mysql主从复制,基于gtid的主从复制
MySQL复制原理,其通过三个线程来完成,在master节点上运行的binlogdump线程以及在slave节点上运行的I/O线程和SQL线程。
1. master节点上的binlogdump线程,在slave与其正常连接的情况下,将binlog发送到slave上。
2.slave节点上的I/O线程,通过读取master节点发送的内容,并将数据复制到本地的relaylog中。
3.slave节点上的SQL线程,读取relaylog中的日志,并将其事务在本地执行。
binlog: binary log,主库中保存更新事件日志的二进制文件。
主从复制的基础是主库记录数据库的所有变更记录到binlog。binlog是数据库中保存配置中过期时间内所有修改数据库结构或内容的一个文件。如果过期时间是10d的话,那么就是最近10d的数据库修改记录。
mysql主从复制是一个异步的复制过程,主库发送更新事件到从库,从库读取更新记录,并执行更新记录,使得从库的内容与主库保持一致。在主库里,只要有更新事件出现,就会被依次地写入到binlog里面,是之后从库连接到主库时,从主库拉取过来进行复制操作的数据源

实验环境:server7:172.25.66.7(master)
server8:172.25.66.8(slave)
在server7中:
vim /etc/my.cnf 主节点必须启用二进制日志,记录任何修改数据库数据的事件

/etc/init.d/mysqld start
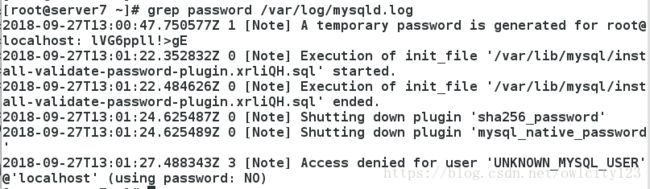
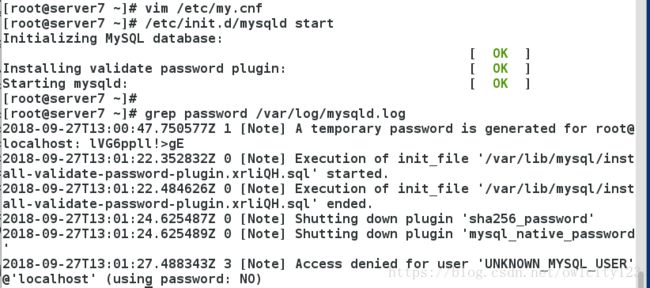
进行数据库初始化,第一次输入的密码为上面查看日志的临时密码,后面为root用户设置的密码要尽可能复杂,否则一直提示错误


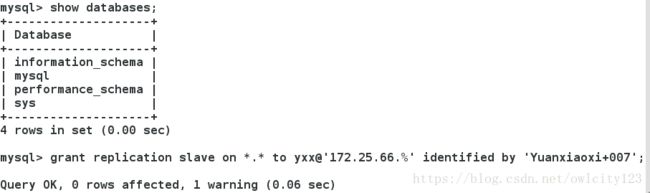
在master中:查看状态

在server8中:
vim /etc/my.cfg

查看授权是否成功
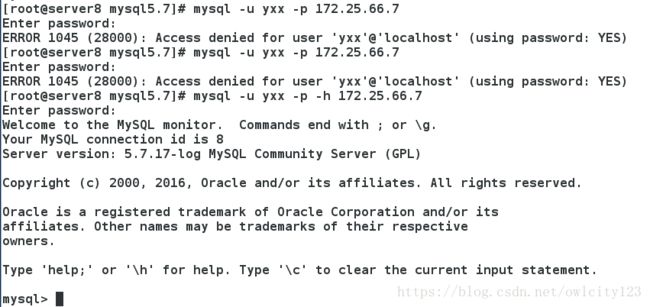
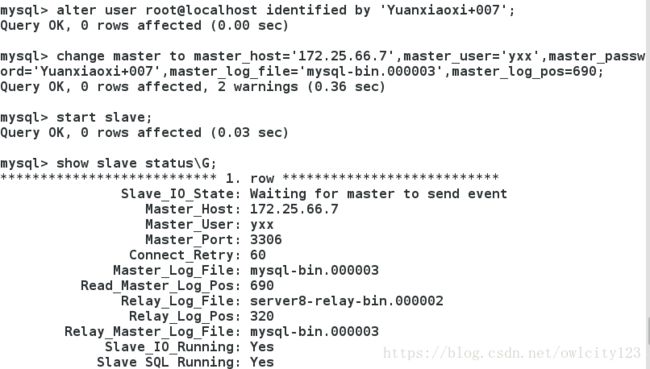
出现两个YES表示成功
测试:在master中

在slave中查看,数据已同步

基于gtid模式:
GTID是MySQL 5.6的新特性,其全称是Global Transaction Identifier,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog 都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
1、master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
2、slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
3、sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
4、如果有记录,说明该GTID的事务已经执行,slave会忽略。
5、如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
前面在slave端配置,进行change master to操作时, 使用的是日志号(指定position),当master端的服务down掉了, 就会在slave端选择一个日志号与原来的master最接近的作为master。但是,在另一个slave上,并没有指定新的master的信息,因此还要手动去指定,而使用gtid的话,slave通过寻找next的值,并不用指定master的二进制日志文件和日志号,所以使用gtid更能保证数据的完整性。
server6:172.25.13.6(master)
server7:172.25.13.7(salve)
在master中:
vim /etc/my.cfg

/etc/init.d/mysqld restart 重启mysql
在slave中:
vim /etc/my.cfg


mysql -p
![]()
![]()

测试:在master端插入数据

在slave端查看数据同步过来了

配置一主两辅

实验环境:server6作为master,server7和server8相对于server6是slave,把server7作为中继,扮演其他slave的master,此时,master7把SQL线程执行的事件写进自己的二进制日志,然后,master8可以获取这些事件并执行它,从而有效减轻master端的压力
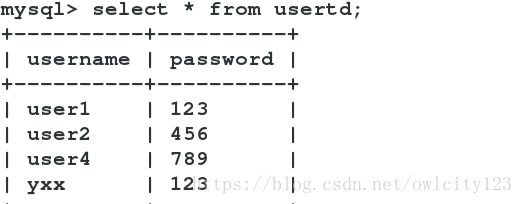
server6:首先要备份master中的数据,并将其拷贝到server8中来,实现初始数据相同,否则后面更新数据不会同步
mysqldump -p westos >westos.sql
scp westos.sql 172.25.13.8:
server8:安装数据库,完成初始化
vim /etc/my.cfg

/etc/init.d/mysqld start
vim westos.sql 去掉第24行,创建westos数据库

mysql -p < westos.sql
mysql -p
![]()
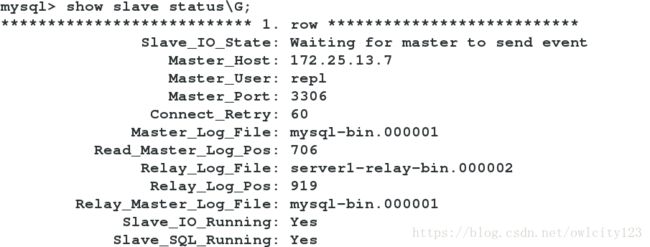
在srever7中:
vim /etc/my.cfg

log_slave_updates
用于设定复制场景中的从服务器是否将从主服务器收到的更新操作记录进本机的二进制日志中。本参数设定的生效需要在从服务器上启用二进制日志功能。
/etc/init.d/mysqld restart
![]()
测试:
在master中插入数据

在server7中查看数据已同步

在server8中查看数据也已同步
半同步复制配置
半同步简介:
在默认情况下,MySQL的复制是异步的,这意味着主服务器及其从服务器是独立的。异步复制可以提供最佳的性能,因为主服务器在将更新的数据写入它的二进制日志(Binlog)文件中后,无需等待验证更新数据是否已经复制到从服务器中,就可以自由处理其它进入的事务处理请求。但这也同时带来了很高的风险,如果在主服务器或从服务器端发生故障,会造成主从数据的不一致,甚至在恢复时造成数据丢失。
从MySQL5.5开始引入了一种半同步复制功能,该功能可以确保主服务器和访问链中至少一台从服务器之间的数据一致性和冗余。在这种配置结构中,一台主服务器和其许多从服务器都进行了配置,这样在复制拓扑中,至少有一台从服务器在父主服务器进行事务处理前,必须确认更新已经收到并写入了其中继日志 (Relay Log)。当出现超时,源主服务器必须暂时切换到异步复制模式重新复制,直到至少有一台设置为半同步复制模式的从服务器及时收到信息。
继5.5半同步复制后,MySQL5.6又对其进行了优化和改进,其中有两个地方较为重要:
1、在主从切换后,在传统的方式里,需要找到binlog和POS点,然后更改master指向,而在mysql5.6里,你无须再知道binlog和POS点,你只需要知道master的IP、端口,账号密码即可,因为同步复制是自动的,mysql通过内部机制GTID自动找点同步。
2、多线程复制,以前的版本,同步复制是单线程的,只能一个一个执行,在MySQL5.6里,可以做到多个库之间的多线程复制,但一个库里的表,多线程复制是无效的。
在主服务器上:
mysql -p
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> set global rpl_semi_sync_master_enabled=1; #开启master上的semisync,设置超时时间,可以通过设置rpl_semi_sync_master_timeout变量来修改,默认单位为毫秒
mysql> show variables like '%semi_sync%';

在从节点:
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> set global rpl_semi_sync_slave_enabled=1;
mysql> stop slave io_thread; #重启slave上的IO线程
mysql> start slave io_thread;
mysql> show global variables like '%semi%';

检测:
在master中:
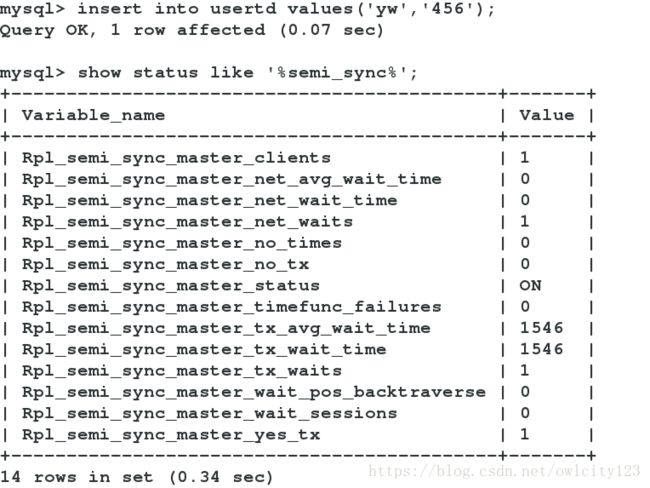
将slave中的半同步关掉,进行插入测试:
mysql> set global rpl_semi_sync_slave_enabled=OFF; ###将半同步设置为关闭
mysql> stop slave io_thread;
mysql> start slave io_thread;
mysql> show global variables like '%semi%';

当把从机的I/O线程关闭后,主数据库在进行对复制数据库的库进行更改时,在进行操作会等待10秒,增加了一次半同步传输的失败次数。因为使用半同步失败,10s后没有得到反馈信息,回转为异步方式
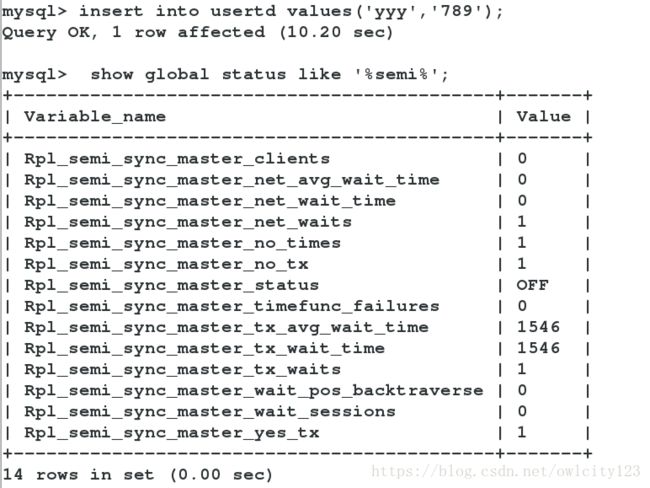
Rpl_semi_sync_master_yes_tx ##使用半同步成功的次数,数据一致性性能提高
Rpl_semi_sync_master_no_tx ##使用半同步失败的次数,10s后没有得到反馈信息,会转为异步复制