Redis4.0集群
一、安装Redis4.0
rm -f /var/run/yum.pid
yum -y install cpp binutils glibc glibc-kernheaders glibc-common glibc-devel gcc make gcc-c++ libstdc++-devel tcl
cd /usr/local/
wget http://download.redis.io/releases/redis-4.0.11.tar.gz
tar -zxf redis-4.0.11.tar.gz
ln -s usr/redis-4.0.11 /usr/local/redis
cd /usr/local/redis
make
make install
#不喜欢手敲的可以使用小脚本
rm -f /var/run/yum.pid
yum -y install cpp binutils glibc glibc-kernheaders glibc-common glibc-devel gcc make gcc-c++ libstdc++-devel tcl
if [ ! -d /usr/local/redis-4.0.11 ];then
wget http://download.redis.io/releases/redis-4.0.11.tar.gz -O/tmp/redis-4.0.11.tar.gz
if [ $? -eq 0 ];then
echo "下载成功"
tar -zxf /tmp/redis-4.0.11.tar.gz -C /usr/local/
else
echo "下载失败"
exit 1
fi
fi
ln -s /usr/local/redis-4.0.11 /usr/local/redis
cd /usr/local/redis
make
make install
cp /usr/local/redis/redis.conf /etc/
vi /etc/redis.conf
# 开启守护进程,修改如下,sed -i 's/daemonize no/daemonize yes/g' /etc/redis.conf
daemonize yes
#启动
redis-server /etc/redis.conf
#测试
redis-cli
#小脚本
二、主从复制(读写分离)
主从复制的好处有2点:
1、避免redis单点故障
2、构建读写分离架构,满足读多写少的应用场景。
2.1 启动实例
创建6379、6380、6381目录,分别将安装目录下的redis.conf拷贝到这三个目录下

分别进入这三个目录,分别修改配置文件,将端口分别设置为:6379(Master)、6380(Slave)、6381(Slave)同时设置pidfile文件为不同的路径。

分别启动三个redis实例:
redis-server /root/6379/redis.conf
redis-server /root/6380/redis.conf
redis-server /root/6381/redis.conf
redis-cli -p

2.2 设置主从
在redis中设置主从有2种方式:
1、 在redis.conf中设置slaveof #主库不需要设置,设置2个从库的。
a) slaveof
2、 使用redis-cli客户端连接到redis服务,执行slaveof命令
a) slaveof
第二种方式在重启后将失去主从复制关系。
查看主库信息:INFO replication
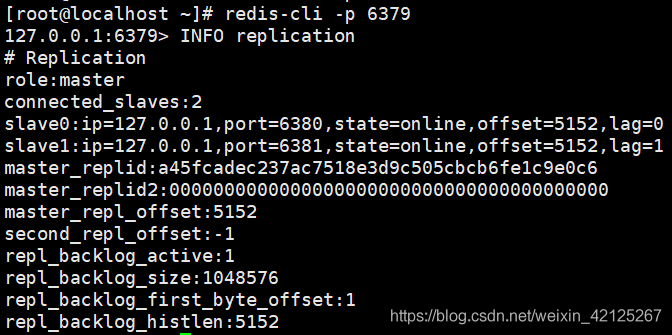
role:角色
connected_slaves:从库数量
slave0:从库信息
查看从库信息:INFO replication
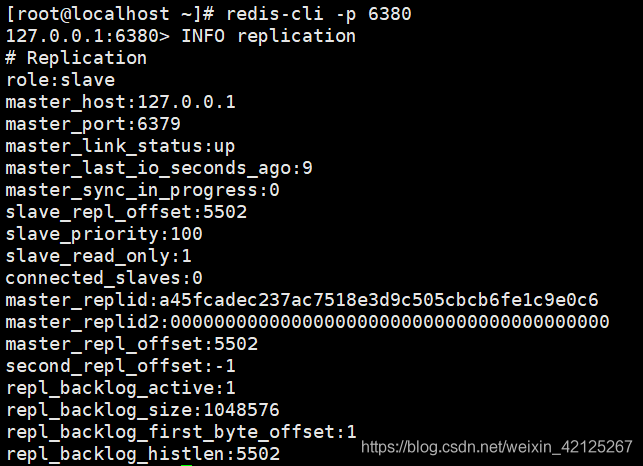
查看从库信息:INFO replication

2.3 测试
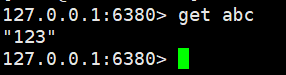
主库创建数据:

从库6380查看数据:
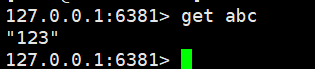
从库6381查看数据:
2.4 从库只读
默认情况下redis数据库充当slave角色时是只读的不能进行写操作。、

可以在配置文件中开启非只读:slave-read-only no
2.5 复制的过程原理
1、 当从库和主库建立MS关系后,会向主数据库发送SYNC命令;
2、 主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来;
3、 当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis;
4、 从Redis接收到后,会载入快照文件并且执行收到的缓存的命令;
5、 之后,主Redis每当接收到写命令时就会将命令发送从Redis,从而保证数据的一致;
2.6 无磁盘复制
通过前面的复制过程我们了解到,主库接收到SYNC的命令时会执行RDB过程,即使在配置文件中禁用RDB持久化也会生成,那么如果主库所在的服务器磁盘IO性能较差,那么这个复制过程就会出现瓶颈,庆幸的是,Redis在2.8.18版本开始实现了无磁盘复制功能(不过该功能还是处于试验阶段)。
原理:
Redis在与从数据库进行复制初始化时将不会将快照存储到磁盘,而是直接通过网络发送给从数据库,避免了IO性能差问题。
开启无磁盘复制:repl-diskless-sync yes
2.7 复制架构中出现宕机情况,怎么办?
如果在主从复制架构中出现宕机的情况,需要分情况看:
1、 从Redis宕机
a) 这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据;
b) 问题? 如果从库在断开期间,主库的变化不大,从库再次启动后,主库依然会将所有的数据做RDB操作吗?还是增量更新?(从库有做持久化的前提下)
i. 不会的,因为在Redis2.8版本后就实现了,主从断线后恢复的情况下实现增量复制。
2、 主Redis宕机
a) 这个相对而言就会复杂一些,需要以下2步才能完成
i. 第一步,在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务;
ii. 第二步,将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来;
b) 这个手动完成恢复的过程其实是比较麻烦的并且容易出错,有没有好办法解决呢?当前有的,Redis提供的哨兵(sentinel)的功能。
三、哨兵(sentinel)
哨兵就是对Redis的系统的运行情况的监控,它是一个独立进程。它的功能有2个:
1、 监控主数据库和从数据库是否运行正常;
2、 主数据出现故障后自动将从数据库转化为主数据库;
Sentinel的工作方式:
1):每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令
2):如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
3):如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4):当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线
5):在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令
6):当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
7):若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。
若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
3.1 坏境配置

3.2 配置哨兵
启动哨兵进程首先需要创建哨兵配置文件:
vim /root/sentinel.conf
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel down-after-milliseconds mymaster 30000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
启动哨兵进程:
redis-sentinel /root/sentinel.conf
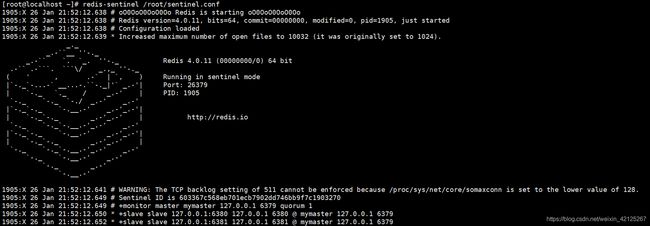
由上图可以看到:
1、 哨兵已经启动,它的id为603367c568eb701ecb7902dd746bb9f7c1903270
2、 为master数据库添加了一个监控
3、 发现了2个slave(由此可以看出,哨兵无需配置slave,只需要指定master,哨兵会自动发现slave)
3.3 从数据库宕机

kill掉1721进程后,30秒后哨兵的控制台输出:
1979:X 26 Jan 19:52:50.406 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
说明已经监控到slave宕机了,我们将3380端口的redis实例启动,查看是否会自动加入到主从复制中。
redis-server /root/6380/redis.conf
控制台输出:
1979:X 26 Jan 19:53:29.829 * +reboot slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
1979:X 26 Jan 19:53:29.887 # -sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
可以看出,slave从新加入到了主从复制中。-sdown:说明是恢复服务。
3.4 主数据库宕机
我们手动关闭Master 之后,sentinel 在监听master 确实是断线了之后,将会开始计算权值,然后重新分配主服务器。

从上图我们可以看出主库断开之后,sentinel帮我们选择了6381作为新的主服务器。
我们去6381查看状态

我们重新启动6379看看会发生什么?
1905:X 26 Jan 22:10:22.752 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
1905:X 26 Jan 22:10:32.737 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
第一条:6379 已经恢复服务
第二条:将6379设置为6381的slave
3.5 多哨兵
1、分别创建不同的sentinel.conf
2、修改sentinel.conf文件port端口
3、分别启动sentinel指定不同配置文件

四、集群
4.1 搭建集群需求配置环境
安装Ruby
因为redis-trib.rb脚本是有ruby语言编写的所以需要安装ruby环境
yum -y install zlib ruby rubygems
手动安装:
下载地址https://rubygems.global.ssl.fastly.net/gems/redis-3.2.1.gem
rz上传redis-3.2.1.gem
gem install -l redis-3.2.1.gem
ruby -v #查看ruby版本
gem -v #查看gem版本
4.2 创建集群
cd /usr/local/
mkdir redis-cluster
mkdir 6379 6380 6381 #创建6379、6380、6381三个目录
cp /usr/local/redis/redis.conf /usr/local/redis-cluster/6379/ #拷贝配置文件到6379,6380,6381目录中
vim redis.conf
daemonize yes #redis后台运行
pidfile /var/run/redis_6379.pid #pidfile文件对应7000,7002,7003
port 6379 #端口6379,6380,6381
cluster-enabled yes #开启集群 把注释#去掉
cluster-config-file nodes_6379.conf #集群的配置 配置文件首次启动自动生成
cluster-node-timeout 5000 #请求超时 设置5秒够了
appendonly yes #aof日志开启 有需要就开启,它会每次写操作都记录一条日志

#创建3个实例
将 ruby 脚本拷贝到 redis-cluster 目录中,输入命令 " cp -r redis-trib.rb /usr/local/redis-cluster

启动实例,手动启动太麻烦,创建个脚本

chmod o+x redis-start-all.sh #给脚本运行权限
#脚本实例启动过程

ps -ef|grep redis #查看实例启动状况

./redis-trib.rb create --replicas 0 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381

4.3 测试

(error) MOVED 7638 127.0.0.1:6380
因为name的hash槽信息是在6380上,现在使用redis-cli连接的6379,无法完成set操作,需要客户端跟踪重定向。
redis-cli -c

看到由6379跳转到了6380,然后再进入6379看能否get到数据

还是被重定向到了6380,不过已经可以获取到数据了。
4.4 插槽的分配
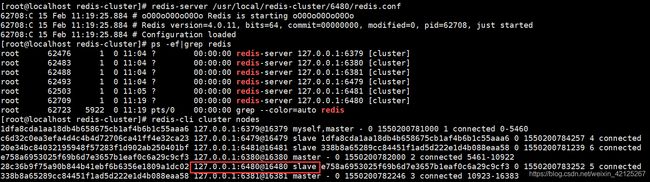
通过cluster nodes命令可以查看当前集群的信息:

该信息反映出了集群中的每个节点的id、身份、连接数、插槽数等。
当我们执行set name 123命令时,redis是如何将数据保存到集群中的呢?执行步骤:
- 接收命令set name 123
- 通过key(name)计算出插槽值,然后根据插槽值找到对应的节点。(name的插槽值为:7638)
- 重定向到该节点执行命令
整个Redis提供了16384个插槽,也就是说集群中的每个节点分得的插槽数总和为16384。
./redis-trib.rb 脚本实现了是将16384个插槽平均分配给了N个节点。
注意:如果插槽数有部分是没有指定到节点的,那么这部分插槽所对应的key将不能使用。
4.5 插槽和key的关系
计算key的插槽值:
key的有效部分使用CRC16算法计算出哈希值,再将哈希值对16384取余,得到插槽值。
什么是有效部分?
- 如果key中包含了{符号,且在{符号后存在}符号,并且{和}之间至少有一个字符,则有效部分是指{和}之间的部分;
- key={hello}_tatao的有效部分是hello
- 如果不满足上一条情况,整个key都是有效部分;
- key=hello_taotao的有效部分是全部+
4.6 新增集群节点
再开启一个实例的端口为6382 #记得改配置文件的端口号

执行脚本:
./redis-trib.rb add-node 192.168.56.102:6382 192.168.56.102:6379

已经添加成功!查看集群信息:

没有分配插槽数
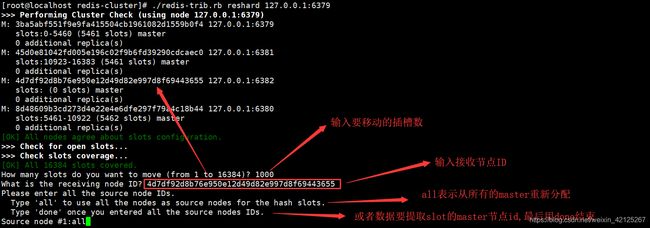
接下来需要给6382这个服务分配插槽,将6379的一部分(1000个)插槽分配给6382:
./redis-trib.rb add-node 127.0.0.1:6382 127.0.0.1:6379
![]()
查看节点情况:

4.7 删除集群节点
想要删除集群节点中的某一个节点,需要严格执行以下几点。
1、将这个节点上的所有插槽转移到其他节点上;
1.1 假设我们想要删除6380这个节点
1.2 执行脚本:./redis-trib.rb reshard 192.168.56.102:6380
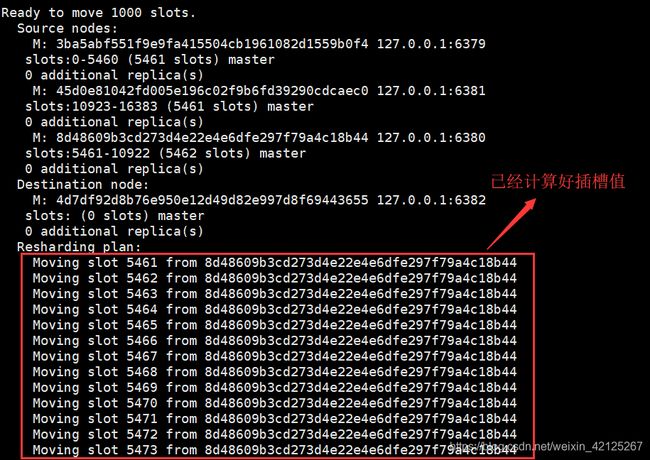
选择需要转移的插槽的数量,因为3380有5128个,所以转移5128个

输入转移的节点的id,我们转移到6382节点:4d7df92d8b76e950e12d49d82e997d8f69443655
输入插槽来源id,也就是6380的id:8d48609b3cd273d4e22e4e6dfe297f79a4c18b44
输入done,开始转移

输入yes
![]()
查看集群信息,可以看到6380节点已经没有插槽了。

2、使用redis-trib.rb删除节点
./redis-trib.rb del-node 127.0.0.1:6380 8d48609b3cd273d4e22e4e6dfe297f79a4c18b44
![]()
查看集群信息,可以看到已经没有6380这个节点了。
![]()
4.8 故障转移
如果集群中的某一节点宕机会出现什么状况?我们这里假设6381宕机。

我们尝试连接下集群,并且查看集群信息,发现6381的节点断开连接:
![]()
我们尝试执行set命令,结果发现无法执行:

集群宕机了。
4.9 故障机制
- 集群中的每个节点都会定期的向其它节点发送PING命令,并且通过有没有收到回复判断目标节点是否下线;
- 集群中每一秒就会随机选择5个节点,然后选择其中最久没有响应的节点放PING命令;
- 如果一定时间内目标节点都没有响应,那么该节点就认为目标节点疑似下线;
- 当集群中的节点超过半数认为该目标节点疑似下线,那么该节点就会被标记为下线;
- 当集群中的任何一个节点下线,就会导致插槽区有空档,不完整,那么该集群将不可用;
- 如何解决上述问题?
- 在Redis集群中可以使用主从模式实现某一个节点的高可用
- 当该节点(master)宕机后,集群会将该节点的从数据库(slave)转变为(master)继续完成集群服务;
4.10 集群中的主从复制
1.需要启动6个redis实例,分别是:
6379(主) 6479(从)
6380(主) 6480(从)
6381(主) 6481(从)
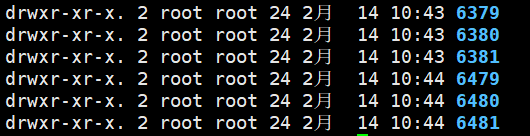
启动redis实例:
cd 6379/ && redis-server ./redis.conf && cd ..
cd 6380/ && redis-server ./redis.conf && cd ..
cd 6381/ && redis-server ./redis.conf && cd ..
cd 6479/ && redis-server ./redis.conf && cd ..
cd 6480/ && redis-server ./redis.conf && cd ..
cd 6481/ && redis-server ./redis.conf && cd ..

创建集群,指定了从库数量为1,创建顺序为主库(3个)、从库(3个):
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6479 127.0.0.1:6480 127.0.0.1:6481

创建成功!查看集群信息:

2.测试

查看下6480的从库数据:

看到从6480查看数据也是被重定向到6380.
说明集群一切运行OK!
3.测试集群中slave节点宕机
我们将6480节点kill掉,查看情况。

查看集群情况:

发现6480节点不可用。
那么整个集群可用吗?
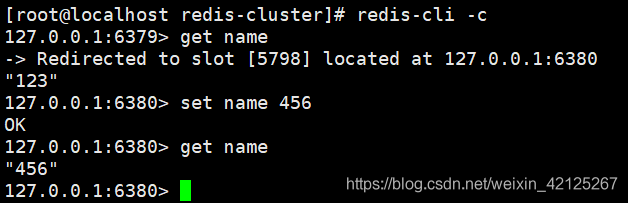
发现集群可用,可见从数据库宕机不会影响集群正常服务。
恢复6480服务:
测试6480中的数据:

看到已经更新成最新数据。
4.测试集群中master宕机
假设6381宕机:

查看集群情况:

6381失效不可用
6481节点从slave变成master
测试集群是否可用:

集群可用。
恢复节点6381

查看集群:

6381已经变成从节点了。
4. 使用集群需要注意的事项
多键的命令操作(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误。
集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误。
参考资料:Redis设计与实践(黄健宏)著 以及别人分享的资料。