【3D计算机视觉】3P-RNN实现点云场景分割
《3D Recurrent Neural Networks with Context Fusion for Point Cloud Semantic Segmentation》论文笔记
一、论文摘要
基于3D点云的语义分割是一个非常开放的话题,基于神经网络的3D语义分割很难实现是因为3D点云所包含的内容信息太少。该论文作者构建了一个新的3P-RNN来实现点云的语义分割(之所以叫3P是因为其中有一个关键的步骤叫作Pointwise Pyramid Pooling)。首先,论文构建了一个高效的金字塔池化模型(pyramid pooling module)来提取3D点云的局部信息,再通过一个双向的RNN提取空间的点云全局依赖性。两个RNN通过不同的方向扫描3D空间提取信息,最终达到良好的3D语义分割的效果。
二、模型概述
以往的3D语义分割都现将3D点云体素化(voxelization),但是由于3D点云的稀疏性,体素化往往会导致很大的计算量。但自从Pointnet的出现,点云数据可以直接放入网络进行训练。Pointnet首先通过多层网络将原本三维的点云数据扩充到1024维,再通过一个对称函数max pooling使得其提取到全局的信息。但Pointnet同样在进行复杂点云的语义分割时具有许多的局限性:第一,其在max pooling的时候只考虑到了全局的信息(虽然后面Pointnet++中有部分解决这个问题,但是繁杂的步骤使其计算量很大);第二,其没有考虑到邻近点云的相互关系。(例如椅子总是贴近桌子等)作者针对第一个问题建立了一个金字塔池化模型(其利用的多步长的单窗口池化),而面对第二个问题其利用了一个双向RNN捕捉邻近点之间的关系(即对堆叠的feature map以x和y两个方向构建RNN网络)。

三、3P模型
作者在点云数据的处理上依然沿用了Pointnet的方法。简要来说,pointnet就是对点云数据逐个点的提取特征,经过了一系列的MLP(多层网络感知器),将本来三维的点云数据 ( n , x i , y i , z i ) (n,x_i,y_i,z_i) (n,xi,yi,zi)(n是点云中点的个数)映射到1024维的空间中 ( n , 1024 ) (n,1024) (n,1024),再通过一个对称的运算maxpooling提取其点云的全局信息将其压缩至 ( 1 , 1024 ) (1,1024) (1,1024)。其具体的公式可以由下述公式表示:
F ( p 1 , p 2 , . . . , p N ) = M L P i = 1 , . . . , N ( C ( m a x p o o l ( M L P i = 1 , . . . , N ( p i ) ) , M L P i = 1 , . . . , N ( p i ) ) ) F (p_1 ,p_2 ,...,p_N ) =\mathop{MLP}\limits_{i=1,...,N}(C(maxpool(\mathop{MLP}\limits_{i=1,...,N}(p_i )),\mathop{MLP}\limits_{i=1,...,N}(p_i ))) F(p1,p2,...,pN)=i=1,...,NMLP(C(maxpool(i=1,...,NMLP(pi)),i=1,...,NMLP(pi)))
其中C是channel通道的拼接操作,从1:N也能看出逐点计算特征。
在Pointnet出现后,有很多的网络试图改善其没有办法获取局部特征的缺陷——例如Pointnet++,首先选取一些比较重要的点作为每一个局部区域的中心点,然后在这些中心点的周围选取k个近邻点(欧式距离的近邻),再将k个近邻点作为一个局部点云采用pointnet网络来提取特征。其虽然有作用,但是却十分地繁杂并很耗费计算量,而本篇作者提出了一个逐点的金字塔池化模型(Pointwise Pyramid Pooling,简称3P)。

3P的表达式如下:
P ( p 1 , p 2 , . . . p N ) = [ m a x p o o l p = p 1 , . . . , p N ( f , k 1 ) , . . . , m a x p o o l p = p 1 , . . . , p N ( f , k m ) ] P (p 1 ,p 2 ,...p N ) = [\mathop{maxpool}\limits_{p=p_{1} ,...,p_N}(f,k_1 ),..., \mathop{maxpool}\limits_{p=p_1 ,...,p_N}(f,k m )] P(p1,p2,...pN)=[p=p1,...,pNmaxpool(f,k1),...,p=p1,...,pNmaxpool(f,km)]
其中 k i k_i ki表示步长为1的不同尺寸的maxpooling的窗口大小, f f f表示经过MLP的高维点云特征
作者认为以往stride大于1的pooling其主要目的在于压缩特征,故会损失掉很多有用的信息。作者的处理方法简单却有效,就是用了不同尺寸的步长为1的maxpooling来进行这一步对称运算。然后将其得到的特征再拼接起来形成新的特征输入后面的网络中(在实验中作者采用的pooling size是N,N/8和N/64)。其主要的优点在于没有在这些pooling操作中不需要训练参数,因此速度非常得快,效果也不错。
这里还需要解释一下其pyramid pooling和Pointnet中pooling的区别,可以先看下图(Pointnet的结构图),在Pointnet中,池化的作用实际上是将N个点云中的点的高维特征 ( N , D ) (N,D) (N,D)在N的维度上进行了max pooling,输出的结果是 ( 1 , D ) (1,D) (1,D),其作用是归纳全局特征;而在3P模型中,由于步长是1,其max pooling是在D的维度上进行的,输出的结果是 ( N , F 1 + F 2 + F 3 ) (N,F_1+F_2+F_3) (N,F1+F2+F3),其中 F i F_i Fi是经过了第 i i i个尺寸的步长为1的max pooling后的某个点的高维特征的长度,最后再将这些不同尺寸的pooling的结果拼接起来,就形成了一个新的3D数据。因此它的作用对应的是Pointnet++中利用不同尺寸的k近邻归纳局部特征的那一步,而并非全局特征。

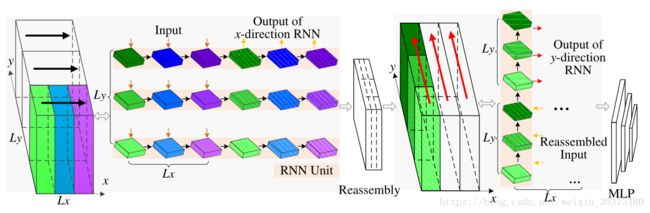
四、双向RNN
经过了3P模块后,输入3P前的全局特征先通过拼接的方法和3P模块的输出结果(局部特征)进行拼接,这一步其实相当于在3P模块中加入了一个尺寸为1的步长为1的max pooling。
输入RNN的其实是一个2D的数据(不要被图中的cubic误导了,垂直方向并没有一个维度),其分别有两个方向的维度 ( L x , L y ) (L_x,L_y) (Lx,Ly),其中 L x L_x Lx是经过不同尺寸的池化后的局部特征与全局特征拼接的那个维度,维度是 F 1 + F 2 + F 3 + D F_1+F_2+F_3+D F1+F2+F3+D; L y L_y Ly是不同点云点拼接的那个维度,其长度为N,然后作者首先将X维度的每个X(一个点的全局加局部特征总和的sequence)作为一个输入,Y维度作为time step方向训练一次LSTM,再将结果用同样的方法在垂直方向上训练一次。最后的输出再与一开始的全局特征拼接一次,然后输入进MLP去预测N个点每一个点的类别,进行场景分割。
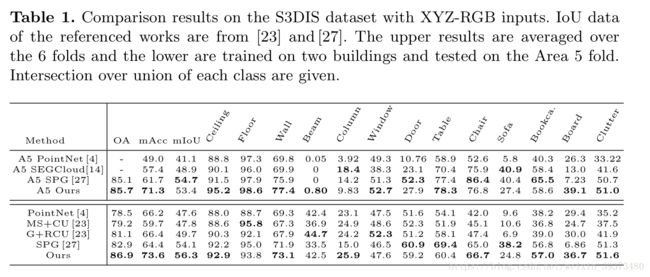
五、实验结果
从实验结果看了,在所有数据集上都表现良好,远超原版的Pointnet和Pointnet++: