0x00 环境及软件
1、系统环境
OS:Windows10_x64 专业版
2、所需软件或工具
- JDK1.8.0_131
- spark-2.3.0-bin-hadoop2.7.tgz
- hadoop-2.8.3.tar.gz
- scala-2.11.8.zip
- hadoop-common-2.2.0-bin-master.zip(主要使用里面的winutils.exe)
- IntelliJ IDEA(版本:2017.1.2 Build #IU-171.4249.32,built on April 21,2017)
- scala-intellij-bin-2017.1.20.zip(IntelliJ IDEA scala插件)
- apache-maven-3.5.0
0x01 搭建步骤
1、安装JDK
从http://www.oracle.com/technetwork/java/javase/downloads/index.html处下载相应版本的JDK安装文件,安装教程不再赘述,最终安装后的路径如下(由于之前就安装过JDK了,所以此处显示时间为2017年的):
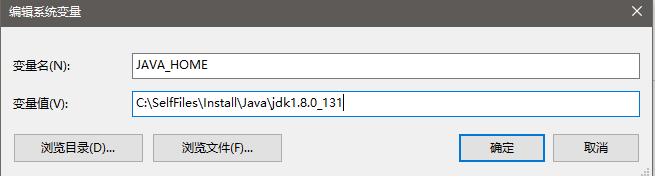
在环境变量中配置JDK信息,新建变量JAVA_HOME=C:\SelfFiles\Install\Java\jdk1.8.0_131,并在Path中添加JDK信息%JAVA_HOME%\bin,如下:
然后,打开一个命令行界面,验证JDK是否正确安装,如下:

说明JDK已经正常安装。
2、安装Scala
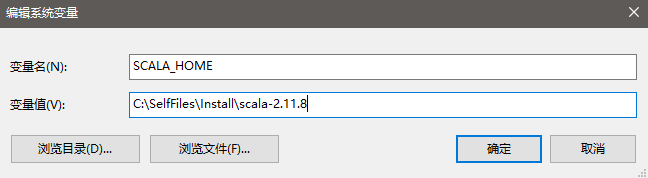
从https://www.scala-lang.org/download/all.html 处下载scala-2.11.8,然后解压并存放在本地电脑C:\SelfFiles\Install\scala-2.11.8处,然后配置环境变量并添加到Path变量中(%SCALA_HOME%\bin),类似于JDK的环境变量配置,如下:
然后,打开一个命令行界面验证是否安装成功,如下:

说明安装成功。
3、安装Hadoop
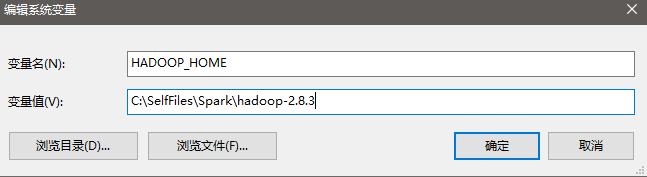
在http://hadoop.apache.org/releases.html下载hadoop-2.8.3,其实下一步“安装Spark”中我们选择下载的Spark版本为spark-2.3.0-bin-hadoop2.7,该版本Spark要求对应的Hadoop要在2.7及以上版本,所以此处我们选择Hadoop-2.8.3,选择其他更高的版本也是可以的。然后解压并存放在C:\SelfFiles\Spark\hadoop-2.8.3,并添加环境变量并添加到Path变量中(%HADOOP_HOME%和%HADOOP_HOME%\bin):
4、安装Spark
在http://spark.apache.org/downloads.html下载对应版本的Spark,此处我们下载的Spark版本信息如下:

下载到本地之后解压,并存放在目录C:\SelfFiles\Spark\spark-2.3.0-bin-hadoop2.7,然后添加环境变量和Path变量中(%SPARK_HOME%和%SPARK_HOME%\bin):

到此,单机版的Spark环境应该安装好了,此时我们在命令行界面中运行spark-shell来验证是否成功:
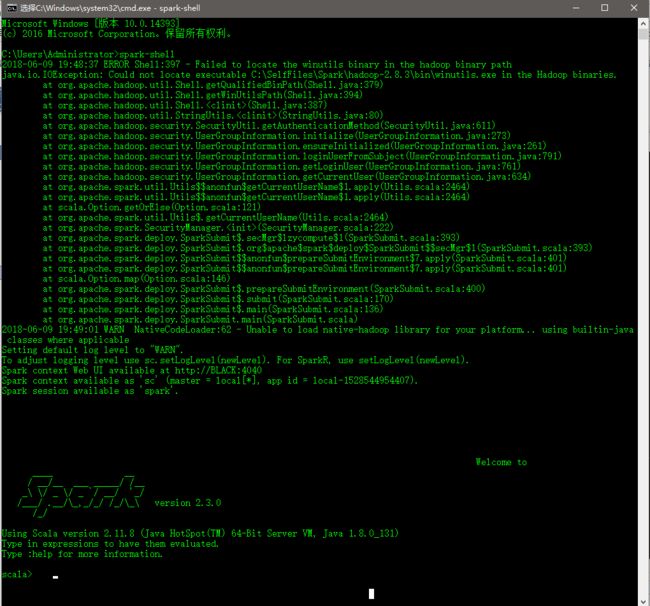
虽然最终进入到了spark shell中,但是中间报了一个错误,提示找不到C:\SelfFiles\Spark\hadoop-2.8.3\bin\winutils.exe文件,通过查看发现确实不存在该文件,此时我们需要从https://github.com/srccodes/hadoop-common-2.2.0-bin/tree/master/bin此处下载winutils.exe文件,并保存到本地C:\SelfFiles\Spark\hadoop-2.8.3\bin\目录下。然后再次运行spark-shell,结果如下:
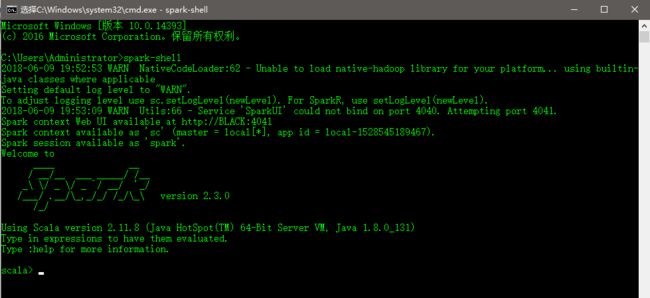
可以发现,已经不再报找不到winutils.exe文件的错误了,至于提示“WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform...”的错误,尝试了网上大多数的方法,都未解决,此处暂时未解决。
至此,Spark的环境算是基本搭建完成了。下面就开始搭建使用Scala的开发环境。
5、安装IDEA及scala插件
至于IDEA的下载和安装,此处不再赘述,读者可以去https://www.jetbrains.com/自行下载并安装。此处主要记录下scala插件的安装,IDEA的插件安装支持在线安装和离线安装,我们此处采用的是离线安装,即手动下载将要安装的scala插件,然后在IDEA中加载安装。
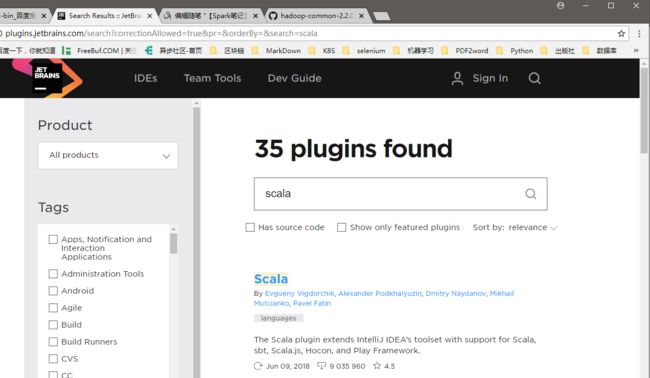
首先,我们从JetBrains官网上的插件库(http://plugins.jetbrains.com/)搜索scala插件,如下所示:
然后,点击第一个Scala进入下载界面,如下:
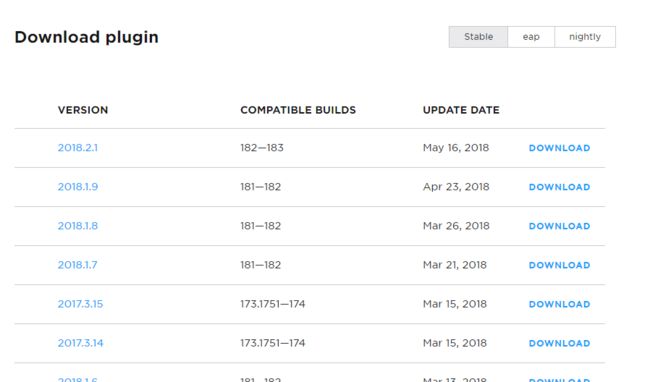
上面列举了兼容不同IDEA构建版本的scala插件,所以此处我们应该选择兼容自己所用IDEA版本的scala插件。从从前面的0x00一节知道,我这里使用的IDEA版本为2017.1.2 Build #IU-171.4249.32,built on April 21,2017,所以此时我们应该选择COMPATIBLE BUILDS一列的值范围包括171.4249.32的版本,可选择的比较多,我们随便选择一个下载即可,然后保存到本地的某个路径下,最好是保存在IDEA安装目录里的plugins目录下,我的保存路径为:C:\SelfFiles\Install\IntelliJIDEA\plugins\Scala\scala-intellij-bin-2017.1.20.zip。
接着,打开IDEA,选择File-->Settings...,可见如下界面:

然后单击右下角的“Install plugin from disk...”,选择刚刚我们保存的scala插件文件即可,安装成功后重启IDEA即可使用。
其实,如果网络比较好的话,使用在线安装更方便,此处也提一下在线安装的方法:在上面界面中,点击“Install JetBrains plugin...”或“Browse repositories...”,出现以下界面:

在上述界面搜索框中输入scala即可找到scala插件,然后点击右侧的“Install”安装即可。然后,我们可以通过新建项目来验证scala插件是否安装成功,如下:

6、配置maven
maven的下载和配置网络上面已经有很多教程,此处不再赘述。
7、编写测试代码
下面我们就是用IDEA来编写一个使用Spark进行数据处理的简单示例,该例子来自https://my.oschina.net/orrin/blog/1812035,并根据自己项目的名称做轻微修改,创建maven工程,项目结构如下所示:

pom.xml文件内容:
1 xml version="1.0" encoding="UTF-8"?> 2 <project xmlns="http://maven.apache.org/POM/4.0.0" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0modelVersion> 6 7 <groupId>com.hackhan.demogroupId> 8 <artifactId>jackleeartifactId> 9 <version>1.0-SNAPSHOTversion> 10 11 12 <properties> 13 <spark.version>2.3.0spark.version> 14 <scala.version>2.11scala.version> 15 properties> 16 17 <dependencies> 18 <dependency> 19 <groupId>org.apache.sparkgroupId> 20 <artifactId>spark-core_${scala.version}artifactId> 21 <version>${spark.version}version> 22 dependency> 23 <dependency> 24 <groupId>org.apache.sparkgroupId> 25 <artifactId>spark-streaming_${scala.version}artifactId> 26 <version>${spark.version}version> 27 dependency> 28 29 <dependency> 30 <groupId>org.apache.sparkgroupId> 31 <artifactId>spark-sql_${scala.version}artifactId> 32 <version>${spark.version}version> 33 dependency> 34 <dependency> 35 <groupId>org.apache.sparkgroupId> 36 <artifactId>spark-hive_${scala.version}artifactId> 37 <version>${spark.version}version> 38 dependency> 39 <dependency> 40 <groupId>org.apache.sparkgroupId> 41 <artifactId>spark-mllib_${scala.version}artifactId> 42 <version>${spark.version}version> 43 dependency> 44 45 dependencies> 46 47 <build> 48 <plugins> 49 50 <plugin> 51 <groupId>org.scala-toolsgroupId> 52 <artifactId>maven-scala-pluginartifactId> 53 <version>2.15.2version> 54 <executions> 55 <execution> 56 <goals> 57 <goal>compilegoal> 58 <goal>testCompilegoal> 59 goals> 60 execution> 61 executions> 62 plugin> 63 64 <plugin> 65 <groupId>org.apache.maven.pluginsgroupId> 66 <artifactId>maven-compiler-pluginartifactId> 67 <version>3.6.0version> 68 <configuration> 69 <source>1.8source> 70 <target>1.8target> 71 configuration> 72 plugin> 73 74 <plugin> 75 <groupId>org.apache.maven.pluginsgroupId> 76 <artifactId>maven-surefire-pluginartifactId> 77 <version>2.19version> 78 <configuration> 79 <skip>trueskip> 80 configuration> 81 plugin> 82 83 plugins> 84 build> 85 86 project>
WordCount.scala文件内容如下:
1 package com.hackhan.demo 2 3 import org.apache.spark.{SparkConf, SparkContext} 4 5 6 /** 7 * 8 * @author migu-orrin on 2018/5/3. 9 */ 10 object WordCount { 11 def main(args: Array[String]) { 12 13 /** 14 * SparkContext 的初始化需要一个SparkConf对象 15 * SparkConf包含了Spark集群的配置的各种参数 16 */ 17 val conf=new SparkConf() 18 .setMaster("local")//启动本地化计算 19 .setAppName("WordCount")//设置本程序名称 20 21 //Spark程序的编写都是从SparkContext开始的 22 val sc=new SparkContext(conf) 23 //以上的语句等价与val sc=new SparkContext("local","testRdd") 24 val data=sc.textFile("C:/SelfFiles/Spark/test/wordcount.txt")//读取本地文件 25 var result = data.flatMap(_.split(" "))//下划线是占位符,flatMap是对行操作的方法,对读入的数据进行分割 26 .map((_,1))//将每一项转换为key-value,数据是key,value是1 27 .reduceByKey(_+_)//将具有相同key的项相加合并成一个 28 29 result.collect()//将分布式的RDD返回一个单机的scala array,在这个数组上运用scala的函数操作,并返回结果到驱动程序 30 .foreach(println)//循环打印 31 32 Thread.sleep(10000) 33 result.saveAsTextFile("C:/SelfFiles/Spark/test/wordcountres") 34 println("OK,over!") 35 } 36 }
其中处理的目标文件C:/SelfFiles/Spark/test/wordcount.txt的内容为(你也可以自己随意填写):
this is my first test.
运行结果如下:
IDEA打印结果:

0x02 总结
因本人也是刚刚接触Spark,对其中的一些原理还不是很了解,此处写此博文只为搭建环境的一个记录,后面随着学习的深入,可以逐渐了解其中的原理。以后也许会考虑搭建集群环境!
在此,感谢网友为知识和技术传播做出的贡献!
0x03 参考内容
- https://my.oschina.net/orrin/blog/1812035
- https://blog.csdn.net/songhaifengshuaige/article/details/79480491