Spring Boot篇
第一章 SpringBoot篇
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
Spring + Boot 整合所有框架,通过一行简单的Main方法来启动。
1.1 RESTful
一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
REST(英文:Representational State Transfer,简称REST)描述了一个架构样式的网络系统,比如 web 应用程序。它首次出现在 2000 年 Roy Fielding 的博士论文中,Roy Fielding是 HTTP 规范的主要编写者之一。在目前主流的三种Web服务交互方案中,REST相比于SOAP(Simple Object Access protocol,简单对象访问协议)以及XML-RPC更加简单明了,无论是对URL的处理还是对Payload的编码,REST都倾向于用更加简单轻量的方法设计和实现。值得注意的是REST并没有一个明确的标准,而更像是一种设计的风格。
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
1.2 IDEA快捷键
Alt +1 Project(前面有数字1)
Alt+2 Favorites(前面有数字2)(可以看到打的断点和你做的标记)
Ctrl+Shift+R Enter File Name
Ctrl+Shift+U 大小写转换
Ctrl+T 到方法的实现里去
Ctrl+Q 返回上次编辑处
Ctrl+Alt+[ 开两个项目窗口时可切换到上一个项目窗口
Ctrl+Alt+] 开两个项目窗口时可切换到下一个项目窗口
Ctrl+Shift+A 搜索action(在该界面按alt+上箭头可查看搜索历史
Ctrl+E 最近打开的文件
Ctrl+Shift+E 最近更改的文件
ESC 退出
Ctrl+Alt+左右箭头 跳转到历史光标所在处
Ctrl+Shift+Alt+F11 打标记的(1,2,3)(按Ctrl+1转到标记1处)
Shift+F11 显示标记
Alt+Shift+F Add to Favorite
Plugin 安装插件的
Alt+1 (ESC) 跳转到Project区域和代码区
Ctrl+Shift+T 查找Class
Navigate ~Symbol 查找函数
Ctrl+H 精准搜索
Alt+F2 调用浏览器
Ctrl+Shift+右箭头 选中字符串里的所有字符
Ctrl+Alt+Y 选中所有的该字符
Ctrl+Alt+L 代码格式化
100.fori for循环
name.field 给name一个定义
a.return return a;
str.nn if (str != null)
Alt + Shift + R rename
两个文件一起选中按Ctrl+D 比较两个文件
double Shift search for everything
Ctrl+F4 关闭当前文件
Ctrl+Alter+space 提示
Alt+/ 提示
Alt+Enter 提示改错
Ctrl+Shift+C 复制文件路径
1.3 JAVA基础复习
1.3.1 注解类
定义public @interface Test{
public String add();
}
1.3.2 注解
1.3.2.1 @Target
示例:@Target(ElementType.METHOD)
@Target说明了Annotation所修饰的对象范围:Annotation可被用于 packages、types(类、接口、枚举、Annotation类型)、类型成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch参数)。在Annotation类型的声明中使用了target可更加明晰其修饰的目标。
作用:用于描述注解的使用范围(即:被描述的注解可以用在什么地方)
取值(ElementType)有:
1.CONSTRUCTOR:用于描述构造器
2.FIELD:用于描述域
3.LOCAL_VARIABLE:用于描述局部变量
4.METHOD:用于描述方法
5.PACKAGE:用于描述包
6.PARAMETER:用于描述参数
7.TYPE:用于描述类、接口(包括注解类型) 或enum声明
1.3.2.2 @Retention
示例:@Retention(RetentionPolicy.RUNTIME)
1、RetentionPolicy.SOURCE:注解只保留在源文件,当Java文件编译成class文件的时候,注解被遗弃;
2、RetentionPolicy.CLASS:注解被保留到class文件,但jvm加载class文件时候被遗弃,这是默认的生命周期;
3、RetentionPolicy.RUNTIME:注解不仅被保存到class文件中,jvm加载class文件之后,仍然存在;
1.3.2.3 @Documented
示例:@Documented
Documented 注解表明这个注解应该被 javadoc工具记录. 默认情况下,javadoc是不包括注解的. 但如果声明注解时指定了 @Documented,则它会被 javadoc 之类的工具处理, 所以注解类型信息也会被包括在生成的文档中.
1.3.2.4 @JSONField
示例:
@JSONField(name = “name”) // 注意观察生成的JSON串中name和age的区别 private String name;
@JSONField(name = “AGE”)
private String age;
@JSONField(name=“new_password”, serialize=false, deserialize=false)
private String password;
翻看源码可以看到serialize、deserialize的默认值都是true,也就是说默认情况下(即使不设置serialize、deserialize属性)是允许对象序列化和反序列化的。
@JSONField注解可以用在方法(method),属性(field)以及方法中的参数(parameter)上。JSONField中的name属性用来指定JSON串中key的名称。
@Null 被注释的元素必须为null
@NotNull 被注释的元素不能为null
@AssertTrue 被注释的元素必须为true
@AssertFalse 被注释的元素必须为false
@Min(value) 被注释的元素必须是一个数字,其值必须大于等于指定的最小值
@Max(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值
@DecimalMin(value) 被注释的元素必须是一个数字,其值必须大于等于指定的最小值
@DecimalMax(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值
@Size(max,min) 被注释的元素的大小必须在指定的范围内。
@Digits(integer,fraction) 被注释的元素必须是一个数字,其值必须在可接受的范围内
@Past 被注释的元素必须是一个过去的日期
@Future 被注释的元素必须是一个将来的日期
@Pattern(value) 被注释的元素必须符合指定的正则表达式。
@Email 被注释的元素必须是电子邮件地址
@Length 被注释的字符串的大小必须在指定的范围内
@NotEmpty 被注释的字符串必须非空
@Range 被注释的元素必须在合适的范围内
1.3.2.5 @Pattern
@Pattern(regexp = “[a-fA-F0-9]{8}”, message = “seqId必须为8位16进制”)
@Pattern(regexp = “^ON|OFF$”, message = “netAccessRight只能设置为ON或OFF”)
1.3.2.6 @Component
今天在写程序的时候看见一个以前没有见过的注解(@Component),在网上查找过后,经过实践,决定把它记录下来。
1、@controller 控制器(注入服务)
用于标注控制层,相当于struts中的action层
2、@service 服务(注入dao)
用于标注服务层,主要用来进行业务的逻辑处理
3、@repository(实现dao访问)
用于标注数据访问层,也可以说用于标注数据访问组件,即DAO组件.
4、@component (把普通pojo实例化到spring容器中,相当于配置文件中的
)
泛指各种组件,就是说当我们的类不属于各种归类的时候(不属于@Controller、@Services等的时候),我们就可以使用@Component来标注这个类。
案例:
上面的这个例子是引入Component组件的例子,其中base-package表示为需要扫描的所有子包。
共同点:被@controller 、@service、@repository 、@component 注解的类,都会把这些类纳入进spring容器中进行管理
1.3.2.7 @Aspect
@Component//这个类可以被spring的bean容器识别
@Aspect//声明这是一个切面类
@Configuration
@EnableAspectJAutoProxy//自动使用AspectJ代理
1.@AspectJ切面使用@Aspect注解配置,拥有@Aspect的任何bean将被Spring自动识别并应用。
2.用@Aspect注解的类可以有方法和字段,他们也可能包括切入点(pointcut),通知(Advice)和引入(introduction)声明。
3.@Aspect注解是不能够通过类路径自动检测发现的,所以需要配合使用@Component注释或者在xml配置bean
pointcut
1.一个切入点通过一个普通的方法定义来提供,并且切入点表达式使用@Pointcut注解,方法返回类型必须为void。
2.定义一个名为’ anyOldTransfer ',这个切入点将匹配任何名为" transfer "的方法的执行。
@Pointcut(“execution(* transfer(…))”)
private void anyOldTransfer() {}
execution 匹配方法执行的连接点
within 限定匹配特定类型的连接点
this 匹配特定连接点的bean引用是指定类型的实例的限制
target 限定匹配特定连接点的目标对象是指定类型的实例
args 限定匹配特定连接点的参数是给定类型的实例
@target 限定匹配特定连接点的类执行对象的具有给定类型的注解
@args 限定匹配特定连接点的实际传入参数的类型具有给定类型的注解
@within 限定匹配到内具有给定的注释类型的连接点
@annotation 限定匹配特定连接点的的主体具有给定的注解
组合pointcut
1.切入点表达式可以通过&&、|| 和!进行组合,也可以通过名字引用切入点表达式。
2.通过组合,可以建立更加复杂的切入点表达式。
@Component
@Aspect
public class MoocAspect {
//以Biz结尾的任何类的类型方法都会匹配这个切入点
@Pointcut("execution(* com.zzspring.dao.*Biz.*(..)")
private void pointcut() {}
//当前包下的任何类型方法都会匹配到这个切入点
@Pointcut("within(* com.zzspring.dao.*)")
private void bizPointcut() {}
//取pointcut()和bizPointcut()的交集
@Pointcut("pointcut() && bizPointcut()")
private void trad() {}
}
1.定义良好的pointcuts
2.AspectJ是编译期的AOP。
3.检查代码并匹配连接点与切入点的代价是昂贵的。
4.一个好的切入点应该包括一下几点
①选择特定类型的连接点,入:execution,get,set,call,handler
②确定连接点范围 ,如:within,withincode
③匹配上下文信息,如:this,target,@annotation
a、目标类
@Repository
public class UserDaoImpl implements UserDao {
public void save() {
System.out.println("保存用户...");
}
public void delete() {
System.out.println("删除用户...");
}
}
b、通过一个 POJO使用 @AspectJ管理切面
/*
* 通过@Aspect把这个类标识管理一些切面
*/
@Aspect
@Component
public class FirstAspect {
/*
* 定义切点及增强类型
*/
@Before("execution(* save(..))")
public void before(){
System.out.println("我是前置增强...");
}
}
c、配置
配置的时候要引入aop命名空间及打开@AspectJ切面驱动器
d、测试
ApplicationContext context = new ClassPathXmlApplicationContext(new String[]{"applicationContext.xml"});
UserDao userDao = (UserDao) context.getBean("userDaoImpl");
userDao.save();
userDao.delete();
e、结果
我是前置增强…
保存用户…
删除用户…
@Before前置增强
@Component
@Aspect
public class DeviceInfoPointCut {
@Before("execution(* com.cmcc.dhome.device.service.device.IGatewayService.getGatewayList(..)) && args(passId,..)")
public void testAOPBefore(String passId) {
System.out.println("----------------------------"+"testAOPBefore");
}
@After("execution(* com.cmcc.dhome.device.service.device.IGatewayService.getGatewayList(..)) && args(passId,..)")
public void testAOPAfter(String passId) {
System.out.println("----------------------------"+"testAOPAfter");
}
@Before(value= “切入点表达式或命名切入点”,argNames = “指定命名切入点方法参数列表参数名字,可以有多个用“,”分隔”)
增强使用:@Before(value=“execution(*save(…))”)是缺省了value,直接键入值。
@AfterReturning后置增强
@AfterReturning(
value="切入点表达式或命名切入点",
pointcut="切入点表达式或命名切入点",
argNames="参数列表参数名",
returning="目标对象的返回值")
pointcut与value是一样的。如果使用pointcut来声明,那么前面声明的value就没用了。
1.3.2.8 @Data
@Data注解在类上时,简化java代码编写,为该类提供读写属性,还提供了equals(),hashCode(),toString()方法
1.3.2.9 @Configuration
从Spring3.0,@Configuration用于定义配置类,可替换xml配置文件,被注解的类内部包含有一个或多个被@Bean注解的方法,这些方法将会被AnnotationConfigApplicationContext或AnnotationConfigWebApplicationContext类进行扫描,并用于构建bean定义,初始化Spring容器。
注意@Configuration注解的配置类有如下要求:
1.@Configuration不可以是final类型;
2.@Configuration不可以是匿名类;
3.嵌套的configuration必须是静态类。
一、用@Configuration加载spring
1.1、@Configuration配置spring并启动spring容器
1.2、@Configuration启动容器+@Bean注册Bean
1.3、@Configuration启动容器+@Component注册Bean
1.4、使用 AnnotationConfigApplicationContext 注册 AppContext 类的两种方法
1.5、配置Web应用程序(web.xml中配置AnnotationConfigApplicationContext)
二、组合多个配置类
2.1、在@configuration中引入spring的xml配置文件
2.2、在@configuration中引入其它注解配置
2.3、@configuration嵌套(嵌套的Configuration必须是静态类)
三、@EnableXXX注解
四、@Profile逻辑组配置
五、使用外部变量
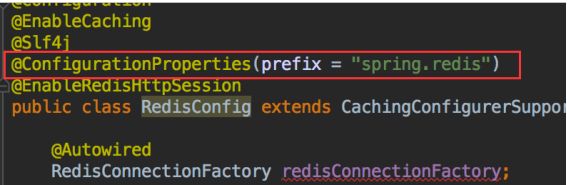
1.3.2.9 @ConfigurationProperties
自定义配置参数绑定:通过使用@ConfigurationProperties和@Component注解自定义参数配置类,之后程序启动时将自动加载application.properties配置文件中的对应的配置项;

1.3.2.10 @JsonProperty
jackson的maven依赖
com.fasterxml.jackson.core
jackson-databind
2.5.3
@JsonProperty 此注解用于属性上,作用是把该属性的名称序列化为另外一个名称,如把trueName属性序列化为name,@JsonProperty(“name”)。
@JsonProperty("name")
private String trueName;
1.3.2.11 @Range
@Range(min = 0, max = 1, message = “reqType只能设置为0或1”)
1.3.2.12 @Inherited
@Inherited 元注解是一个标记注解,@Inherited阐述了某个被标注的类型是被继承的。
如果一个使用了@Inherited修饰的annotation类型被用于一个class,则这个annotation将被用于该class的子类。
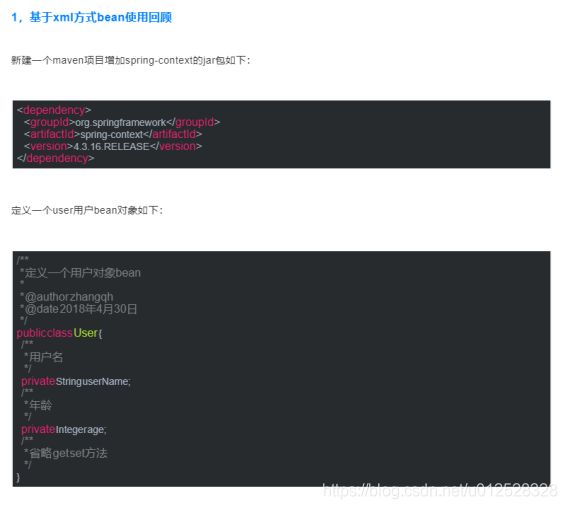
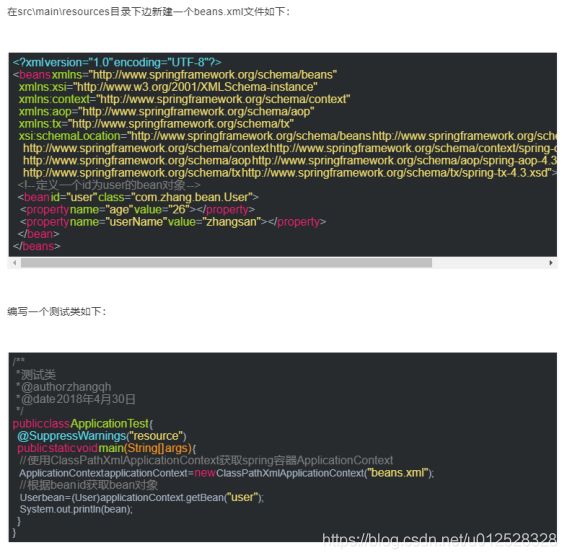
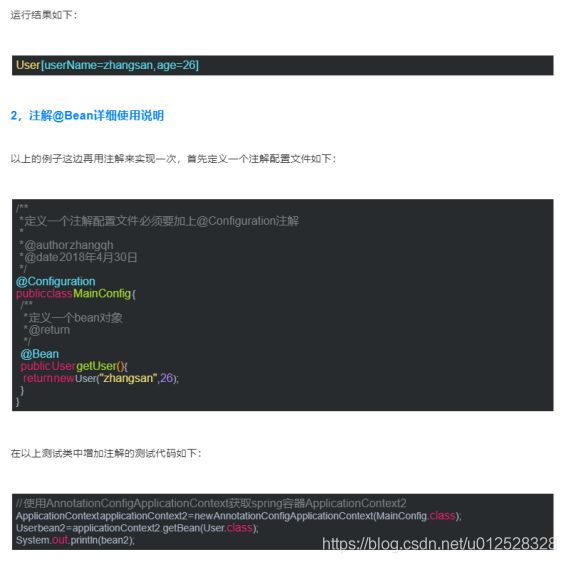
1.3.2.13 @Bean
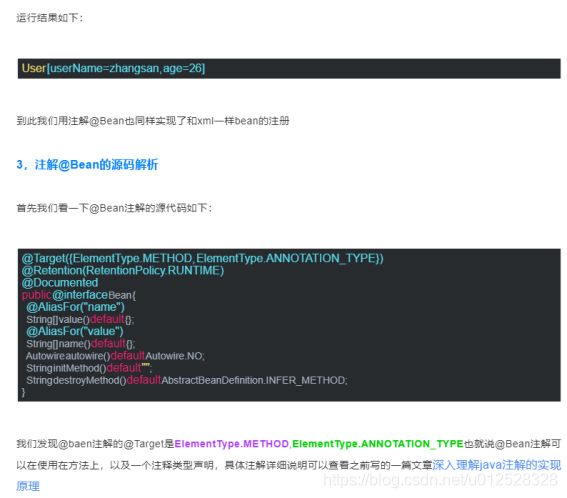
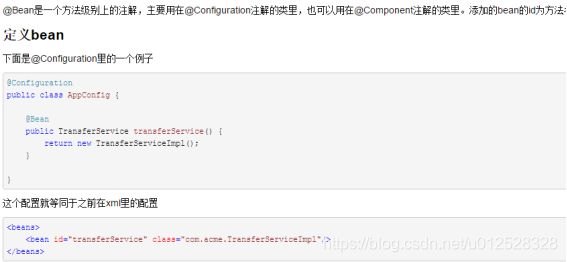
1.3.2.14 @EnableAsync
使用多线程,往往是创建Thread,或者是实现runnable接口,用到线程池的时候还需要创建Executors,spring中有十分优秀的支持,就是注解@EnableAsync就可以使用多线程,@Async加在线程任务的方法上(需要异步执行的任务),定义一个线程任务,通过spring提供的ThreadPoolTaskExecutor就可以使用线程池
1.3.2.15 @Primary
在spring 中使用注解,常使用@Autowired, 默认是根据类型Type来自动注入的。但有些特殊情况,对同一个接口,可能会有几种不同的实现类,而默认只会采取其中一种的情况下 @Primary 的作用就出来了
1.3.2.16 @value(“${}”)
从配置properties文件中读取init.password 的值。
@Value("${init.password}")
private String initPwd;
1.3.2.17 @Autowired

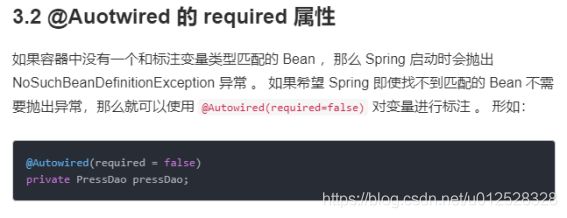
1.3.2.18 @Qualifier
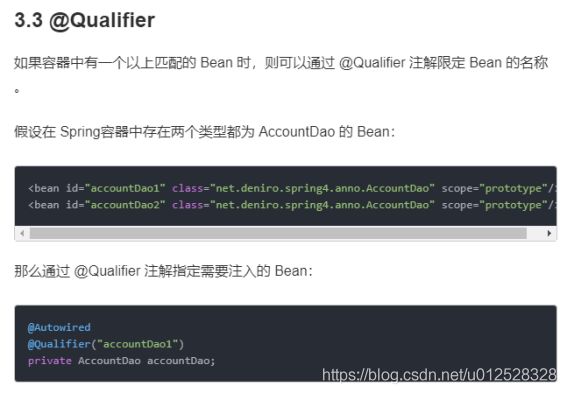
1.3.2.19 @Scope
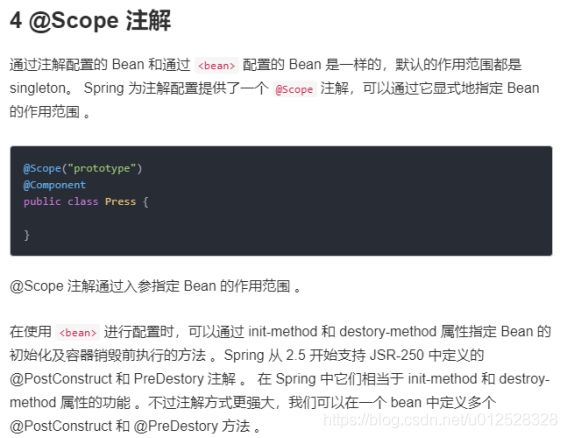
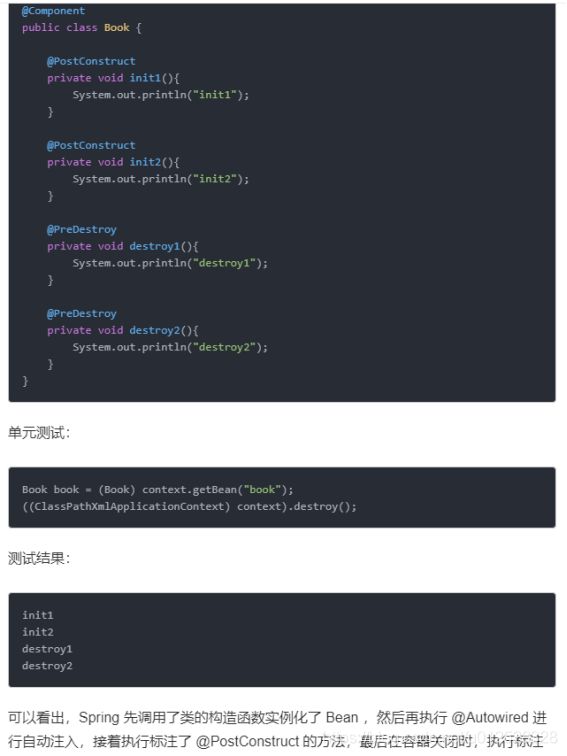
1.3.2.20 @FeignClient
JAVA 项目中接口调用怎么做 ?
1.Httpclient
2.Okhttp
3.Httpurlconnection
4.RestTemplate
上面是最常见的几种用法,我们今天要介绍的用法比上面的更简单,方便,它就是Feign
Feign是一个声明式的REST客户端,它的目的就是让REST调用更加简单。
Feign提供了HTTP请求的模板,通过编写简单的接口和插入注解,就可以定义好HTTP请求的参数、格式、地址等信息。
而Feign则会完全代理HTTP请求,我们只需要像调用方法一样调用它就可以完成服务请求及相关处理。
SpringCloud对Feign进行了封装,使其支持SpringMVC标准注解和HttpMessageConverters。
Feign可以与Eureka和Ribbon组合使用以支持负载均衡。
区别:
在预订微服务中,有一个同步呼叫票价(Fare)。RestTemplate是用来制作的同步呼叫。使用RestTemplate时,URL参数是以编程方式构造的,数据被发送到其他服务。在更复杂的情况下,我们将不得不RestTemplate深入到更低级别的API提供的甚至是API 的细节。
Feign是Spring Cloud Netflix库,用于在基于REST的服务调用上提供更高级别的抽象。Spring Cloud Feign在声明性原则上工作。使用Feign时,我们在客户端编写声明式REST服务接口,并使用这些接口来编写客户端程序。开发人员不用担心这个接口的实现。这将在运行时由Spring动态配置。通过这种声明性的方法,开发人员不需要深入了解由HTTP提供的HTTP级别API的细节的RestTemplate。
总结: 也就是说FeignClient简化了请求的编写,且通过动态负载进行选择要使用哪个服务进行消费,而这一切都由Spring动态配置实现,我们不用关心这些,只管使用方法即可。再说,就是简化了编写,RestTemplate还需要写上服务器IP这些信息等等,而FeignClient则不用。
不过话又再说回来,其实RestTemplate同样可以简化到使用FeignClient那样简单,无非就是自己封装多一层去实现而已,所以,我个人觉得没有太多绝对,只是看你的业务需求怎么定位这个选择而已。
FeignClient注解被@Target(ElementType.TYPE)修饰,表示FeignClient注解的作用目标在接口上
@FeignClient(name = "github-client", url = "https://api.github.com", configuration = GitHubExampleConfig.class)
public interface GitHubClient {
@RequestMapping(value = "/search/repositories", method = RequestMethod.GET)
String searchRepo(@RequestParam("q") String queryStr);
}
声明接口之后,在代码中通过@Resource注入之后即可使用。@FeignClient标签的常用属性如下:
1.name:指定FeignClient的名称,如果项目使用了Ribbon,name属性会作为微服务的名称,用于服务发现
2.url: url一般用于调试,可以手动指定@FeignClient调用的地址
3.decode404:当发生http 404错误时,如果该字段位true,会调用decoder进行解码,否则抛出FeignException
4.configuration: Feign配置类,可以自定义Feign的Encoder、Decoder、LogLevel、Contract
5.fallback: 定义容错的处理类,当调用远程接口失败或超时时,会调用对应接口的容错逻辑,fallback指定的类必须实现@FeignClient标记的接口
6.fallbackFactory: 工厂类,用于生成fallback类示例,通过这个属性我们可以实现每个接口通用的容错逻辑,减少重复的代码
7.path: 定义当前FeignClient的统一前缀
1.3.2.21 @GetMapping
Spring4.3中引进了{@GetMapping、@PostMapping、@PutMapping、@DeleteMapping、@PatchMapping},来帮助简化常用的HTTP方法的映射,并更好地表达被注解方法的语义。
以@GetMapping为例,Spring官方文档说:
@GetMapping是一个组合注解,是@RequestMapping(method = RequestMethod.GET)的缩写。该注解将HTTP Get 映射到 特定的处理方法上。
1.3.2.22 @Intercepts
@Intercepts({ @Signature(type = StatementHandler.class, method = “prepare”, args = { Connection.class, Integer.class }) })
public class PagePluginHigh implements Interceptor {
在mybatis执行SQL语句之前进行拦击处理
1.3.2.23 @PathVariable
@PathVariable是用来获得请求url中的动态参数的
注解绑定它传过来的值到方法的参数上
@RequestParam 和 @PathVariable 注解是用于从request中接收请求的,两个都可以接收参数,关键点不同的是@RequestParam 是从request里面拿取值,而 @PathVariable 是从一个URI模板里面来填充
@RequestParam
示例:
http://localhost:8080/springmvc/hello/101?param1=10¶m2=20
根据上面的这个URL,你可以用这样的方式来进行获取
public String getDetails(
@RequestParam(value="param1", required=true) String param1,
@RequestParam(value="param2", required=false) String param2){
...
}
1.3.2.23 @Valid
用于校验
1.3.2.24 @Param
简而言之,在DAO层的接口的方法里当参数只有一个的时候,用@Param,mapper.xml
文件用#{}和${}都可以得到传入的参数;不用@Param时,必须用#{}才能得到;当参数两个及以上时,不用@Param参数,那么#{}和${}都得不到传入的参数。
实例一 @Param注解单一属性
dao层示例:
Public User selectUser(@param(“userName”) String name,@param(“userpassword”) String password);
xml映射对应示例
注意:采用#{}的方式把@Param注解括号内的参数进行引用(括号内参数对应的是形参如 userName对应的是name);
实例二 @Param注解JavaBean对象
dao层示例
public List getUserInformation(@Param("user") User user);
xml映射对应示例
1,使用@Param注解
当以下面的方式进行写SQL语句时:
@Select("select column from table where userid = #{userid} ")
public int selectColumn(int userid);
当你使用了使用@Param注解来声明参数时,如果使用 #{} 或 ${} 的方式都可以。
@Select("select column from table where userid = ${userid} ")
public int selectColumn(@Param("userid") int userid);
当你不使用@Param注解来声明参数时,必须使用使用 #{}方式。如果使用 ${} 的方式,会报错。
@Select("select column from table where userid = ${userid} ")
public int selectColumn(@Param("userid") int userid);
2,不使用@Param注解
不使用@Param注解时,参数只能有一个,并且是Javabean。在SQL语句里可以引用JavaBean的属性,而且只能引用JavaBean的属性。
// 这里id是user的属性
@Select("SELECT * from Table where id = ${id}")
Enchashment selectUserById(User user);
1.3.2.24 @RequestMapping
@RequestMapping(value = “/{userId}/{did}/{source:.*}List”)
1.3.2.25 @Resource
@Resource装配顺序:
①如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
②如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
③如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常。
④如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
@Resource的作用相当于@Autowired,只不过@Autowired按照byType自动注入。
1.3.2.26 @Cacheable
1.@Cacheable:触发缓存写入。
2.@CacheEvict:触发缓存清除。
3.@CachePut:更新缓存(不会影响到方法的运行)。
4.@Caching:重新组合要应用于方法的多个缓存操作。
5.@CacheConfig:设置类级别上共享的一些常见缓存设置。
1.3.3 常用正则表达式
下面是常用的正则表达式:
1 匹配首尾空格的正则表达式:(^\s*)|(\s*$)
2 整数或者小数:^[0-9]+.{0,1}[0-9]{0,2}$
3 只能输入数字:"^[0-9]*$"。
4 只能输入n位的数字:"^\d{n}$"。
5 只能输入至少n位的数字:"^\d{n,}$"。
6 只能输入m~n位的数字:。"^\d{m,n}$"
7 只能输入零和非零开头的数字:"^(0|[1-9][0-9])$"。
8 只能输入有两位小数的正实数:"^[0-9]+(.[0-9]{2})?$"。
9 只能输入有1~3位小数的正实数:"^[0-9]+(.[0-9]{1,3})?$"。
10 只能输入非零的正整数:"^+?[1-9][0-9]$"。
11 只能输入非零的负整数:"^-[1-9][]0-9"*$。
12 只能输入长度为3的字符:"^.{3}$"。
13 只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。
14 只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。
15 只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。
16 只能输入由数字和26个英文字母组成的字符串:"^[A-Za-z0-9]+$"。
17 只能输入由数字、26个英文字母或者下划线组成的字符串:"^\w+$"。
18 验证用户密码:"^[a-zA-Z]\w{5,17}$“正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。
19 验证是否含有^%&’,;=?$“等字符:”[^%&’,;=?$\x22]+”。
20 只能输入汉字:"^[\u4e00-\u9fa5]{0,}$"
21 验证Email地址:"^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)$"。
22 验证InternetURL:"^http://([\w-]+.)+[\w-]+(/[\w-./?%&=])?$"。
23 验证电话号码:"^((\d{3,4}-)|\d{3.4}-)?\d{7,8}$“正确格式为:“XXX-XXXXXXX”、“XXXX-XXXXXXXX”、“XXX-XXXXXXX”、“XXX-XXXXXXXX”、“XXXXXXX"和"XXXXXXXX”。
24 验证身份证号(15位或18位数字):”^\d{15}|\d{18}$"。
25 验证一年的12个月:"^(0?[1-9]|1[0-2])$“正确格式为:“01"~"09"和"1"~"12”。
26 验证一个月的31天:”^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;“01"~"09"和"1"~"31”。
27 匹配中文字符的正则表达式: [\u4e00-\u9fa5]
28 匹配双字节字符(包括汉字在内):[^\x00-\xff]
29 应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
30 String.prototype.len=function(){return this.replace(/[^\x00-\xff]/g,“aa”).length;}
31 匹配空行的正则表达式:\n[\s| ]\r
32 匹配html标签的正则表达式:<(.)>(.))>|<(.*)/>
1.3.4 注解与XML配置的区别
注解:是一种分散式的元数据,与源代码耦合。
xml :是一种集中式的元数据,与源代码解耦。
因此注解和XML的选择上可以从两个角度来看:分散还是集中,源代码耦合/解耦。
注解的缺点:
1、很多朋友比如在使用spring注解时,会发现注解分散到很多类中,不好管理和维护;
2、注解的开启/关闭必须修改源代码,因为注解是源代码绑定的,如果要修改,需要改源码,有这个问题,所以如果是这种情况,还是使用XML配置方式;比如数据源;
3、注解还一个缺点就是灵活性,比如在之前翻译的Spring Framework 4.0 M1: WebSocket
支持;在实现复杂的逻辑上,没有XML来的更加强大;注解就是要么用,要么不用;
4、通用配置还是走XML吧,比如事务配置,比如数据库连接池等等,即通用的配置集中化,而不是分散化,如很多人使用@Transactional来配置事务,在很多情况下这是一种太分散化的配置;
5、XML方式比注解的可扩展性和复杂性维护上好的多,比如需要哪些组件,不需要哪些;在面对这种情况,注解扫描机制比较逊色,因为规则很难去写或根本不可能写出来;
注解的好处:
1、XML配置起来有时候冗长,此时注解可能是更好的选择,如jpa的实体映射;注解在处理一些不变的元数据时有时候比XML方便的多,比如spring声明式事务管理,如果用xml写的代码会多的多;
2、注解最大的好处就是简化了XML配置;其实大部分注解一定确定后很少会改变,所以在一些中小项目中使用注解反而提供了开发效率,所以没必要一头走到黑;
3、注解相对于XML的另一个好处是类型安全的,XML只能在运行期才能发现问题。
PO(persistant object) 持久对象
在 o/r 映射的时候出现的概念,如果没有 o/r 映射,就没有这个概念存在了。通常对应数据模型 ( 数据库 ), 本身还有部分业务逻辑的处理。可以看成是与数据库中的表相映射的 java 对象。最简单的 PO 就是对应数据库中某个表中的一条记录,多个记录可以用 PO 的集合。 PO 中应该不包含任何对数据库的操作。
1.3.5 DO、PO、DO、TO、DTO、POJO、BO、DAO、VO对象
DO(Domain Object)领域对象
就是从现实世界中抽象出来的有形或无形的业务实体。一般和数据中的表结构对应。
TO(Transfer Object) ,数据传输对象
在应用程序不同 tie( 关系 ) 之间传输的对象
DTO(Data Transfer Object)数据传输对象
这个概念来源于J2EE的设计模式,原来的目的是为了EJB的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负载,但在这里,我泛指用于展示层与服务层之间的数据传输对象。
VO(view object) 值对象
视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
BO(business object) 业务对象
从业务模型的角度看 , 见 UML 元件领域模型中的领域对象。封装业务逻辑的 java 对象 , 通过调用 DAO 方法 , 结合 PO,VO 进行业务操作。 business object: 业务对象 主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。 比如一个简历,有教育经历、工作经历、社会关系等等。 我们可以把教育经历对应一个 PO ,工作经历对应一个 PO ,社会关系对应一个 PO 。 建立一个对应简历的 BO 对象处理简历,每个 BO 包含这些 PO 。 这样处理业务逻辑时,我们就可以针对 BO 去处理。
POJO(plain ordinary java object) 简单无规则 java 对象
纯的传统意义的 java 对象。就是说在一些 Object/Relation Mapping 工具中,能够做到维护数据库表记录的 persisent object 完全是一个符合 Java Bean 规范的纯 Java 对象,没有增加别的属性和方法。我的理解就是最基本的 Java Bean ,只有属性字段及 setter 和 getter 方法!。
DAO(data access object) 数据访问对象
是一个 sun 的一个标准 j2ee 设计模式, 这个模式中有个接口就是 DAO ,它负持久层的操作。为业务层提供接口。此对象用于访问数据库。通常和 PO 结合使用, DAO 中包含了各种数据库的操作方法。通过它的方法 , 结合 PO 对数据库进行相关的操作。夹在业务逻辑与数据库资源中间。配合 VO, 提供数据库的 CRUD 操作
1.3.6 枚举举例
public enum CodeType {
SUCCESS("1000000", "成功"),
ERROR("5000001", "系统错误"),
PLUGIN_NOT_INSTALLED("2202022", "用户未安装该插件");
private final String code;
private final String desc;
/**
* 构造函数.
* @param code
* code
* @param desc
* message
*/
CodeType(String code, String desc) {
this.code = code;
this.desc = desc;
}
public String getCode() {
return code;
}
public String getDesc() {
return desc;
}
}
1.3.7 小知识
数据库模糊查询
LIKE CONCAT(’%’,#{name},’%’)
JSON字符串转换成对象
需要有默认构造器 因为这是通过反射创建的 反射是先通过默认构造器创建对象的
打包成jar包和war包的插件
用lifecycle里的install生成jar包(先clean一下,再install)
org.springframework.boot
spring-boot-maven-plugin
${spring-boot.version}
repackage
org.apache.maven.plugins
maven-war-plugin
2.4
false
配置log日志输出
需要在这里加入 这是在dev环境下的
filter可以过滤,只保留debug
DEBUG
ACCEPT
DENY
完整配置
${log.bussiness-dir}/${log.filename}-${IP}/warn.log
true
true
${log.pattern}
WARN
ACCEPT
DENY
${log.bussiness-dir}/warn/${log.filename}-${IP}.%d{yyyy-MM-dd}.%i.log
200MB
30
20GB
0
1024
1.3.8 一些概念
1.3.8.1 敏捷开发

1.3.8.2 Kibana
数据分析的可视化利器
阿里云Elastisearch集成了可视化工具Kibana,用户可以使用Kibana的开发工具便捷的查询和分析存储在Elastisearch中的数据。除了柱状图、线状图、饼图、环形图等经典可视化功能外,还拥有地理位置分析、数据图谱分析、时序数据分析等高级功能
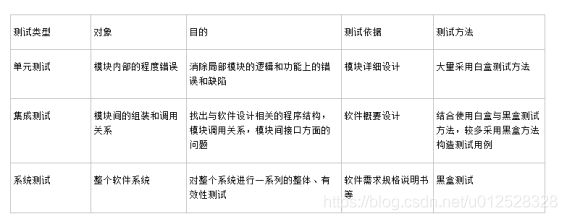
1.3.8.3 单元测试、集成测试、系统测试的区别
1.黑盒测试:已知产品的功能设计规格,可以进行测试证明每个实现了的功能是否符合要求。
2.白盒测试:已知产品的内部工作过程,可以通过测试证明每种内部操作是否符合设计规格要求,所有内部成分是否以经过检查。
软件的黑盒测试意味着测试要在软件的接口处进行。这种方法是把测试对象看做一个黑盒子,测试人员完全不考虑程序内部的逻辑结构和内部特性,只依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明。因此黑盒测试又叫功能测试或数据驱动测试。
软件的白盒测试是对软件的过程性细节做细致的检查。这种方法是把测试对象看做一个打开的盒子,它允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试。通过在不同点检查程序状态,确定实际状态是否与预期的状态一致。因此白盒测试又称为结构测试或逻辑驱动测试。
1.3.8.4 Vue框架
这里我们就说一下vue,vue是一款有好的、多用途且高性能的JavaScript框架,它能够帮助你创建可维护性和课测试性更强的代码库,vue是渐进式的JavaScript框架,也就是说如果你已经有一个现成的服务端应用你可以将vue作为该应用的一部分嵌入其中,带来更加丰富的交互体验或者如果你希望将更多的业务逻辑放到前端来实现那么vue的核心库机器生态系统也可以满足你的各式需求。
与其他框架相同,vue允许你讲一个网页分割成可复用的组件,每个组件都包含属于自己的HTML、CSS、JavaScript以用来渲染网页中相应的地方。
Vue框架诞生于2014年,其作者为中国人——尤雨溪,也是新人最容易入手的框架之一,不同于React和Angular,其中文文档也便于大家阅读和学习。Vue用于构建交互式的Web界面的库,是一个构建数据驱动的Web界面渐进式框架,该框架遵循CMD规范,并且提供的设计模式为MVVM模式(Model->View->View-Model)和一个可组合的组合型组件系统,具有简单的、灵活的API(接口)。该框架继承了React的虚拟DOM技术和Angular的双向数据绑定技术,是一款较新的功能性框架。
1.3.8.5 IANA
IANA是INTERNET域名系统的最高权威机构,掌握着INTERNET域名系统的设计、维护及地址资源分配等方面的绝对权力。在IANA之下另有3个分支机构,分别负责欧洲、亚太地区、美国与其他地区的IP地址资源分配与管理。
1.3.8.6 2.4G和5G wifi的区别
2.4G是一种无线技术,由于其频段处于2.400GHz~2.4835GHz之间,所以简称2.4G无线技术。2.4G WiFi是指基于IEEE 802.11b的技术标准,而IEEE 802.11b基于2.4G Hz的频段的IEEE802.11系列标准的产品。5G WiFi则是指基于IEEE 802.11ac标准开发的无线技术,因为IEEE 802.11ac技术本身工作在5G Hz频段,因而又叫5G
WiFi。
2.4GWIFI优点:信号较5GWIFI好,2.4Gwifi工作在2.4G频段,根据电磁波的物理特性波长越长衰减越少,2.4GWIFI的频率低波长长,所以信号穿过障碍物时衰减相对较少进而能传播的距离更远。2.4GWIFI缺点:2.4G信号频宽较窄,家电、无线设备大多使用2.4G频段,无线环境更加拥挤,干扰较大。
5GWIFI优点:5G信号频宽较宽,无线环境比较干净,干扰少,网速稳定,且5G可以支持更高的无线速率;5GWIFI缺点:5G信号频率较高,在空气或障碍物中传播时衰减较大,覆盖距离一般比2.4G信号小。
1.3.9 单元测试
junit3中setUp在每个测试方法之前执行,做通用初始化
tearDown在每个测试方法之后都会执行,做通用资源释放
junit4中用注解@Before和@After
@RunWith(SpringRunner.class)
@SpringBootTest(classes=App.class)
依赖:
org.springframework.boot
spring-boot-starter-test
test
junit
junit
4.12
test
org.springframework
spring-test
5.0.7.RELEASE
EasyMock
@Before
public void getById() {
getPeopleByIdDAO = EasyMock.createMock(GetPeopleByIdDAO2.class);
PeopleBO peopleBO = new PeopleBO();
peopleBO.setId(3L);
peopleBO.setName("hangyan");
System.out.println(peopleBO.getName());
EasyMock.expect(getPeopleByIdDAO.getById(1L)).andReturn(peopleBO);
EasyMock.replay(getPeopleByIdDAO);//重放Mock对象,测试时以录制的对象预期行为代替真实对象的行为
}
@Test
public void test(){
System.out.println("-----------------------------------"+getPeopleByIdDAO.getById(1L).getName());
}
任意一个T对象
EasyMock.isA(T.class);
Jmock:
@InjectMocks
private GetPeopleByIdController controller;
@Mock
private GetNameByIdService getNameByIdService;
@Mock
protected MockHttpServletRequest request;
private MockMvc mockMvc;
PeopleBO peopleBO = new PeopleBO();
peopleBO.setId(4L);
peopleBO.setName("jiayou");
when(getNameByIdService.getPeopleById(anyInt())).thenReturn(peopleBO);
1.3.10 jar包部署linux
sh device-api.sh start/stop/restart
1.3.11 jar包部署windows
java "-d64 -server -Xms1024m -Xms1024m -Xmn512m -Xss1024k -XX:SurvivorRatio=8 -XX:MetaspaceSize=80m -XX:MaxMetaspaceSize=120m -XX:+TieredCompilation -XX:+UseG1GC -XX:MaxGCPauseMillis=200" -jar device-api.jar --spring.config.location=file:"C:/Users/zhangqianghy/Desktop/application.yml"
1.3.12 FastDFS
FastDFS比七牛云等云端存储会便宜一些。
FastDFS是开源的轻量级分布式文件存储系统。它解决了大数据量存储和负载均衡等问题。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。
优势:
1.只能通过专用的API访问,不支持posix,降低了系统的复杂度,处理效率高
2.支持在线扩容,增强系统的可扩展性
3.支持软RAID,增强系统的并发处理能力及数据容错能力。Storage是按照分组来存储文件,同组内的服务器上存储相同的文件,不同组存储不同的文件。Storage-server之间不会互相通信。
4.主备Tracker,增强系统的可用性。
5.支持主从文件,支持自定义扩展名。
6.文件存储不分块,上传的文件和os文件系统中的文件一一对应。
7.相同内容的文件只存储一份,节约磁盘存储空间。对于上传相同的文件会使用散列方式处理文件内容,假如是一致就不会存储后上传的文件,只是把原来上传的文件在Storage中存储的id和URL返回给客户端。
1.3.13 客户端心跳机制
心跳机制简介
心跳是在TCP长连接中,客户端与服务端之间定期发送的一种特殊的数据包,通知对方在线以确保TCP连接的有效性。
如何实现心跳机制
有两种方式实现心跳机制:
1.使用TCP协议层面的 keepalive 机制
2.在应用层上自定义的心跳机制
TCP层面的 keepalive 机制我们在之前构建 Netty服务端和客户端启动过程中也有定义,我们需要手动开启,示例如下:
// 设置TCP的长连接,默认的 keepalive的心跳时间是两个小时
childOption(ChannelOption.SO_KEEPALIVE, true)
除了开启 TCP协议的 keepalive 之外,在我研究了github的一些开源Demo发现,人们往往也会自定义自己的心跳机制,定义心跳数据包。而Netty也提供了 IdleStateHandler 来实现心跳机制
Netty 实现心跳机制
下面来看看客户端如何实现心跳机制:
@Slf4jpublic class HeartbeatHandler extends ChannelInboundHandlerAdapter {
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
IdleStateEvent idleStateEvent = (IdleStateEvent) evt;
if (idleStateEvent.state() == IdleState.WRITER_IDLE) {
log.info("已经10s没有发送消息给服务端");
//向服务端送心跳包
//这里使用 protobuf定义的消息格式
MessageBase.Message heartbeat = new MessageBase.Message().toBuilder().setCmd(MessageBase.Message.CommandType.HEARTBEAT_REQUEST)
.setRequestId(UUID.randomUUID().toString())
.setContent("heartbeat").build();
//发送心跳消息,并在发送失败时关闭该连接
ctx.writeAndFlush(heartbeat).addListener(ChannelFutureListener.CLOSE_ON_FAILURE);
}
} else {
super.userEventTriggered(ctx, evt);
}
}
}
我们这里创建了一个ChannelHandler类并重写了userEventTriggered方法,在该方法里实现发送心跳数据包的逻辑,同时将 IdleStateEvent类加入逻辑处理链上。
实际上是当连接空闲时间太长时,将会触发一个 IdleStateEvent事件,然后我们调用 userEventTriggered来处理该 IdleStateEvent事件。
当启动客户端和服务端之后,控制台打印心跳消息如下:
2018-10-28 16:30:46.825 INFO 42648 — [ntLoopGroup-2-1]
c.pjmike.server.client.HeartbeatHandler : 已经10s没有发送消息给服务端 2018-10-28
16:30:47.176 INFO 42648 — [ntLoopGroup-4-1]
c.p.server.server.NettyServerHandler : 收到客户端发来的心跳消息:requestId:
“80723780-2ce0-4b43-ad3a-53060a6e81ab” cmd: HEARTBEAT_REQUEST content:
“heartbeat”
上面我们只讨论了客户端发送心跳消息给服务端,那么服务端还需要发心跳消息给客户端吗?
一般情况是,对于长连接而言,一种方案是两边都发送心跳消息,另一种是服务端作为被动接收一方,如果一段时间内服务端没有收到心跳包那么就直接断开连接。
我们这里采用第二种方案,只需要客户端发送心跳消息,然后服务端被动接收,然后设置一段时间,在这段时间内如果服务端没有收到任何消息,那么就主动断开连接,这也就是后面要说的 空闲检测