object detection imports
# Here are the imports from the object detection module.
# In[21]:
from utils import label_map_util
from utils import visualization_utils as vis_util #主要就是用到了utils目录下的visualization_utils文件
# # Model preparation
# ## Variables
#
# Any model exported using the `export_inference_graph.py` tool can be loaded here simply by changing `PATH_TO_CKPT` to point to a new .pb file.
#
# By default we use an "SSD with Mobilenet" model here. See the [detection model zoo](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md) for a list of other models that can be run out-of-the-box with varying speeds and accuracies.
# In[22]:
# What model to download.
MODEL_NAME = 'headshoulder0603' #我的模型名字
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'headshoulder.pbtxt') #我的模型相关文件
NUM_CLASSES = 1 #我的任务是检测头肩,只有一类
# ## Download Model
# ## Load a (frozen) Tensorflow model into memory.
# In[ ]:
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# ## Loading label map
# Label maps map indices to category names, so that when our convolution network predicts `5`, we know that this corresponds to `airplane`. Here we use internal utility functions, but anything that returns a dictionary mapping integers to appropriate string labels would be fine
# In[ ]:
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# ## Helper code
# In[23]:
#自己在实践中发现,图片经常需要在Image和numpy array两种格式中切换,这个函数就是将Image格式转换成numpy array
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# # Detection
# In[24]:
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with Aayour images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = os.getcwd()+'\\test_images' #存放测试图片的目录路径
os.chdir(PATH_TO_TEST_IMAGES_DIR)
TEST_IMAGE_PATHS = os.listdir(PATH_TO_TEST_IMAGES_DIR)
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
# In[25]:
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
# In[26]:
for image_path in TEST_IMAGE_PATHS:
image= Image.open(image_path) #注意这里的image_path是个路径,也就是说是个字符串str,下文会用到
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
image_path, #原有的代码没有这一行,但是我需要传递测试图片image的文件名给visualize_utils文件中,所以加上,对应的visualize_utils中的visualize_boxes_and_labels_on_image_array函数也要加上这个参数
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=1, #默认的框到粗细是8,但是实在太粗了
)#the width of bounding box,default is 8
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
#save_dir = TEST_IMAGE_PATHS + '{}.jpg'.format(image_path)
PATH_TO_TEST_IMAGES_1_DIR = r'C:\\models\\research\\object_detection\\testsave_images' #这里可能要加上r,不然可能会有编码ucf8错误
save_dir = os.path.join(PATH_TO_TEST_IMAGES_1_DIR, image_path)
vis_util.save_image_array_as_png(image_np,save_dir) #我将检测出来的图片保存在testsave_images文件夹下
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
- 修改过后的visualization_utils.py文件中 visualize_boxes_and_labels_on_image_array 函数
def visualize_boxes_and_labels_on_image_array(
image,
image_path, #我添加的,因为要用到测试图片的文件名
boxes,
classes,
scores,
category_index,
instance_masks=None,
instance_boundaries=None,
keypoints=None,
use_normalized_coordinates=False,
max_boxes_to_draw=20,
min_score_thresh=.5,
agnostic_mode=False,
line_thickness=1,
groundtruth_box_visualization_color='black',
skip_scores=False,
skip_labels=False,
):
"""Overlay labeled boxes on an image with formatted scores and label names.
This function groups boxes that correspond to the same location
and creates a display string for each detection and overlays these
on the image. Note that this function modifies the image in place, and returns
that same image.
Args:
image: uint8 numpy array with shape (img_height, img_width, 3)
boxes: a numpy array of shape [N, 4]
classes: a numpy array of shape [N]. Note that class indices are 1-based,
and match the keys in the label map.
scores: a numpy array of shape [N] or None. If scores=None, then
this function assumes that the boxes to be plotted are groundtruth
boxes and plot all boxes as black with no classes or scores.
category_index: a dict containing category dictionaries (each holding
category index `id` and category name `name`) keyed by category indices.
instance_masks: a numpy array of shape [N, image_height, image_width] with
values ranging between 0 and 1, can be None.
instance_boundaries: a numpy array of shape [N, image_height, image_width]
with values ranging between 0 and 1, can be None.
keypoints: a numpy array of shape [N, num_keypoints, 2], can
be None
use_normalized_coordinates: whether boxes is to be interpreted as
normalized coordinates or not.
max_boxes_to_draw: maximum number of boxes to visualize. If None, draw
all boxes.
min_score_thresh: minimum score threshold for a box to be visualized
agnostic_mode: boolean (default: False) controlling whether to evaluate in
class-agnostic mode or not. This mode will display scores but ignore
classes.
line_thickness: integer (default: 4) controlling line width of the boxes.
groundtruth_box_visualization_color: box color for visualizing groundtruth
boxes
skip_scores: whether to skip score when drawing a single detection
skip_labels: whether to skip label when drawing a single detection
Returns:
uint8 numpy array with shape (img_height, img_width, 3) with overlaid boxes.
"""
# Create a display string (and color) for every box location, group any boxes
# that correspond to the same location.
box_to_display_str_map = collections.defaultdict(list)
box_to_color_map = collections.defaultdict(str)
box_to_instance_masks_map = {}
box_to_instance_boundaries_map = {}
# box_to_keypoints_map = collections.defaultdict(list)
if not max_boxes_to_draw:
max_boxes_to_draw = boxes.shape[0]
for i in range(min(max_boxes_to_draw, boxes.shape[0])):
if scores is None or scores[i] > min_score_thresh:
box = tuple(boxes[i].tolist())
if instance_masks is not None:
box_to_instance_masks_map[box] = instance_masks[i]
if instance_boundaries is not None:
box_to_instance_boundaries_map[box] = instance_boundaries[i]
if scores is None:
box_to_color_map[box] = groundtruth_box_visualization_color
else:
display_str = ''
if not skip_labels:
if not agnostic_mode:
if classes[i] in category_index.keys():
class_name = category_index[classes[i]]['name']
else:
class_name = 'N/A'
display_str = str(class_name)
if not skip_scores:
if not display_str:
display_str = '{}%'.format(int(100*scores[i]))
else:
display_str = '{}: {}%'.format(display_str, int(100*scores[i]))
box_to_display_str_map[box].append(display_str)
if agnostic_mode:
box_to_color_map[box] = 'DarkOrange'
else:
box_to_color_map[box] = STANDARD_COLORS[
classes[i] % len(STANDARD_COLORS)]
#==================================================================================#
#===============crop bounding box images===========================================#
#==================================================================================#
t = 0 #这行记得是放在下面的循环体外的
for box, color in box_to_color_map.items():
ymin, xmin, ymax, xmax = box #前文已经得到bounding box的坐标,但是,由于使用了use_normalized_coordinates,将坐标归一化了,所以要映射回来
img = Image.fromarray(np.uint8(image))
im_width, im_height = img.size
print('im_width, im_height:', im_width, im_height)
new_xmin = int(xmin * im_width)
new_xmax = int(xmax * im_width)
new_ymin = int(ymin * im_height)
new_ymax = int(ymax * im_height)
# print('xmin,xmax,ymin,ymax:',xmin,xmax,ymin,ymax)
print('new_xmin,new_xmax,new_ymin,new_ymax:',new_xmin,new_xmax,new_ymin,new_ymax)
image_ = image[new_ymin:new_ymax,new_xmin:new_xmax] #将测试图片做裁剪,只剩bounding box部分,注意此处的image_命名,之前我写的是image,会出错。而且要注意的是,由于代码中用的是PIL图片格式,原点在左上角,而此处用numpy的方式裁剪图片,原点在左下角,所以x和y是反过来的。
plt.imshow(image_)
plt.show()
#
PATH_TO_crop_DIR = r'C:\\models\\research\\object_detection\\test_cropped' #保存的裁剪图片位置
image_ = Image.fromarray(np.uint8(image_))
t+=1
# image_.save( 'C:\\models\\research\\object_detection\\test_cropped\\cropped_images.jpg')
# image_.save(os.path.join(PATH_TO_crop_DIR, str(t)+'.jpg'))
image_.save(os.path.join(PATH_TO_crop_DIR, (str(t)+'_')+os.path.basename(image_path))) #这里用上了image_path,因为os.path.join需要字符串的参数,由于一张测试图片可能会检测出多个bounding box,所以在保存命名的时候加上了t这个参数(这一步应该会有更优雅的做法,但是我懒得去试了)
####################################################################################
# Draw all boxes onto image.把框和文件画到测试图片上
for box, color in box_to_color_map.items():
ymin, xmin, ymax, xmax = box
draw_bounding_box_on_image_array(
image,
ymin,
xmin,
ymax,
xmax,
color=color,
thickness=line_thickness,
display_str_list=box_to_display_str_map[box],
use_normalized_coordinates=use_normalized_coordinates)、
return image