Hibernate 优化技术之抓取策略(Fetching strategies)
一、前言
转载请标明出处:http://blog.csdn.net/wlwlwlwl015/article/details/42705585
使用hibernate一年多了,一直觉得他是一个很好用的持久层框架,在处理含有多个复杂的关联关系的数据表时,hibernate提供的各种关联映射可以让我们用少量的代码快速、便捷的去维护各种外键关系,当然他的核心还是允许我们以“面向对象”的方式去操作数据表,因为我们的Java语言就是面向对象的,所以我们使用ORM的持久层框架应该更容易理解和上手,他还有许许多多的优点,比如我们使用HQL可以无视数据库的移植等等,同样的,这样一系列的封装也就导致了性能的下降,所以我们在实际项目中使用hibernate的话,优化是必不可少的工作,所以从本篇blog开始我就总结一下我所用到的和了解到的hibernate优化技术,首先是抓取策略。
二、抓取策略详解与应用
在hibernate官方文档的第21章中,我们可以看到“性能提升”首先介绍的就是抓取策略,

下面看一下文档中对抓取策略的概述:“当应用程序需要在(Hibernate实体对象图的)关联关系间进行导航的时候,Hibernate可以使用抓取策略获取关联对象。抓取策略可以在O/R映射的配置文件中声明,也可以在特定的HQL或条件查询(Criteria Query)中重载声明”。
简单分析一下,实体间的关联关系导航,举个例子,学生和班级是多对一的关系,我要通过学生对象去查找该学生所对应的班级对象,这就是一个最简单的导航。下面就通过“学生”和“班级”这两个实体通过代码来演示一下如何使用抓取策略。
Student:
package com.wl.entity;
import java.util.Date;
public class Student {
private int id;
private String name;
private String sex;
private Date birthday;
private Classroom cla;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
public Classroom getCla() {
return cla;
}
public void setCla(Classroom cla) {
this.cla = cla;
}
}
Classroom:
package com.wl.entity;
public class Classroom {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Classroom.hbm.xml:
hibernate中有一条best practice就是尽量少的使用双向关联,所以这里我就通过最常用的单向多对一来举例说明了。这个多对一的例子相信我们在初学hibernate的时候就已经很了解了,在为数据库插入了少量测试数据之后,现在我写了这样的一个测试方法:
@Test
public void testFetchLoad() {
Session session = HibernateUtil.oepnSession();
session.beginTransaction();
Student stu = (Student) session.load(Student.class, 1);
System.out.println(stu.getName() + "," + stu.getCla().getName());
}很简单,测试了一下load,打印了学生自身的属性和其所关联的班级的属性,这里Hibernate就已经使用了抓取测试,至于是什么抓取策略,我们看一下console中打印的sql语句:
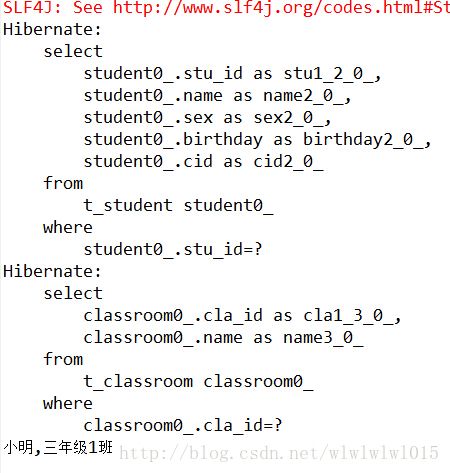
可以看到总共发了2条sql语句,一条查询学生,一条查询班级。很明显这是类似于延迟加载的一种策略,因为他并没有一次性的为我们把学生和班级一起查询出来,而是用到哪个才查询哪个。下面我们在Hibernate提供的策略里面找着看,

经过这4种策略的对比,不难发现,第二种查询抓取(Select fetching)正是我们上面的例子中用到的抓取策略,可是我们并没有进行配置,所以说:基于O/R映射文件配置关联关系的情况下,导航关联对象默认使用的是查询抓取(select fetching),所以说我们在

可以看到,我只查询了学生的Name,但是却又发了1条SQL语句去查询班级,这就是禁止了延迟抓取的结果,会让我们的延迟加载失效,很显然这种情况无论何时都不应当出现,所以一般我们不会去禁止select fetching中的延迟抓取。
看完了第一种抓取策略,再看一下连接抓取(Join fetching),官方文档中的定义是:Hibernate通过在SELECT语句使用OUTER JOIN(外连接)来获得对象的关联实例或者关联集合。最开头也说了,抓取策略可以在O/R映射文件中配置,也可以在HQL中设置,那么现在就以这两种方式分别说一下Join fetching的用法,依旧是第一个例子,load学生对象后打印学生Name和班级Name。
首先是基于配置文件的设置,我们可以在Student的配置文件中的

果然就如Join fetching的介绍一样,这里使用了一个left outer join自动关联查询了学生和班级,一条SQL就得到了结果,所以这种情况下使用和Select fetching相比,一个发1条SQL语句,一个发2条SQL语句,很明显我们应该使用Join fetching来处理。
接下来介绍一下HQL中使用Join fetching,在介绍这个之前,我们先看另一种情况,就是:在配置文件中设置fetch=“join”,然后在测试方法中不用load,用HQL替换load,测试方法的代码如下:
@Test
public void testFetchLoad() {
Session session = HibernateUtil.oepnSession();
session.beginTransaction();
Student stu = (Student) session.createQuery("from Student stu where stu.id = 1")
.uniqueResult();
System.out.println(stu.getName() + "," + stu.getCla().getName());
}
显示没有达到我们预想中的效果,也就是说如果使用HQL查询对象,那么在配置文件中声明fetch=“join”是无法实现连接抓取的,所以接下来就介绍一下如何在HQL中进行连接抓取。其实很简单,在HQL中这样写:
@Test
public void testFetchLoad() {
Session session = HibernateUtil.oepnSession();
session.beginTransaction();
Student stu = (Student) session
.createQuery(
"from Student stu left outer join fetch stu.cla where stu.id=1")
.uniqueResult();
System.out.println(stu.getName() + "," + stu.getCla().getName());
}我们可以通过join fetch关键字来抓取指定的关联对象,这样就实现了在HQL中进行连接抓取,运行一下可以看到:

还是通过一条left outer join自动关联查询了学生和班级,这就是抓取策略中的Join fetching。但是Join fetching本身也存在一定的问题,就是如果我们不需要查询关联对象,那么他也会发一个outer join的SQL语句,尽管HQL我们可以控制,但是如果通过O/M映射文件配置的fetch=“join”的话这样是无法控制的。所以说一般情况下能用HQL进行连接抓取的话尽量用HQL去做,基于配置文件毕竟不如HQL灵活。
由于子查询抓取(Subselect fetching)是用来抓取集合的,我们这里没有用到双向关联,所以暂且不做相关介绍,最后看一下关于批量抓取(Batch fetching)的应用。
批量抓取顾名思义就是一次性抓取一批数据,在上面的例子中我们都是通过加载一个对象来举例说明的,接下来为数据库继续添加少量数据:


现在再通过最简单的HQL来查询一下学生表的所有数据并输出:
@Test
public void testFetch02() {
Session session = HibernateUtil.oepnSession();
session.beginTransaction();
List list = session.createQuery("from Student stu").list();
for (Student stu : list) {
System.out.println(stu.getName() + "," + stu.getCla().getName());
}
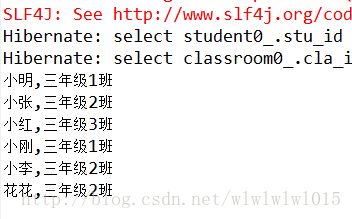
} 运行之后可以看到:

一共发了4条SQL语句,第一条查询学生,后三条查询班级,我们一共有3条班级数据,也就是说Hibernate会为每一个班级发1条SQL去查询班级信息,当班级表的数据量很大时,这样就会发大量的SQL显示会降低性能,在这里我们就可以用Batch fetching去优化。很简单,我们在Classroom.hbm.xml的配置文件中的
这样就指定了我们一次查询会批量抓取3条classroom的数据,也就不用为每个班级都发一条SQL语句了,而是会通过一条SQL一次性的查出3个班级。
其他地方的代码都不用改,再次运行上面的Test方法可以看到:
可以看到当我们指定了batch-size=3,那么就通过1条SQL完成了3个班级的查询,这就是批量抓取。当然批量抓取也存在弊端,就是当数据量较大时,如果批量抓取过多的数据,也会影响性能的,因为抓取的数据会存在内存中,所以大多数情况下还是会使用基于HQL的Join fetching来替代它。
三、基于Annotation的抓取配置
基于Annotation的抓取配置和基于O/R映射文件的抓取配置略有不同,但基于HQL方面的配置都是一样的,这里就不详细举例说明了,仅仅简单的提一下需要注意的一些关键点:
1.xml中的fetch=“select/join”相当于annotation中的fetch = FetchType.LAZY/FetchType.EAGER,xml默认的是select抓取,而基于Annotation默认的是EAGER,也就是join抓取了。
2.批量抓取的设置中,xml是在需要批量抓取的对象的hbm文件中的class根标签中去指定batch-size=?,而基于annotation是在需要批量抓取的对象的类中指定@BatchSize(size=?),这个注解一般写在@Table或@Entity下面即可。
3.能用HQL的方式进行抓取尽量用HQL,因为这样可以无视xml或annotation各自的个性化配置。
四、总结
本篇blog记录了一下Hibernate抓取策略最简单最常用的一些基本操作,由于我个人用的也不是很好所以有些地方说的不一定准备,如果发现错误的地方或者更好的建议欢迎各位提出,只有不断改正才能不断的提高,关于Hibernate,我认为只要能用好效率依旧很不错,尽管比不上精心设计的JDBC,不过和其它的持久层框架相比也不会落后。本系列blog会继续记录关于Hibernate的优化技术,下一篇应该是缓存相关的,本篇就到这里,继续去看文档了~~