二分图——匈牙利树
二分图——匈牙利树
- 前言
- 匈牙利树的基本概念
-
- 交替路
- 增广路
- 增广路的性质
- 增广路的定理
- 匈牙利树
-
- 啥是匈牙利树?
- 匈牙利树的算法流程
前言
我刚刚学了二分图,总觉得少点啥算法,果不其然,二分图竟然还有许多算法,这就是一个:匈牙利树。
匈牙利树的基本概念
先别急着要学匈牙利树,我们先了解一些关于他的基本概念。
交替路
交替路,就是从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边… 这样交替形成的一条路径。
增广路
设 M 为一个二分图 G 已经匹配边的集合,若 P 是图 G 中一条连通两个未匹配点的路径(起点在 X/Y 部,终点在 Y/X 部),且属 M 的边(匹配边)与不属 M 的边(非匹配边)在 P 上交替出现,则称 P 为相对 M 的一条增广路径。
由于增广路的第一条边是没有参与匹配的,第二条边参与了匹配,…,最后一条边没有参与匹配,并且起点和终点还没有被选择过,显然 P 有奇数条边。
简单来说,从一个未匹配点出发,走交替路,若途径另一未匹配点(除起点外),则这条交替路称为增广路。
如下图,左图中的一条增广路如右图所示,图中的匹配点均用红色标出
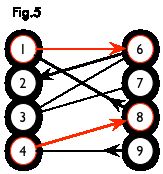
增广路的性质
- P 的长度必为奇数,第一条边和最后一条边都不属于 M,且两个端点分属两个集合,均未匹配。
- P 的非匹配边比匹配边多一条。
- P 经过取反操作可以得到一个更大的匹配 M’。
- M 为 G 的最大匹配当且仅当不存在相对于 M 的增广路径。
增广路的定理
由于增广路中间的匹配节点不存在其他相连的匹配边,因此交换增广路中的匹配边与非匹配边不会破坏匹配的性质。
由增广路性质可知,只要把增广路中的匹配边和非匹配边交换,交换后,图中的匹配边数目比原来多了 1 条。
因此,可以通过不停地找增广路来增加匹配中的匹配边和匹配点,找不到增广路时,即达到最大匹配,这就是增广路定理。
匈牙利树
扯了半天,终于要到重磅了:匈牙利树。
啥是匈牙利树?
匈牙利树一般由 DFS 构造(类似于 DFS 树),其是从一个未匹配点出发进行 DFS(必须走交替路),直到不能再扩展为止。
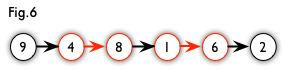
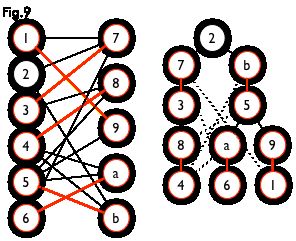
如下图,通过左侧的二分图,进行 DFS 可以得到右侧的树,但这棵树存在一叶结点为非匹配点(7号),而匈牙利树要求所有叶结点均为匹配点,故这棵树不是匈牙利树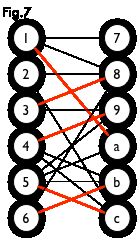
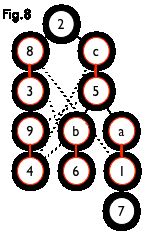
但若原图中不含 7 号结点,那么从 2 号结点出发就会得到一棵匈牙利树,如下图
匈牙利树的算法流程
匈牙利算法是用增广路来求最大匹配的算法,在求最大匹配前,需要先用 DFS 或 BFS 找到增广路。
从左边第 1 个点开始,挑选未匹配点进行搜索,寻找增广路
1)若经过一个未匹配点,则寻找成功,更新路径信息,匹配边数 +1,停止搜索。
2)若一直没有找到增广路,则不再从这个点开始搜索。事实上,此时搜索后会形成一棵匈牙利树。我们可以永久性地把它从图中删去,而不影响结果。
由于找到增广路后需要沿着路径更新匹配,因此需要一个结构来记录路径上的点,DFS 版本通过函数调用隐式地使用一个栈,而 BFS 版本使用 pre 数组(前驱结点)。
无论dfs还是bfs,时间复杂度都是 O ( V ⋅ E ) O(V·E) O(V⋅E)
(代码均为参考我自己不会写)
dfs:
int n,m;//x、y中结点个数,下标从0开始
bool vis[N];//vis[i]表示是否在交替路中
int link[N];//存储连接点
vector<int> G[N];//存边
bool dfs(int x){
for(int i=0;i<G[x].size();i++){
//对x的每个邻接点
int y=G[x][i];
if(!vis[y]){
//不在交替路中
vis[y]=true;//放入交替路
if(link[y]==-1 || dfs(link[y])){
//如果是未匹配点,说明交替路是增广路
link[y]=x;//交换路径
return true;//返回成功
}
}
}
return false;//不存在增广路,返回失败
}
int hungarian(){
int ans=0;//记录最大匹配数
memset(link,-1,sizeof(link));
for(int i=1;i<=n;i++){
//从左侧开始每个结点找一次增广路
memset(vis,false,sizeof(vis));
if(dfs(i))//找到一条增广路,形成一个新匹配
ans++;
}
return ans;
}
int main(){
while(scanf("%d%d",&n,&m)!=EOF){
memset(link,-1,sizeof(link));//全部初始化为未匹配点
for(int i=0;i<N;i++)
G[i].clear();
while(m--){
int x,y;
scanf("%d%d",&x,&y);
G[x].push_back(y);
G[y].push_back(x);
}
printf("%d\n", hungarian());//输出最大匹配数
}
return 0;
}
bfs:
int n,m;//左边点数,右边点数
int vis[N];//vis[i]表示是否在交替路中
int link[N];//存连接点
int pre[N];//存前驱结点
vector<int> G[N];//存边
queue<int> Q;
int hungarian(){
memset(vis,-1,sizeof(vis));
memset(pre,-1,sizeof(pre));
memset(link,-1,sizeof(link));
int ans=0;//记录最大匹配数
for(int i=1;i<=n;i++){
if(link[i]==-1){
//若点未匹配
pre[i]=-1;//没有前驱
while(!Q.empty())//清空队列
Q.pop();
Q.push(i);
bool flag=false;
while(!Q.empty() && !flag){
int x=Q.front();
for(int j=0;j<G[x].size();j++){
//对x的每个邻接点
if(!flag)//如果falg为真,则说明找到一未匹配点,不必继续下去
break;
int y=G[x][j];
if(vis[y]!=i){
//不在交替路中
vis[y]=i;//存入交替路
Q.push(link[y]);//交换路径
if(link[y]>=0)//在已匹配点中
pre[link[y]]=x;
else {
//找到未匹配点,交替路变增广路
flag=true;
int d=x;
int e=y;
while(d!=-1){
//找到一个未匹配点,无法构成匈牙利树,让所有点不断的往回更新,重选下一个
int temp=link[d];
link[d]=e;
link[e]=d;
d=pre[d];
e=temp;
}
}
}
}
Q.pop();
}
if(link[i]!=-1)//统计最大匹配数
ans++;
}
}
return ans;
}
int main(){
while(scanf("%d%d",&n,&m)!=EOF){
while(m--){
int x,y;
scanf("%d%d",&x,&y);
G[x].push_back(y);
G[y].push_back(x);
}
printf("%d\n", hungarian());//输出最大匹配数
}
return 0;
}
最大独立集
int n,m;
bool vis[N];
int link[N];
bool G[N][N];
bool dfs(int x){
for(int y=1;y<=m;y++){
if(G[x][y]&&!vis[y]){
vis[y]=true;
if(link[y]==-1 || dfs(link[y])){
link[y]=x;
return true;
}
}
}
return false;
}
int hungarian(){
int ans=0;
for(int i=1;i<=n;i++){
memset(vis,false,sizeof(vis));
if(dfs(i))
ans++;
}
return ans;
}
int main(){
while(scanf("%d%d",&n,&m)!=EOF&&(n+m)){
memset(link,-1,sizeof(link));
memset(G,true,sizeof(G));
while(m--){
int x,y;
scanf("%d%d",&x,&y);
G[x][y]=false;//不满足条件则连一条边
}
int mate=hungarian();//最大匹配数
int res=n-mate;//最大独立集
printf("%d\n",res);
}
return 0;
}
好了,我今天讲的内容结束了。您有什么问题可以来问我,我的blog有问题您也可以来提醒我改正