【论文笔记】Fast Image Processing with Fully-Convolutional Networks

摘要
这篇论文提出了一种可以加快各种图像处理算子的方法,该方法使用的是全卷积网络,这个全卷积网络通过输入-输出对进行训练(这个输入输出对有限制:demonstrate the action of the operator,不知道怎么翻译,后面有解释),训练后不需要运行之前的算子。经过训练的网络以全分辨率方式运行一段固定的时间。通过研究网络架构对近似准确率、运行时间和内存占用的影响,最终在平衡这些因素后获得一个特定架构。论文还评估了十种先进图像处理算子的方法,包括多变量模型、多尺度色调和细节操作、摄影风格转换、非局部去雾和非照片样式化(nonlocal dehazing, and nonphotorealistic stylization.)。实验证明论文用的方法比其他方法都要好。在MIT-Adobe数据集上,与之前最准确的先验近似方案相比,它通过评估算子的PSNR测得的近似准确率提高了8.5 dB(从27.5到36 dB),并以乘法因子3减少DSSIM,而且速度还是最快的。最后展示了模型在各种数据集和分辨率上的表现,并研究了所提出方法的一些扩展。
1.介绍
加快图像处理有一种通用的方法:先对图像进行下采样,以低分辨率执行算子,然后上采样。这种方法有两个明显的缺点:1.它仍然是在低分辨率图像上执行算子的,而有些算子即使是在低分辨率上也很慢,并且也不能以交互速率来执行;2.由于算子没有在原始分辨率上执行,所以图像的高频内容可能无法正确建模。这些都限制了近似准确率。
这篇论文研究了一种加速图像处理算子的替代方法。与下采样-评估-上采样方法相似,所提出的方法近似于原始算子。但下采样方法部分有所不同,该方法在全分辨率图像上操作,端对端训练以最大化准确度。使用一个卷积网络,该网络在输入 - 输出对上进行训练(这个输入输出对有限制:demonstrate the action of the operator,不知道怎么翻译,我自己理解的大概意思是这个输入输出对刚好是原来的算子处理的效果,也就是这个集的输入就是算子的输入,输出就是原算子处理之后的图像效果。就比如说原算子作用是加对比度,这个输入输出对就分别是原图和加对比度之后的图)。训练后就使用网络换掉之前的算子,根本不用运行这个算子。
根据三个对加速图像处理算子很重要的属性,来研究不同网络架构的影响:近似准确率、运行时间、紧凑性(compactness,理解为内存占用多少)。然后获得一个满足这三个标准的特定架构,它可以非常准确地近似于各种标准下的图像处理算子。还评估了十种先进图像处理算子的方法,包括多种形式的变分图像平滑,自适应细节增强,摄影风格转换和去雾。所有运算符都使用相同的架构进行近似,这个架构没有超参数调整。图1展示了五个训练过的近似器,对MIT-Adobe 5K测试图像进行操作之后的变化(训练过程不可见)。
对所有的算子来说,这种近似方法都比下采样方法要好。比如说MIT-Adobe测试集中,10个近似算子的PSNR为36 dB,而bilateral guided上采样的高准确率变量则为25 dB。同时,这种近似方法比使用最快变量的该方案还要快,它在恒定时间内运行,与原始算子的运行时间无关。
实验证明这种简单的方法很优秀,并且经过训练的近似器可以推广到不同的数据集,甚至是训练期间没有的图像分辨率。还研究了许多扩展,并表明所提出的方法可用于:1.创建参数化网络;2. 训练网络模拟许多不同的图像处理效果;3.处理视频。
2.相关工作
这部分就讲了一些关于加速图像处理算子的方法。比如什么双边滤波、中值滤波,变分方法、梯度域技术、大空间支持的卷积、局部拉普拉斯滤波器等等。但是都不具有一般性。
然后介绍了关于加速图像处理的其他工作,如系统基础结构和编程语言。
然后就介绍了其他人的方法与作者的比较,其他方法要么准确度、运行效率不够高,要么需要额外的操作,要么需要人工提取输入特征。作者用的深度网络方法,在关键技术决策方面和其他方法有所不同,从而导致范围更广,性能更好,端对端。
3.方法
3.1初步措施
I是一张RGB图像,f是转换图像内容但不改变维度的一个算子,也就是说I和f(I)分辨率一样。使用各种算法技术的算子f,目的是用另一个算子 f ^ \hat{f} f^来近似f,使得对于所有图像有 f ^ ( I ) ≈ f ( I ) \hat{f}(I)\approx f(I) f^(I)≈f(I)。I的分辨率不受限制,假设算子f及其近似值 f ^ \hat{f} f^都在可变分辨率图像上操作。此外,还要求算子 f i {f_i} fi与相应近似值 f i ^ \hat{f_i} fi^有着相同的参数化( parameterization):相同的参数集,相同的计算流。 近似值仅在参数(parameters)上有所不同,训练时这些参数适合每个算子。
前面说了基本方法是使用卷积网络来近似算子,网络必须在可变分辨率图像上运行,并且必须获得的输出图像分辨率与输入图像一样, 这被称为全预测(dense prediction)。原则上任何全卷积网络架构都可用于来近似算子, 任何已经用于像素分类问题的网络都可以用回归损失进行训练,但是并非所有的网络架构都会在这种情况下具有高准确率。
然后作者发现,当高级网络应用于低级图像处理问题时,它们通常表现得比之前专门为图像处理过程设计的方法要好。
3.2 Context aggregation networks
文里用的网络就是CAN。
然后就详细讲了参数化, { L 0 , . . . , L d } \lbrace L^0,...,L^d\rbrace {L0,...,Ld}表示层,第一层和最后一层 L 0 , L d L^0,L^d L0,Ld维数都是mxnx3,代表输入和输出图像。分辨率m×n是变化的,并不预先给出。
每一个中间层 L s ( 1 ≤ s ≤ d − 1 ) L^s(1\leq s\leq d-1) Ls(1≤s≤d−1)维数是mxnxw,w是每一层的宽度(通道数?),也就是特征向量的数量。中间层 L s L^s Ls是根据由前一层 L s − 1 L^{s-1} Ls−1的内容计算的,如下:
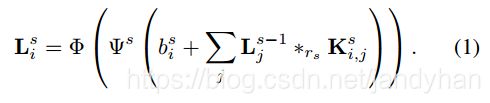
其中 L i s L_i^s Lis是 L s L^s Ls层的第i个特征层, L j s − 1 L_j^{s-1} Ljs−1是 L s − 1 L^{s-1} Ls−1层的第j个特征层, b i s b_i^s bis是偏移标量(scalar bias,也就是偏置项), K i , j s K^s_{i,j} Ki,js是一个3x3的卷积核,算子 ∗ r s *_{r_s} ∗rs是空洞卷积操作( L d − 1 L^{d-1} Ld−1层不用空洞卷积, L d L^d Ld层使用线性转换器), ψ s \psi^s ψs是自适应的归一化函数, ϕ \phi ϕ是像素级的非线性单元LReLU, ϕ ( x ) = m a x ( α x , x ) , α = 0.2 \phi(x)=max(\alpha x,x),\alpha =0.2 ϕ(x)=max(αx,x),α=0.2。添加链接描述
空洞卷积可以在不用pooling的情况下,做大增大感受野(pooling还会损失很多信息)。
3.3 自适应标准化
作者发现使用batch normalization可以提高一些图像处理算子(如样式传输和铅笔绘图)的近似准确率,但降低了其他图像处理算子的性能。因此,提出结合batch normalization和identity mapping的自适应标准化:

其中 λ s , μ s ∈ R \lambda_s,\mu_s\in R λs,μs∈R是学习的标量权重,BN是
批量标准化算子。权值 λ s , μ s \lambda_s,\mu_s λs,μs通过反向传播来学习。学习这些权重使得模型近似算子的特征,根据需要调整identity branch和batch normalization的强度。 添加链接描述
3.4 训练
网络在一组输入 - 输出对上训练,这个输入 - 输出对包含在使用原始算子之前和之后的图像: D = { I i , f ( I i ) } D=\lbrace I_i,f(I_i) \rbrace D={Ii,f(Ii)}。网络参数包括内核权重 κ = { K i , j s } s , i , j \kappa=\lbrace K_{i,j}^s\rbrace_{s,i,j} κ={Ki,js}s,i,j和偏差 B = { b i s } s , i B=\lbrace b_i^s \rbrace_{s,i} B={bis}s,i。这些参数经过优化,模拟算子 f 对训练集中所有图像的操作。定义图像空间回归损失为:

其中 N i N_i Ni是图像 I i I_i Ii的像素个数,这种损失最小化了训练集上RGB颜色空间中的均方误差(MSE)。虽然MSE与感知图像保真度的相关性有限,但之后实验会证明通过训练近似器来最小化MSE的方法,也会获得高精度的PSNR和SSIM等。
然后大概就是说其他损失函数没有MSE好。
给定一组高分辨率图像,每个都自动调整大小为320p和1440p之间的随机分辨率(例如,517p),同时保持其纵横比。训练使用Adam迭代500K次。
4.实验
实验模拟了十个图像操作:
- Rudin-Osher-Fatemi (图像复原模型)
- TV-L1 image restoration (图像复原模型)
- L0平滑
- relative total variation(提取图像结构?)
- 多尺度色调操作的图像增强
- 基于局部拉普拉斯滤波的多尺度细节操作
- 摄影风格转移
- 暗通道去雾
- 非局部去雾
- 铅笔画
数据集是MIT-Adobe 5K和RAISE。
然后和BGU-fast,BGU-opt以及其他论文中的方法都做了比较,也做了扩展实验等。
补充:
CAN24(d=9,w=24)时,卷积核大小都为3x3(除了最后一层),1-7层dilation值为:1,2,4,8,16,32,64;8-9层都为1,最后一层使用线性。
CAN32 (d=10,w=32)时,1-8dilation为:1,2,4,8,16,32,64,128;9-10都为1。
笔记:
看这篇由于各种原因时间线拉太长了,个人感觉看得不够深不够透彻。实验部分基本没看,整篇下来能想起来的收获只有空洞卷积。
讨论:(这些问题来源于网上)
1.解决了什么问题?
加速图像处理
2.提出了怎样的方法?
用一个全卷积网络模型去模拟图像操作
3为什么会提出这个方法?
之前的加速方法都是在低分辨率图像上进行,不够好
4.设计了怎样的模型?
CAN,空洞卷积,BN
5建立在什么样的假设上?
这个没注意,应该是训练测试集里的数据都是用原操作获得的?
6.这篇文章的关键点是什么?
应该在于空洞卷积,可以扩大感受野,并且也测试了使用均方误差来训练比较好;整篇的工作量很大
7.贡献是什么?
加速了图像处理操作过程
8.如何通过这个模型验证了作者所提出的观点?
实验
9.这个模型为什么能work?
因为训练集和测试集刚好就是模型想做到的操作,对于训练极为有利