MySQL关键字说明及示例
MySQL关键字讲解
- 函数关键字:
-
- MySQL时间校正:北京时间
- length: 返回长度
- upper: 小写 -> 大写
- lower: 大写 -> 小写
- substr: 截取字符串
- concat: 拼接字符串
- repeat:返回 str 重复 x 次的结果
- left: 自左向右截取字符串
- right: 自右向左截取字符串
- instr: 返回索引
- trim: 去掉左右两端的指定字符(默认去空格)
- lpad:左填充,rpad:右填充
- replace:替换
- distinct: 去重
- 聚合函数
-
- sum: 求和
- avg:平均值
- max:最大值
- min:最小值
- count:结果集个数
- 日期关键字
-
- now:返回当前日期+时间(开始时获得)
- sysdate: 返回当前日期+时间(动态获得)
- year:返回年
- month:返回月
- day:返回日
- date_format:将日期转换成字符
- curdate:返回当前日期
- str_to_date:将字符转换成日期
- curtime:返回当前时间
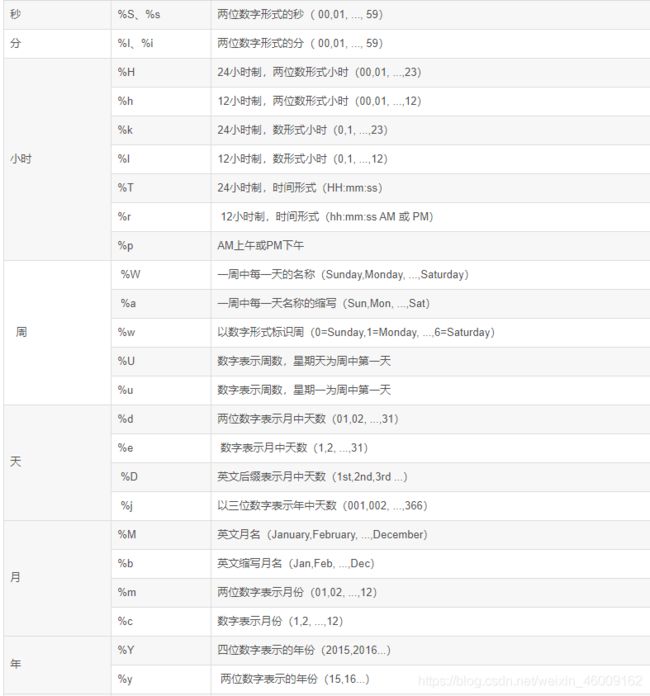
- hour:小时
- minute:分钟
- second:秒
- datediff: 返回两个日期相差的天数
- date_add: 对某个日期加上(或减去)几天、几个小时、几分钟、几秒钟等操作。
- 数学函数
-
- round: 四舍五入
- ceil:向上取整,floor:向下取整
- truncate:截断数字,保留小数点后一位
- mod: 取5除2的余数
- curdate: 当前日期
- case: 条件判断语句
-
- case + select: 查询应用
- case + update: 更新应用(可用于批量更新不同value的数据)
- 连接查询
-
- union : 连接两个查询sql的结果集 对结果去重
- union all :不对结果去重
- 内连接 ★):inner
- 外连接 join on
- 左外(★):left 【outer】
- 右外(★):right 【outer
- 全外:full【outer】
- 交叉连接:cross
- 子查询
-
- in & exists : 适合于外表大而内表小的情况
- exists : 相关子查询,检测 行 的存在。
- from后面支持表子查询
- 列子查询 (结果集只有一列多行)
- 行子查询 (结果集有一行多列)
- 表子查询(结果集一般为多行多列)
- 其他:
-
- on duplicate key update:避免重复插入数据
- group by:分组查询
- having:对分组后的结果进行二次筛选
- find_in_set : 精准匹配集合中元素
- **题外话:
函数关键字:
MySQL时间校正:北京时间
执行下面sql语句,完成后需重新连接数据库方可正常显示
set persist time_zone='+8:00';
length: 返回长度

upper: 小写 -> 大写

lower: 大写 -> 小写

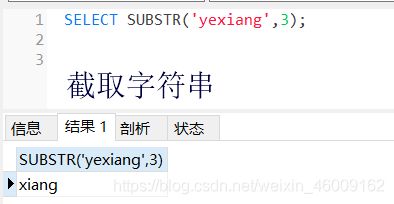
substr: 截取字符串
concat: 拼接字符串

repeat:返回 str 重复 x 次的结果

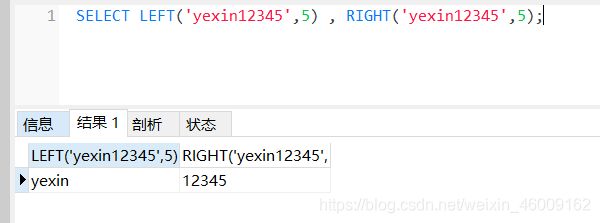
left: 自左向右截取字符串
right: 自右向左截取字符串
instr: 返回索引

trim: 去掉左右两端的指定字符(默认去空格)
trim:

lpad:左填充,rpad:右填充

replace:替换

distinct: 去重

聚合函数
sum: 求和
avg:平均值
max:最大值
min:最小值
count:结果集个数

日期关键字
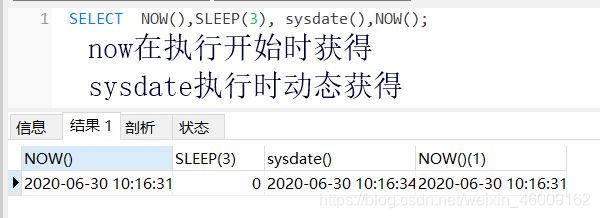
now:返回当前日期+时间(开始时获得)
sysdate: 返回当前日期+时间(动态获得)
year:返回年
month:返回月
day:返回日
date_format:将日期转换成字符
图片来自

curdate:返回当前日期
str_to_date:将字符转换成日期
curtime:返回当前时间
hour:小时
minute:分钟
second:秒
datediff: 返回两个日期相差的天数

date_add: 对某个日期加上(或减去)几天、几个小时、几分钟、几秒钟等操作。

数学函数
round: 四舍五入

ceil:向上取整,floor:向下取整

truncate:截断数字,保留小数点后一位

mod: 取5除2的余数

curdate: 当前日期

case: 条件判断语句
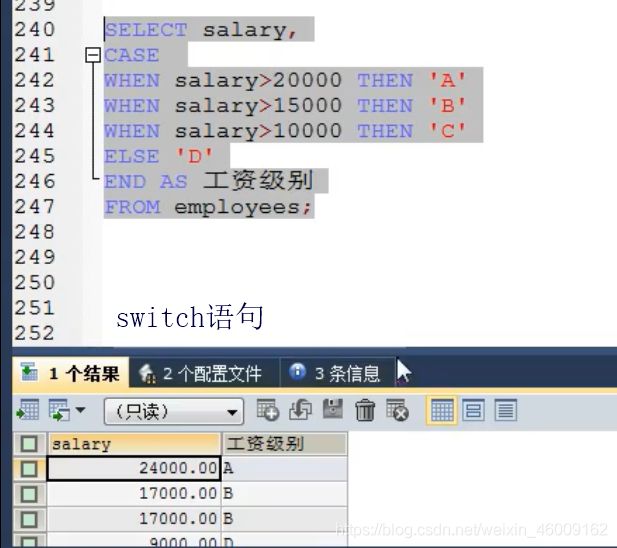
case + select: 查询应用
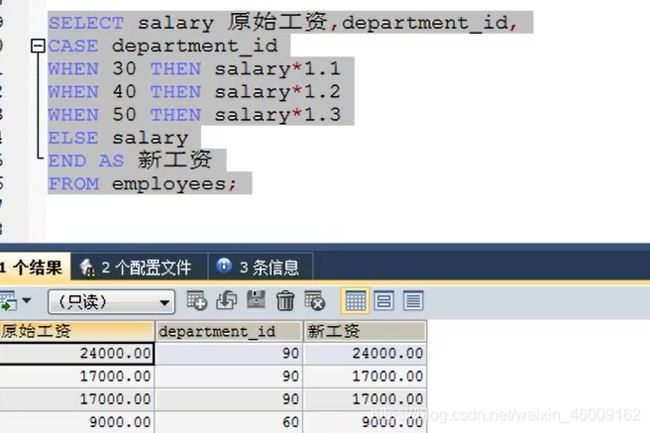
case + update: 更新应用(可用于批量更新不同value的数据)
UPDATE sys_dept
SET ancestors =
CASE
dept_id
WHEN 111 THEN
'0,100,101,103,108'
WHEN 112 THEN
'0,100,101,103,108'
END
WHERE
dept_id IN ( 111, 112 );
mybatis 框架下 mapper.xml 中的配置方法
<update id="updateDeptChildren" parameterType="java.util.List">
update sys_dept set ancestors =
<foreach collection="depts" item="item" index="index"
separator=" " open="case dept_id" close="end">
when #{
item.deptId} then #{
item.ancestors}
</foreach>
where dept_id in
<foreach collection="depts" item="item" index="index"
separator="," open="(" close=")">
#{
item.deptId}
</foreach>
</update>
连接查询
union : 连接两个查询sql的结果集 对结果去重
union all :不对结果去重
注意:
1:两个结果集的列必须相同(列名和列数)
2:sql语句中不能存在排序字段(order by)
SELECT l.*
FROM
left_table l
UNION ALL
SELECT r.*
FROM
right_table r

#二、sq199语法
日/*
语法:
select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where 筛选条件】
【group by分组】
【having筛选条件】
【order by 排序列表】
分类:
内连接 ★):inner

外连接 join on
左外(★):left 【outer】
右外(★):right 【outer
全外:full【outer】
交叉连接:cross

子查询
含义:
出现在其他语句中的select语句,称为子查询或内查询
外部的查询语句,称为主查询或外查询
in & exists : 适合于外表大而内表小的情况

exists : 相关子查询,检测 行 的存在。
适合于外表小而内表大的情况。
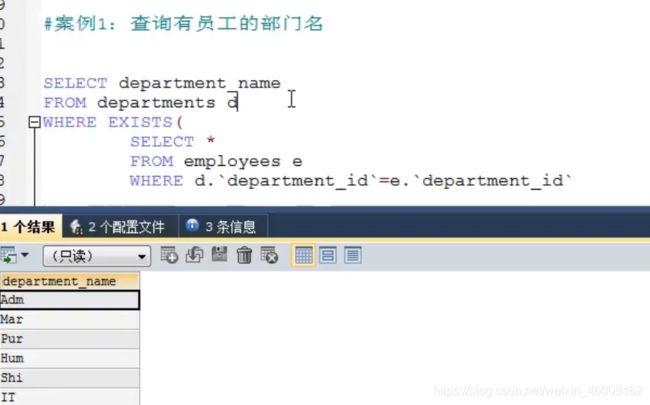
分类:
按子查询出现的位置:
select后面:
仅仅支持标量子查询
from后面支持表子查询
from后面的子查询是将结果集当作一张表来查询
注意:该表必须起别名

I where或having后面:
标量子查询 (单行)
列子查询 (多行)
行子查询
exists后面(相关子查询)
表子查询
按结果集的行列数不同:
标量子查询 (结果集只有一行一列)
列子查询 (结果集只有一列多行)
行子查询 (结果集有一行多列)
表子查询(结果集一般为多行多列)
其他:
on duplicate key update:避免重复插入数据
默认添加数据,主键终突则将添加改为更新,需将更新字段(key=value)放在该字段后面
-- 执行
INSERT INTO user_admin_t (_id,password)
VALUES ('1','第一次插入的密码')

INSERT INTO user_admin_t (_id,password)
VALUES ('1','第一次插入的密码')
ON DUPLICATE KEY UPDATE
_id = 'UpId',
password = 'upPassword';
受影响的行: 2
时间: 0.131s
![]()
总结:ON DUPLICATE KEY UPDATE能够让我们便捷的完成重复插入的开发需求,但它是Mysql的特有语法,使用时应多注意主键和插入值是否是我们想要插入或修改的key、Value。
group by:分组查询
以下面住宅表为例,现根据户型(type)统计每种户型存在几户

分组查询后结果
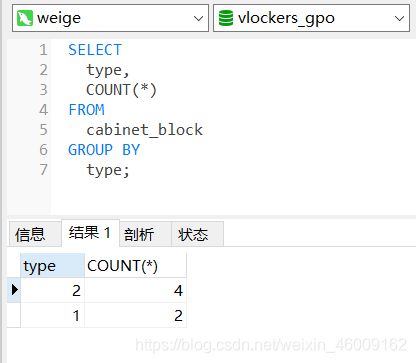
having:对分组后的结果进行二次筛选
筛选上表中户型数量大于2的结果
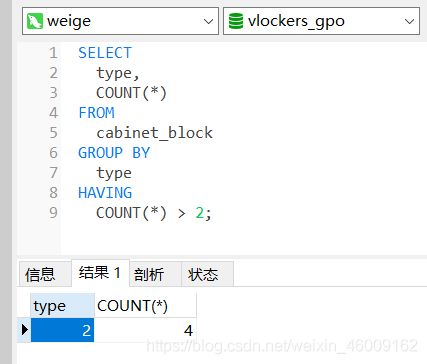
find_in_set : 精准匹配集合中元素
与假如使用like匹配‘%2%’,会查到‘2’,‘32’,‘52’
find_in_set:会把字符串以逗号间隔拆分成单个独立的元素,进行精准匹配
select * from sys_dept where find_in_set(id, '1,2,32,4,52');
**题外话:
分享下本人的学习经验,个人认为要学习一个关键字,一个知识点,或者一门技术要按如下顺序了解:
1:它是做什么的
2:它是怎么做到的(内部的原理,逻辑)
3:我该如何使用它(用法)
4:我该在什么场景下使用它(结合实际项目的业务场景分析,它在其中所起到的作用)**