ubuntu - 安装kafka
kafka 安装启动过程
# 获取安装包
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.1/kafka_2.12-2.2.1.tgz
# 解压压缩包
sudo tar -xvf kafka_2.12-2.1.0.tgz -C kafka/
# 启动kafka
sudo /bin/kafka-server-start.sh /config/server.properties
# kafka提供的模拟收发消息的模板,可以简单的测试kafka的功能,测试后可以关闭
## 发送消息
sudo /usr/frankxulei/Kafka/kafka_2.12-2.1.0/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Java
## 监听消息
sudo /usr/frankxulei/Kafka/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Java --from-beginning
查看kafka是否注册到zookeeper
zookeeper 安装参考
# 在zookeeper的bin目录找到zkCli.sh 并运行它
./zkCli.sh
# 进入到zookeeper客户端中可以开始进行一下查询。
# 查询zookeeper的目录
ls /
-----------------------
[cluster, controller_epoch, controller, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
-----------------------
# 我们可以看到有一个brokers的目录。继续向下查询
ls /brokers
-----------------------
[ids, topics, seqid]
-----------------------
# 可以看到有一个ids的目录,继续向下查询
ls /brokers/ids
-----------------------
[1]
-----------------------
# 可以看到一个1的节点,我们显示一下这个节点是啥
get /brokers/ids/1
-----------------------
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://172.16.10.2:9092"],"jmx_port":-1,"host":"172.16.10.2","timestamp":"1561102811089","port":9092,"version":4}
-----------------------
一些猜想还未实践,这里的kafka的ids为什么是1呢,这里我们可以看看kafka的conf目录,里面有个server.properties,我们编辑它,发现第一行的的内容
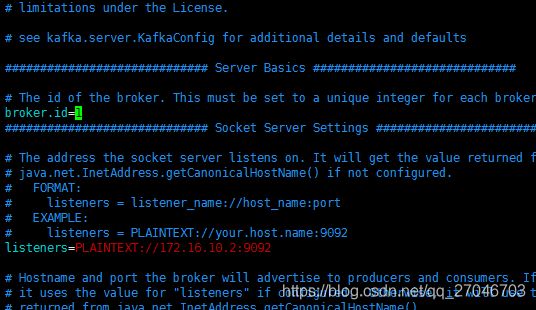
这里有个配置, broker.id=1, 这个配置还是比较可疑的,我们可以通过修改这个值,再注册到zookeeper查看结果。这里就留下一个悬念,这个配置可能会跟后面的集群有关,每个kafka实例需要配置不同的id,当然这也是猜测。
使用kafka
这里我通过一个简单的springboot项目使用他
pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
这里只需要注意我们的springboot工程的依赖低于2.1.x版本,目前kafka支持到2.0.x的springboot版本,高版本的springboot启动的话,会报出一个依赖找不到异常。
配置文件
server:
port: 8081
spring:
kafka:
bootstrap-servers: 172.16.10.2:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: kafka-demo
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
这里就简单的配置了一下kafka的链接地址,还有生产者消费者的序列化方式和反序列化方式,特别要注意的是consumer的group-id这个配置比较重要,这类似把我们的流量进行了分组,每个组可以是一类的流量,通过topic再对这个流量进行更细的分类。
kafkaService
@Service
public class KafkaService {
private Logger log = LoggerFactory.getLogger(getClass());
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
/**
* 发送消息
* @param message
*/
public void send(Object message){
log.info("message : {}",message);
kafkaTemplate.send("java",message);
}
/**
* 监听某个topic的流量
* @param record
*/
@KafkaListener(topics = "java")
public void subscription(ConsumerRecord<?, ?> record){
System.out.printf("topic = %s, offset = %d, value = %s \n", record.topic(), record.offset(), record.value());
}
}
这个Service配置没有太多需要解释的点。有一个思考的点, 这里的监听段也就是subscription我起初的设想是想通过一个线程池+传递参数的形式进行动态多topic的监听,因为配置topic的方式还是不够灵活,至于要实现这个的话,可能还需要熟悉一下源码再做尝试。
简单的运行使用
@RestController
public class TestController {
@Autowired
KafkaService kafkaService;
@RequestMapping(value = "/test",method = RequestMethod.GET)
public String testSend(@RequestParam String message){
kafkaService.send(message);
return "SUCCESS";
}
}
运行结果
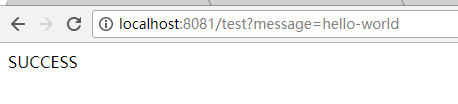

总结
这里已经简单的使用了一下kafka,更多的使用场景有待更新