Python网络爬虫基础及Requests库入门
Robots协议
网络爬虫的问题
在讲python网络爬虫之前,先来看看网络爬虫的一些问题以及robots协议。首先python爬虫功能主要使用的库有Requests库和Scrapy库。他们的区别如下:

正常情况下Web服务器默认接收人类访问,受限于编写水平和目的,网络爬虫将会带来一些问题:
1、性能骚扰:为Web服务器带来巨大的资源开销;
2、法律风险:服务器上的数据有产权归属网络爬虫获取数据后牟利将带来法律风险;
3、隐私泄露:网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。
网络爬虫的限制
1、来源审查:判断User‐Agent进行限制。检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问。
2、发布公告:Robots协议。告知所有爬虫网站的爬取策略,要求爬虫遵守。
Robots协议:Robots Exclusion Standard,网络爬虫排除标准。作用:网站告知网络爬虫哪些页面可以抓取,哪些不行。形式:在网站根目录下的robots.txt文件。
例如下面一些真实的robots协议文件:
http://www.baidu.com/robots.txt
http://news.sina.com.cn/robots.txt
http://www.qq.com/robots.txt
http://www.moe.edu.cn/robots.txt (页面不存在,表示带网站没有robots协议,所以它对爬虫默认没有任何限制)。
我们访问http://www.jd.com/robots.txt,可以得到如下的内容:
User‐agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User‐agent: EtaoSpider
Disallow: /
User‐agent: HuihuiSpider
Disallow: /
User‐agent: GwdangSpider
Disallow: /
User‐agent: WochachaSpider
Disallow: /
Robots协议基本语法:
# 注释,*代表所有,/代表根目录
User‐agent: *
Disallow: /
那么在实际的应用中,我们该如何使用robots协议呢?网络爬虫首先应该自动或人工识别robots.txt,再进行内容爬取。需要注意的是:robots协议的约束性:Robots协议是建议但非约束性,网络爬虫可以不遵守,但可能存在法律风险。下面的使用原则可以参考:
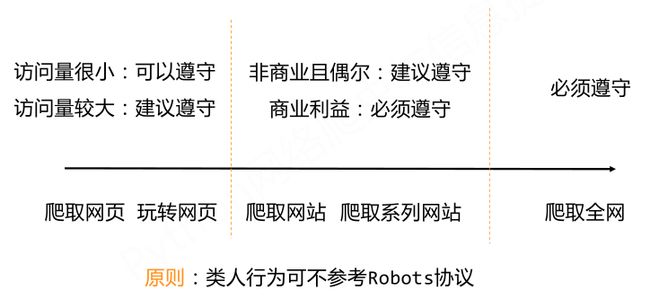
Http协议
我们要进行网络内容的获取,必须首先对HTTP协议有一个简单的了解。HTTP,Hypertext Transfer Protocol,超文本传输协议。HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]。
host: 合法的Internet主机域名或IP地址;
port: 端口号,缺省端口为80;
path: 请求资源的路径。
HTTP URL实例:
http://www.bit.edu.cn
http://220.181.111.188/duty
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源的操作主要有如下几个方法:
GET:请求获取URL位置的资源;
HEAD:请求获取URL位置资源的响应消息报告,即获得该资源的头部信息;
POST:请求向URL位置的资源后附加新的数据;
PUT:请求向URL位置存储一个资源,覆盖原URL位置的资源;
PATCH:请求局部更新URL位置的资源,即改变该处资源的部分内容;
DELETE:请求删除URL位置存储的资源。
其中PATCH和PUT的区别需要注意:假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段。现在的需求是:用户修改了UserName,其他字段不变。
1、采用PATCH,仅向URL提交UserName的局部更新请求;
2、采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除。
因此PATCH的最主要好处:节省网络带宽。
关于HTTP协议更加详细的信息:HTTP协议详解
Requests库入门
首先Requests库的安装使用python自带的工具pip即可:pip install requests。
pip工具在python的:D:\ProgramFiles (x86)\Python36\Scripts目录下。
Requests库基于Http协议实现,可以很方便的实现http对url的各种请求,同时可以很方便得处理http的返回结果。因此Requests库的功能基本上和Http的操作对应。如下表是Requests库的7个主要方法。
Requests库的7个主要方法
| 方法 |
说明 |
| requests.request() |
构造一个请求,支撑以下各方法的基础方法 |
| requests.get() |
获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() |
获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() |
向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() |
向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() |
向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() |
向HTML页面提交删除请求,对应于HTTP的DELETE |
上述的7个方法中除了requests.request()方法,其余六个都和HTTP协议的操作方法对于,而request()方法正是其它6个方法的基础,其他方法都调用了request()方法来具体实现。所以首先来看看request()方法:
requests.request(method, url,**kwargs)
1、method:请求方式,对应get/put/post等7种;
2、url:拟获取页面的url链接;
3、**kwargs:控制访问的参数,共13个。
**kwargs: 控制访问的参数,均为可选项,下面逐个介绍:
(1)、Params:字典或字节序列,作为参数增加到url中。
kv = {'key1': 'value1', 'key2': 'value2'}
r = requests.request('GET', 'http://python123.io/ws', params=kv)
print(r.url)
http://python123.io/ws?key1=value1&key2=value2
(2)、data:字典、字节序列或文件对象,作为Request的内容。
kv = {'key1': 'value1', 'key2': 'value2'}
r = requests.request('POST', 'http://python123.io/ws', data=kv)
body = '主体内容'
r = requests.request('POST', 'http://python123.io/ws',data=body)
(3)、json:JSON格式的数据,作为Request的内容。
kv = {'key1': 'value1'}
r = requests.request('POST', 'http://python123.io/ws', json=kv)
(4)、headers:字典,HTTP定制头。
hd = {'user‐agent':'Chrome/10'}
r = requests.request('POST', 'http://python123.io/ws',headers=hd)
(5)、files:字典类型,传输文件。
fs = {'file': open('data.xls', 'rb')}
r = requests.request('POST', 'http://python123.io/ws', files=fs)
(6)、timeout:设定超时时间,秒为单位。
r = requests.request('GET', 'http://www.baidu.com', timeout=10)
(7)、proxies:字典类型,设定访问代理服务器,可以增加登录认证。
pxs = { 'http': 'http://user:[email protected]:1234' 'https': 'https://10.10.10.1:4321' }
r = requests.request('GET', 'http://www.baidu.com', proxies=pxs)
(8)、cookies:字典或CookieJar,Request中的cookie。
(9)、auth:元组,支持HTTP认证功能。
(10)、allow_redirects:True/False,默认为True,重定向开关。
(11)、stream:True/False,默认为True,获取内容立即下载开关。
(12)、verify:True/False,默认为True,认证SSL证书开关。
(13)、cert:本地SSL证书路径。
可以简单理解Requests库中的其他方法,其参数为url和**kwargs,其意义和request方法完全一样。其中具体的方法可能会将kwargs中常用的参数拿出来单独最为一个参数,例如:requests.put(url,data=None, **kwargs)。在具体使用中,由于13个**kwargs参数都是可选的,所以具体给值的时候要将参数名称带上,例如timeout=10。
Response对象
首先我们来看一个小程序:
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
r = requests.get("http://www.baidu.com");
# 打印Http协议返回的状态码
print(r.status_code);
# Response对象包含服务器返回的所有信息,也包含请求的Request信息
print(type(r));
print(r.headers);程序输出的内容如下:
200
{'Server': 'bfe/1.0.8.18', 'Date':'Fri, 13 Oct 2017 09:51:10 GMT', 'Content-Type': 'text/html', 'Last-Modified':'Mon, 23 Jan 2017 13:27:36 GMT', 'Transfer-Encoding': 'chunked', 'Connection':'Keep-Alive', 'Cache-Control': 'private, no-cache, no-store, proxy-revalidate,no-transform', 'Pragma': 'no-cache', 'Set-Cookie': 'BDORZ=27315; max-age=86400;domain=.baidu.com; path=/', 'Content-Encoding': 'gzip'} 从上面的代码中可以看到requests.get()方法返回的类型是:Response对象。可以这样理解Request库中的方法是构造一个向服务器请求资源的Request对象,而方法的返回就是一个包含服务器资源的Response对象。Response对象包含爬虫返回的内容, Response对象包含服务器返回的所有信息,也包含请求的Request信息。
Response对象的属性
| 属性 |
说明 |
| r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text |
HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding |
从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content |
HTTP响应内容的二进制形式 |
理解Response编码
看下面的例子:
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
r = requests.get("http://www.baidu.com");
# 打印Http协议返回的状态码
print(r.status_code);
# 从HTTP header中猜测的响应内容编码方式
print(r.encoding);
# 输出网页的内容
print(r.text);
# 根据网页内容分析出的编码方式,可以看作是r.encoding的备选
print(r.apparent_encoding);
r.encoding = "utf-8";
# r.encoding = r.apparent_encoding
# 输出网页的内容
print(r.text);程序结果:
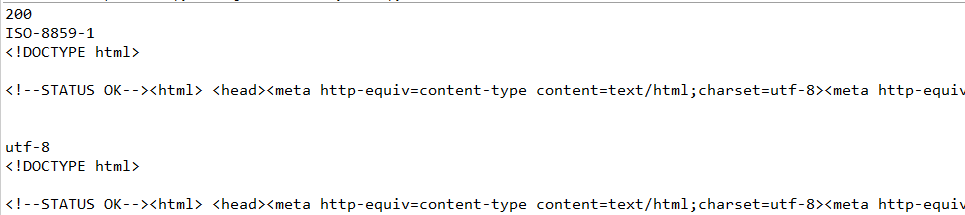
从上面的结果可以看出,我们直接输出get方法返回的内容会出现乱码现象。那是因为r.text是以r.encoding来编码来显示网页内容的,r.encoding:从HTTP header中猜测的响应内容编码方式,如果header中不存在charset,则认为编码为ISO‐8859‐1。所以这里的编码方法不一样,导致了乱码。r.apparent_encoding:根据网页内容分析出的编码方式,将r.encoding修改为utf-8编码,或者直接修改为r.apparent_encoding,即可以正确显示内容。或者可以使用content返回的二进制内容,对其进行编码:response.content.decode("utf-8"),所以这样也可以解决乱码问题。
Request库的异常处理
网络连接有风险,异常处理很重要。从上面的例子我们可以看到get方法返回的Response对象有status_code属性,该属性表示HTTP请求的状态。而HTTP请求并不一定都是成功的。常见的HTTP请求状态码有如下一些:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
针对不同的返回状态,Requests库也定义了一些相应的异常。
| 异常 |
说明 |
| requests.ConnectionError |
网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError |
HTTP错误异常 |
| requests.URLRequired |
URL缺失异常 |
| requests.TooManyRedirects |
超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout |
连接远程服务器超时异常 |
| requests.Timeout |
请求URL超时,产生超时异常 |
所以在使用Requests库方法时,需要首先判断其返回的Response的状态,即只有r.status_code的值为200时才能进行后面的一系列操作。为了简便操作,Response对象中r.raise_for_status()在方法内部判断r.status_code是否等于200,不需要增加额外的if语句,该语句便于利用try‐except进行异常处理。raise_for_status()方法:如果状态码不是200,则产生异常 requests.HTTPError。所以一般通用的网络爬虫代码框架如下:
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30);
r.raise_for_status(); # 如果状态码不是200,则产生异常 requests.HTTPError。
r.encoding = r.apparent_encoding
return r.text;
except:
return "发生异常";
if__name__ == "__main__":
# 正常爬取
url = "http://www.baidu.com";
print(getHtmlText(url));
# 发生异常
url1 = "www.baidu.com";
print(getHtmlText(url1));爬虫小实例
1、实例1:京东商品页面的爬取
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30);
r.raise_for_status(); # 如果状态码不是200,则产生异常 requests.HTTPError。
r.encoding = r.apparent_encoding
return r.text[:1000];
except:
return "发生异常";
if__name__ == "__main__":
url = "https://item.jd.com/2967929.html";
print(getHtmlText(url));2、实例2:亚马逊商品页面的爬取
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30);
r.raise_for_status(); # 如果状态码不是200,则产生异常 requests.HTTPError。
r.encoding = r.apparent_encoding
return r.text[:1000];
except:
return "发生异常";
if__name__ == "__main__":
# 这是一个有效的亚马逊商品链接,但是爬取的时候发生异常
# url ="https://www.amazon.cn/gp/product/B01M8L5Z3Y";
# print(getHtmlText(url));
# 发生异常的原因在于亚马逊会检测 HTTP请求的头部,来判断是否是爬虫,所以我们需要通过修改HTTP请求的头部
try:
kv = {'user-agent':'Mozilla/5.0'}; # 告诉服务器,其实我是一个浏览器的访问
r = requests.get("https://www.amazon.cn/gp/product/B01M8L5Z3Y", headers=kv);
r.raise_for_status(); # 如果状态码不是200,则产生异常 requests.HTTPError。
r.encoding = r.apparent_encoding
print(r.text[:]);
except:
print("发生异常");3、实例3:百度/360搜索关键字提交
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
if__name__ == "__main__":
# 百度的关键词接口:http://www.baidu.com/s?wd=keyword
# 360的关键词接口:http://www.so.com/s?q=keyword
keyword = 'python';
try:
kv = {'wd':keyword};
#params参数:作为参数增加到url中
r = requests.get("http://www.baidu.com/s", params=kv);
print(r.url);
r.raise_for_status(); # 如果状态码不是200,则产生异常 requests.HTTPError。
r.encoding = r.apparent_encoding
print(r.text[:]);
except:
print("发生异常");
try:
kv = {'q':keyword};
#params参数:作为参数增加到url中
r1 = requests.get("http://www.so.com/s", params=kv);
print(r1.url);
r1.raise_for_status(); # 如果状态码不是200,则产生异常 requests.HTTPError。
r1.encoding = r1.apparent_encoding
print(r1.text[:]);
except:
print("发生异常");4、实例4:网络图片的爬取和存储
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
importos
if__name__ == "__main__":
# 一个图片的url:http://image.nationalgeographic.com.cn/2017/1009/20171009021008825.jpg,将它爬取下来
url = "http://image.nationalgeographic.com.cn/2017/1009/20171009021008825.jpg";
path = url.split("/")[-1]; #保存在当前目录下
try:
if notos.path.exists(path):
r = requests.get(url);
with open(path, 'wb')as f:
f.write(r.content);
f.close();
print("文件保存成功");
else:
print("文件已经存在");
except:
print("爬取失败");5、实例5:IP地址归属地的自动查询
#coding=utf-8
'''
Created on 2017年10月13日
@author: Administrator
'''
importrequests
if__name__ == "__main__":
# 一个查询IP地址归属的url
url = "http://www.ip138.com/ips138.asp?ip=";
try:
r = requests.get(url+"202.204.80.112");
r.raise_for_status();
r.encoding = r.apparent_encoding;
print(r.text);
except:
print("爬取失败");