在阿里实习两个月,我的一些收获和成长
文章目录
-
-
- 一、忙碌的暑假
- 二、认知沉淀
-
- 2.1、此时此刻,非我莫属
- 2.2、结果导向,拥抱变化
- 2.3、Stay hungry,Stay foolish,But be crazy
- 三、业务沉淀
-
- 3.1、稳定性保证
- 3.2、单元测试及代码规范
- 3.3、DRY原则及低注释原则
- 3.4、Idea全局搜索
- 四、技术沉淀
-
- 4.1、阿里内部中间件技术
-
- 4.1.1、HSF
- 4.1.2、Diamond及ConfigServer
- 4.1.3、MetaQ
- 4.1.4、其他技术
- 4.2、Arthas
- 4.3、Git高级命令
- 4.4、Apache Chains链式调用
- 4.5、Mockito及PowerMockito
- 4.6、PlantUML
- 4.7、Maven Helper
- 五、总结和展望
-
一、忙碌的暑假
这两个月都在忙碌的实习中度过,自己的博客也很久没有更新过了,哈哈哈。(其实一直都有写,不过是写在了公司内网里边,由于数据安全问题不能够转出来)。
前几天刚答辩完,刚回到广州的第二天,最近闲了下来准备开始秋招了,趁这个机会也写写这两个月的实习总结,也算是对这段实习经历的一个回顾与沉淀吧。
二、认知沉淀

首先想要写的一块是自己这两个月来的一些认知上的沉淀,这一块内容不属于技术上的东西,但是却必不可少,因为认知是可以指导工作的,这里主要想记录下面对我帮助很大的三点。
2.1、此时此刻,非我莫属
“此时此刻,非我莫属”其实是阿里价值观里边的一个内容,算是阿里内部比较常说的slogan,办公室里边很多宣传栏上边也都会提到。
第一眼感觉这句话太酷了,阿里本身就有一个充满了“侠客”的技术江湖,大家取的花名都很具有江湖气息。各路顶尖技术高手聚在了一起,一起做一些有意义的事情,攻克技术或者业务难点,如果在这种环境下,想必大家对“此时此刻,非我莫属”这句话也会像我一样有强烈的共鸣。
我所在的钉钉事业部就是秉持着这样的价值观,在疫情期间发动全体钉钉员工一起对钉钉这款产品进行了快速迭代,并且在短短几天时间内推出了浙江防疫二维码这款产品,联合阿里云紧急扩容服务器万余台,免费开放万人大群以及提供流畅的视频会议,这是上千人的加班加点才换来的疫情期间各大企业员工及办公人员的线上稳定办公,以及上亿学生的稳定线上授课保障。
2.2、结果导向,拥抱变化
我是个比较喜欢自己专研的人,包括许多技术和知识,我之前更倾向于自学,如果我搞不懂了我才会去请教别人。
但是来到阿里后,主管给我上了一课,第一点就是结果导向。要以结果为目标,更快更好地去推进进度,而不是一味的闭门造车,过于自我化。
比如有一个技术点不明白,尽快去问自己身边的专家们,这是一个多么好的资源,可是却没有利用起来。第二点是一些项目中的业务问题或者业务流程不明白,最好是直截了当地问相关的代码提交人,问出了关键的代码后再去进一步梳理,而不要看不懂还硬着头皮看别人的代码,这会严重地影响需求开发的进度,自己看了大半天还没搞明白的东西,别人一提示就看懂了,可以大大地节约时间成本。
“拥抱变化”,无论是技术还是业务,永远都处于变化之后,唯一不变的东西就是变化自身,所以要做好周全的准备。
2.3、Stay hungry,Stay foolish,But be crazy
这是我很喜欢的一句话,也是钉钉这边的slogan。
Stay hungry,Stay foolish是在致敬乔布斯,要时刻记住保持学习,虚心若愚,而But be crazy是提醒自己要保持初心,保持着那股“疯狂劲儿”,记住自己作为一个技术人的初心是什么,努力提升自己的专业能力和业务能力。
愿你编码半生,归来仍是少年。记住自己刚写出Hello World的那种感觉,保持探索,坚持自己的热爱。
三、业务沉淀
第二点收获是业务上的一些沉淀,主要是一些业务思想,而不是具体的技术使用。
3.1、稳定性保证
首先我想着重记录的第一点是稳定性保证,这是我在阿里实习这段时间收获到的最有用的知识之一。
稳定性保证其实理解起来很简单,思想就是当业务在线上出现问题的时候,如何避免影响大范围的用户,如何阻止故障的扩散。
比如线上一个功能模块因为一些BUG影响了大规模的用户,如果不能及时地关闭掉这个模块的话这个故障就会在用户间进行传播,导致巨大的线上问题,直接就是P0故障,团队就可以等着拿325跑路了。
为了做好稳定性保证,可以把需求开发流程分成以下阶段:

其中日常验证指的是在日常环境中对需求做充分的验证,简单些的自己想一些Bad Case去验证一些系统是否能够做到正确的响应,或者找需求提出方或者测试人员进行测试,如果日常环境测试不通过,那么打回代码设计阶段,找BUG并进行编码修复。
经过日常验证后,要对功能做灰度开关,也就是在线上只对小范围用户放量,比如1%的灰度,让这部分用户去体验到这个功能,然后程序里边可以做双读校验去进行日志记录,最后使用脚本进行分析这部分用户使用功能的执行结果是否符合预期,或者比较粗暴一点就让用户自己反馈使用过程中遇到的问题。简而言之,灰度开关就是要让小范围用户去做“内测”,让他们做程序的“测试”人员。当小部分人使用没问题后,再逐步扩大灰度,直到功能全量。
做好了灰度开关后,还需要多做一个功能开关,也就是万一这一块真的还有其他问题,直接把功能开关关掉,不要再让用户走到错误的功能里去,避免影响大范围的用户,最后可以给个降级提醒。
3.2、单元测试及代码规范
第二点业务提升在于单元测试和代码规范。
在阿里,非核心应用日常代码部署的标准是80%的代码增量测试覆盖率,核心应用日常代码部署的标准是90%的代码增量测试覆盖率。可见的单元测试有多么的重要。
单元测试指的以方法或函数为单元进行测试,在这个过程中不可依赖外界数据源(MySQL、Redis、RCP调用、配置中心等都属于外界数据源),只对代码的执行流程进行测试,如果需要依赖外界数据源则需要Mock数据。
我自己就通过单元测试发现过自己代码中的流程错误,从而避免了潜在的线上问题。
但是单元测试有一点不好在于有些代码只是对一些数据进行封装处理,没有太多的逻辑,所以会存在“为了单元测试而单元测试”的情况,这也会影响需求开发的效率。
代码规范的话,基本上都是遵守的《阿里巴巴Java开发规范》,主要要注意的就是代码变量命名规范、全局异常处理规范、函数名命名规范、单侧书写规范等。设计模式不要乱用,过度设计不如没有设计,代码最重要的就是规范性以及易读性。
3.3、DRY原则及低注释原则
DRY原则指的是Dont Repeat Youself,不要在代码中重复自己,也就是要做好代码的复用。
一般来说如果一段代码在不同的地方出现了3次,就可以考虑封装起来了,不然越来越多的重复出现时,如果需要改动这段逻辑,就会异常痛苦。
低注释原则指的是将代码也视为一种表达语言,注意方法的命名和封装(动词+名词),达到大部分地方只通过代码就能够清晰地表达程序执行的大致流程,只在关键的代码上加上注释。这种做法的好处是极大地避免了无用的注释(能用代码说清楚的话就不要用注释来表达,不然就是代码的封装和抽象能力不够)。
3.4、Idea全局搜索
Idea全局搜索也是一个很有用的功能,比如修改一个配置项,就可以通过全局搜索的功能找到每一个被使用到的地方,然后进行修改;或者是想找到某个类是在Spring的哪个配置文件中配置的,也可以进行全局的搜索而确定。这可真是个好东西啊!
四、技术沉淀
技术沉淀的话主要写自己这两个月用得比较多的技术和一些工具。
4.1、阿里内部中间件技术
众所周知,阿里的Java技术栈的深度和广度都是全国顶尖的,整个后端开发几乎只需要依赖于Spring和Maven就可以搞定,其他的譬如RPC、MQ、分布式事务处理、任务调度、注册中心、配置中心、灰度开关、缓存、表格储存等技术都基于阿里云中间件团队或者淘宝中间件团队的实现,所有的部门都会借助这些中间件进行业务开发。
在实习过程中自己用得比较多的是HSF、MetaQ、Diamond、Tair这几款中间件,其实说白了就是RPC框架、MQ、持久化配置中心、分布式缓存。
4.1.1、HSF
HSF(High Speed Framework 高速服务框架)是阿里内部使用最多的RPC框架,几乎所有的分布式应用都是通过HSF来构建的。
HSF的主要特性是使用简单、支持异步调用和泛化调用、有良好的控制台支持、支持多种集群容错策略、可对调用链路进行Filter拓展以及良好的SLA保证。
其实相对来说,Dubbo的功能及文档是更加全面的,比如Dubbo的SPI做的很好,基本上HSF有的功能Dubbo都有,但是因为一些历史原因,HSF诞生于淘宝,经过了十几年的大流量验证,所以内部更加倾向于使用HSF。并且HSF可以和阿里内部的配置中心、框架无缝整合在一起,这也是HSF自身的一大优势之一。
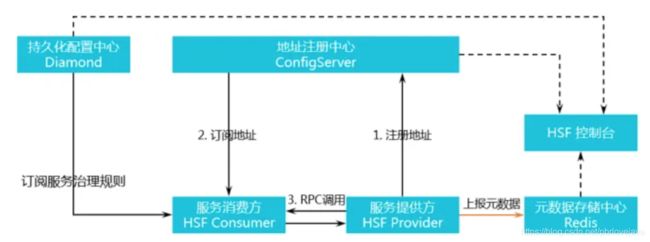
和Dubbo的服务调用过程类似(基本上Java的RPC框架的设计核心原理都是差不多的),HSF也需要借助注册中心(ConfigServer)来提供将自己的服务(接口全限定名+版本号+调用方法+参数列表)注册到注册中心中,一般内容都为服务提供方IP地址+RPC协议+序列化协议+重试次数+集群容错策略,然后客户端根据注册中心中中需要调用的接口全限定名及参数找到这个服务提供方IP,使用Netty建立一个连接,客户端将请求参数编码序列化成通信对象发送给服务提供方,服务提供方拿到后做反序列化和解码,最后通过反射调用拿到具体的返回值返回即可。

4.1.2、Diamond及ConfigServer
Diamond和ConfigServer都是阿里内部通用的注册中心,但是不同之处在于Diamond是持久化的注册中心,并且更加适合于做分布式配置中心和灰度控制,而ConfigServer是HSF的地址服务注册中心,是非持久化的注册中心。
先说说Diamond。
Diamond主要的特点是持久化、配置化、变更主动推送,基于推拉结合的发布订阅模型。阿里内部一般使用Diamond来存储持久化的、不会经常变更的配置数据,一般采用JSON形式进行存储,比如可以存储灰度配置信息及一些数据的配置信息。另外的一大特点是当通过控制台变更Diamond配置时,会触发程序中配置的监听器,然后更新程序中的配置信息(实质上是长轮询)。

再来看看ConfigServer。
ConfigServer是一款基于发布订阅模式的非持久化的配置中心,比如HSF的地址服务注册中心就是ConfigServer。其主要特性是支持数据的列表聚合(把数据聚合成一个List)以及连接失效后,会自动删除掉该连接所写入的数据,也就是非持久化的体现。
这就可以在HSF的服务提供方挂掉时及时地把列表里的IP等信息删掉,防止服务调用方调用到不存在服务的机器。
4.1.3、MetaQ
MetaQ是阿里内部的一款分布式消息中间件,MetaQ3.0实质就是内部版的RocketMQ。
由于MetaQ一开始的设计参考了Kafka,所以两者的使用来说是比较相似的,并且底层的消息存储结构也具有一定的相似性。
MetaQ主要的特点是支持海量数据堆积、可严格顺序消费、每条Topic都可回溯状态、Topic重发接收不成功时会进入死信队列保留、高稳定SLA保证、支持负载均衡、支持数据持久化。
和Kafka比较的话,第一点不同在于MetaQ使用Tag作为消息发布及订阅的最小单位,而Kafka则是以partition作为最小单位。
第二点不同在于底层的消息存储结构设计,Kafka会把Topic分为多个partition,一个partition实质上就是一个独立的文件,读写都会在这个文件中进行追加,也就是磁盘顺序读写。但是当partition过多后,Kafka的读写性能就会存在瓶颈,因为这相当于把磁盘给分散化了,形成了随机读写。
而MetaQ为了优化这一点,采用了虚拟队列及真实磁盘存储空间配合的方式,采用虚拟队列来追加Tag的消息,而每条消息中存储的只是索引,索引到唯一的真是磁盘空间,而真实磁盘空间中仍然采用了顺序写的方式。

4.1.4、其他技术
其他我觉得比较好的技术是一些监控上的技术,比如鹰眼(EagleEye),可以用于分布式环境下的全链路追踪快速定位问题。不然RPC调用太多了,根本不知道是哪一块调用发生的问题,很难排查。
还有一个技术是LogService,是阿里云的日志分析服务,可以用来聚合分析多台机器的日志,从而达到快速的数据分析和错误排查的效果。
Sentinel,阿里开源的稳定性中间件,主要用于请求限流、服务降级以及熔断处理,是分布式环境下被频繁使用的中间件。
4.2、Arthas
Arthas是阿里开源的一款Java开发线上诊断工具,继承了JVM工具,能够替代大部分需要查看日志的场景,比如线上某个方法调用异常分析等等。
基本原理:通过cglib动态代理技术,动态修改正在运行时的方法,生成切面,拦截到执行的入参、出参等所需参数并进行分析。
排查问题常用操作:
- monitor
对方向执行结果进行监控,可以获得一个周期内方法的调用次数、失败率、rt等,是非实时的监控。
使用方式如下: monitor className methodName -c 10,标明对特定类特定方法做监控,-c 10表示监控刷新时间为10s,每次会将1个周期内的调用数据统计出来
- watch
对方法的执行过程数据进行监控,可以获得方法执行前后入参、返回结果,是实时的监控。使用方式如下:
watch className methodName need ognl -b -x 2, need使用{params,returnObj}来制定要看到的指标,ognl为ognl表达式,可用于做数据过滤来查看指定的方法,-b表示在方法执行前进行观察,-x表示参数和返回值的解析深度,默认为1。
watch命令可以通过参数切入不同的事件点来观察参数及返回值,通过-b表示 方法调用前,-e 表示方法异常后,-s 表示方法返回后,-f 表示方法结束后,默认是-f也就是方法执行结束后显示入参和返回值(此时入参可能被改变了),所以如果要查看方法的入参,需要-b指定在方法调用前监测。
返回值含义: @ [入参(params)], @ [方法内部调用(target)], @ [返回值(returnObj)] 使用ognl表达式根据特定入参或者返回值过滤方法: https://github.com/alibaba/arthas/issues/71
- trace
对方法的内部调用路径及耗时进行监控,可以取得具体的方法调用路径(默认屏蔽JDK库调用路径),以及调用的时间。
- stack
查询当前方法的调用路径进行分析,获取到方法的具体调用方
- tt
和watch类似,都可以获取到方法的入参和返回值进行分析,但是不同之处在于tt可以不断地进行分析
4.3、Git高级命令
GitFlow主干开发流(项目驱动,小团队开发,统一合并到主干测试,本地分支不提交到远程)、多分支开发流(大团队开发,不统一合并到主干,本地分支提交到远程进行测试,最后合并到主干)
- git revert
和git reset类似,都可用于回退commit版本,但是git revert可以再基于该版本生成一个新的回退commit,仍然保留之前的commit
撤回某次commit的内容,并且基于本次撤回新建一个commit
- git cherry-pick
用于从拿另一个分支的几个commit的情况
对于多分支的代码库,将代码从一个分支转移到另一个分支是常见需求。一种情况是需要另一个分支的所有代码变动,那么可以分支合并(git merge),而另一种情况是只需要部分代码变动(某几个提交),这时可以采用 Cherry pick
- git stash
用于在分的分支写代码,突然需要切到主的分支,但是当前代码并不完善,不希望commit到本地版本库的情况
暂存当前分支的工作区代码改动而无需add和commit到当前版本库就可以切换到其他分支。当切换回当前分支后使用git stash pop恢复之前的改动,git stash list可以查看所有的暂存
- git rebase
用于合并多个commit以及将本分支代码“变基”到另一个分支的头上,和merge不同之处在于merge会保留两个分支的历史commit,而rebase会直接删去当前分支之前的commit记录
用于合并多个提交到一个提交中,避免提交过多导致污染;也可以起到merge的作用,(A)git rebase B后,会抹去A分支之前的提交内容,直接把A分支建立于B分支之上,而merge会保留A分支和B分支的提交内容,并且在log中可以看到merge。

4.4、Apache Chains链式调用
在日常的工作中,我们经常会碰到一些业务流程比较复杂的场景,这些东西糅合到一个方法里就使得代码耦合度特别高,随着业务场景逻辑的越来越多,就会越来越复杂,难以维护。
如提交的订单的动作可能涉及到如下场景:
- 各种各样的校验
- 各类信息的补充
- 订单提交成功/失败后产品信息/库存的改变
- 订单提交成功/失败后支付信息/状态的改变
- 订单提交成功/失败后的各种推送
Apache commons chain,原理是责任链模式。大致实现方式是根据不同的业务场景,建立多个Command,每个Command处理各自的业务逻辑,每个Command执行完毕后,将处理后的处理传给下一个Command,直到所有执行完毕。
通过Spring就可以做到快速地组装和调整每个Command的执行顺序,使得代码更加清晰易懂并且易于复用。

4.5、Mockito及PowerMockito
单元测试指的是对单个方法、函数、过程等最小单位进行的测试,通常用于校验实现逻辑的正确性,一般核心的流程或者复杂的流程应该经过单测,并且要有较高的单测覆盖率。
Mockito及PowerMockito是Java开发中很常用的两款单测框架,其使用简单并且功能强大。Mockito常被用于Mock一些依赖的外部类和方法,而PowerMockito常被用于Mock静态方法和私有方法。
单测可以说是我在阿里代码写得最多的了,基本上和需求代码五五开。
一个标准的单测,应该符合以下几点要求:
- 无论执行多少次,都是通过的
- 测试的方法不依赖于外界真实数据
- 都需要具备断言判断
- 对于不同情况的测试应该拆分出不同的测试方法
- 单测中不可含有println这样的直接输出或者log
- 核心流程的代码单测要保证高覆盖率
写单测有什么好处呢?总结了如下两点:
- 对程序的执行流程做正确性校验,在方法级别避免BUG的发生
- 纠正坏代码风格,为了写单测就需要把代码给做好足够的抽象和封装,不然单测是写不下去的
4.6、PlantUML
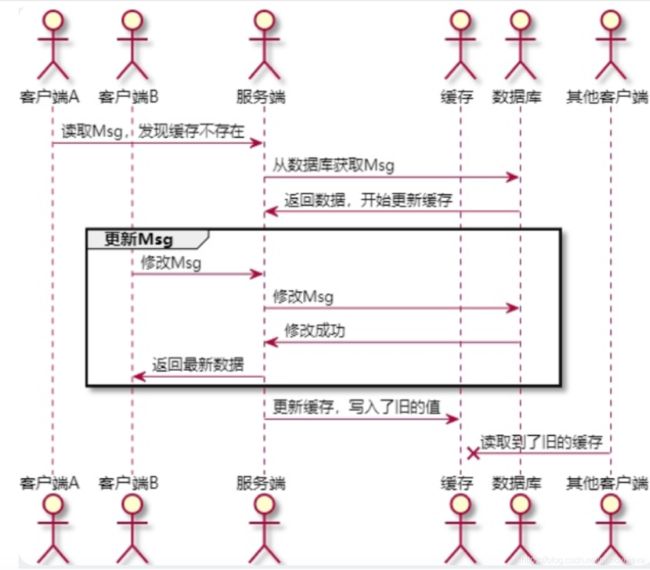
在实习过程中另一个常用工具就是PlantUML,这是一个使用文字绘图的工具,使用PlantUML可以轻松地画出符合规范的时序图,并且便于修改。
4.7、Maven Helper
Maven helper是Idea里边的一个插件,可以快速地分析依赖冲突问题并且解决冲突。

五、总结和展望

两个月的时间很快就过去了,十分感谢阿里巴巴钉钉事业部给了我一个实习的机会,让我这个非科班菜鸡能和各位大佬们在一个平台上学习与成长。
在实习的过程中还是发现了自己许多不足的,比如:
技术上的:
- 代码写得不够好看,不够精简,没有考虑如何给后人维护。在之后写代码的过程中,要力求把代码写得简单易懂,并且要考虑到代码的复用以及标准化,不要写“一次性”代码,代码要复合DRY和低注释原则。
- 对技术的理解不够深刻,许多技术只停留在使用层面,而没有进行过多的思考。所以后续写博客的话,发出来的东西要做到尽量有价值,有思考,而不只是CV和一味的笔记记录。
- 后续要较深入的学习和了解的方向:Spring、Dubbo、Kafka。
其他方面:
- 表达能力有待提高,如何快速地表明自己的意图,如何高效地沟通,如何做好一份PPT等,都是需要不断地锻炼。
- 有点儿害羞,特别是问别人问题的时候,总是会习惯自己考虑问题,而不是找特定的人去解决特定的问题,不够push,之后要加强这方面的锻炼,多与人沟通,多向优秀者学习。
Stay hungry, Stay foolish, But be crazy.