Hadoop之MapReduce简介与统计字符个数demo
1.概述
- MapReduce是Hadoop提供的一套基于YARN的,用于进行分布式计算的框架
- MapReduce是Doug根据Google的MapReduce来实现的
- MapReduce将整个计算过程拆分为2个阶段:Map(映射)阶段和Reduce(规约)阶段
2.MapReduce的执行流程
Map阶段
2.1需要处理的文件在MapReduce中会先进行切片,每一个切片会交给一个MapTask来处理
2.2MapTask拿到切片之后,默认会对这个切片进行按行读取并按行处理
2.3所有的MapTask的处理逻辑都是一样的,只是数据不同而已
Reduce阶段
2.4 Map阶段执行完成过后,在Reduce阶段,会将相同的键对应的值放一块,这是个分组的过程
2.5执行结束后文件输出可以指定到HDFS也可以存储到其他路径,但是一般都存储到HDFS
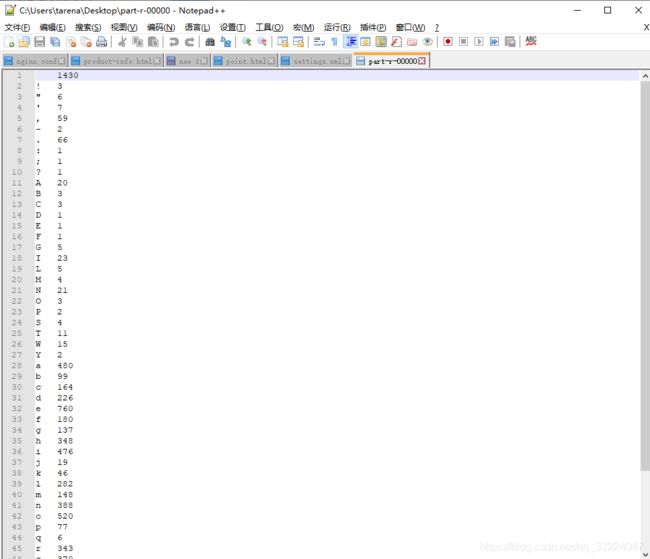
3.统计字符个数demo
3.1因为 hadoop 默认不支持windows依赖,需要安装
![]()
安装配置过程这里不做赘述
3.2Mapper中的四个参数说明
在MapReduce中,要求数据能够被序列化。MapReduce针对常用类型,提供了序列化形式
- KEYIN - 输入的键的类型。默认情况下,指的是行偏移量
- VALUEIN - 输入的值的类型。默认情况下,指的是读取的一行数据
- KEYOUT - 输出的键的类型。当前案例中,键是字符
- VALUEOUT - 输出的值的类型。当前案例中,值是次数
补充:
a.Integer 长度不够 ,换成Long,但是在MapReduce中要求数据能够被序列化,所以采用了MapReduce提供的LongWritable
b.MapReduce中没有针对char提供序列化数据类型,所以按照Text处理
c.最后一个参数如果量不大可以用IntWritable ,量大就用LongWritable
d.因为程序的入口是main方法,需要执行的话需要提供一个入口类Driver,@Test中虽然也有main,但是@Test需要满足3无条件,这里不适用
e.在MapReduce中一定注意导包前看一下是否是正确的包
3.3 代码示例
CharCountMapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// 在MapReduce中,要求数据能够被序列化
// MapReduce针对常用类型,提供了序列化形式
// KEYIN - 输入的键的类型。默认情况下,指的是行偏移量
// VALUEIN - 输入的值的类型。默认情况下,指的是读取的一行数据
// KEYOUT - 输出的键的类型。当前案例中,键是字符
// VALUEOUT - 输出的值的类型。当前案例中,值是次数
public class CharCountMapper
extends Mapper {
private LongWritable count = new LongWritable(1);
// 需要覆盖map方法,指定处理逻辑
// map方法默认是进行按行处理
// key:行的字节偏移量
// value:读取到的一行数据
// context:环境参数。可以数据传递给Reduce
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 拿到一行数据 - value
// 考虑将这一行中的每一个字符拆分出来
char[] cs = value.toString().toCharArray();
// hello -> h e l l o
// h:1 e:1 l:2 o:1
// h:1 e:1 l:1 l:1 o:1
for (char c : cs) {
context.write(new Text(c + ""), count);
}
}
}
CharCountReducer类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
// KEYIN,VALUEIN - 输入的键值类型。Reducer的数据是从Mapper中获取的
// 那么就意味着Mapper的输出类型就是Reducer的输入类型
// KEYOUT,VALUEOUT - 输出的键值类型。当前案例中,输出的是字符对应的总次数
public class CharCountReducer
extends Reducer {
// 将处理逻辑覆盖到reduce方法
// key - 键 - map输出的键
// values - 一组数据
// 在Reduce刚开始的时候,会将相同的键对应的值放到一组去
// 然后需要对这一组中的数据进行遍历处理 - 为了方便遍历,将这一组数据生成了一个迭代器
// context - 环境。可以这个参数将结果写出到指定位置
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// key = 'a'
// values = {1,1,1,1,1,1,1...}
long sum = 0;
//基本类型和序列化类型不匹配,不能直接加--取出在加
// 遍历迭代器来求和
for (LongWritable val : values) {
sum += val.get();
}
// 最终要将结果写出
context.write(key, new LongWritable(sum));
}
}
CharCountDriver类(作为入口类)、
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
// 入口类
public class CharCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 创建环境配置
Configuration conf = new Configuration();
// 向YARN申请任务
Job job = Job.getInstance(conf);
// 设置入口类
job.setJarByClass(CharCountDriver.class);
// 设置Mapper类
job.setMapperClass(CharCountMapper.class);
// 设置Reducer类
job.setReducerClass(CharCountReducer.class);
// 设置Mapper的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置Reducer的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输入路径
FileInputFormat.addInputPath(job,
new Path("hdfs://hadoop01:9000/txt/characters.txt"));
// 设置输出路径 - 要求输出路径必须不存在
FileOutputFormat.setOutputPath(job,
new Path("hdfs://hadoop01:9000/result/charcount"));
// 提交任务
job.waitForCompletion(true);
}
}运行成功
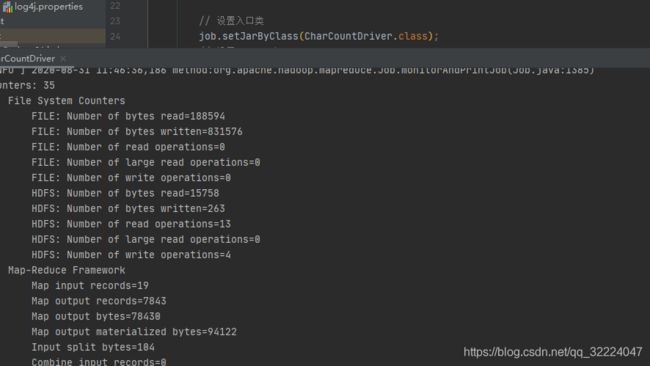
运行成功后可以通过HDFS Explorer工具查看HDFS上生成的文件
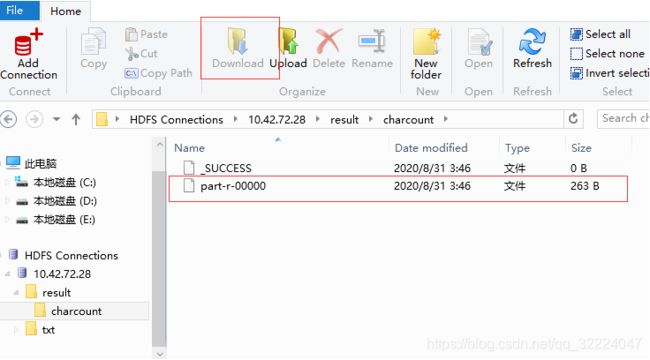
可以下载到本地查看文件中的统计内容