百度Apollo系统学习-Cyber RT 调度
百度Apollo系统学习-Cyber RT 调度
- 简介
- Component回顾与深入探究
-
- 继承关系
- ComponentBase
- Node
- Component & TimerComponent
- Component
- 几个基本概念
-
- Croutine & Task
- RoutineFactory
- Processor
- Scheduler
- 两种策略
-
- ProcessorContext
- SchedulerClassic
- SchedulerChoreography
- 注意点
- 跟随scheduler_classic探寻全部流程
-
- 总结
- 最后照例再上两张盗图(来自参考链接1)
- 参考链接
简介
在上一篇文章中我们介绍了cyber里如何注册加载模块,同时也找到了cyber的程序入口。现在我们就会想问,这些功能组件加载进来以后它们又该怎么运行呢,cyber是怎么安排它们有序工作的呢?这篇文章就带大家来解答这些问题。
Component回顾与深入探究
我们虽然在注册启动模块的文章中大概了解到Component是构成module的组件,但并不清楚其内部的具体结构,现在我们就仔细看一看Component到底是什么。以下部分内容的具体解析见参考链接。
继承关系
Component的基类是ComponentBase(位于cyber/component/component_base.h),它有两个子类Component和TimerComponent,用户定义的组件都是继承这两个子类,然后需要实现其中的Init() & Proc()函数。
ComponentBase
ComponentBase是组件的基类,组件类的所有成员变量都在此进行了定义,所以我们看一下每个成员。
- std::atomic is_shutdown_ = {false};记录了该组件是否已经停止
- std::shared_ptr node_ = nullptr;Node节点,下面会具体解释
- std::string config_file_path_ = “”;记录组件的配置文件,在不同
module对应的dag文件中每个components or timer_components字段里(注意,并不是modules/xxx/conf文件夹里的.conf或.pb.txt),初始化组件时传入的参数就是这个。 - std::vector
cyber/node/reader_base)
Node
每个Component都有一个Node,每个Node负责创建Reader, Writer, Service, Client来帮该组件获取信息或传达信息。每个Node保存了它的名字和名字空间,一个存有channel对应的Reader的map以及一个NodeChannelImpl和一个NodeServiceImpl(创建以上4种东西的创建器)。有关Reader等具体通信相关的类会在之后的博客中在详细介绍,现在只需要知道Node创建的这几个实例都是用来通信的。
Component & TimerComponent
TimerComponent是通过定时调用它的Proc来运行的,TimerComponent运行时会创建task_pool_size(scheduler成员,可在配置文件中配置,具体见下文)数量的协程,协程名字为/internal/task+[number](代码位于cyber/task/task_manager.cc),相关任务是通过TaskManager::Enqueue加入的,这里面涉及的内容太多且和本次主题不相关,后面如果有必要我会再出一篇详解一下Timer机制。接下去我们关注以Component为主。
Component
Tip:以下内容在阅读代码时会碰到Lambda函数的使用,建议读者可以先学习一下c++中Lambda函数再阅读源码。
Component的Initialize() & Process()都最终会调用到子类实现的Init() & Proc()函数。Initialize函数- 每个
Component可以读取0-4个不同的消息种类(每种对应一个不同的Component,但如果是0那就是完全不读取消息,对于这个情况cyber也没有调度,甚至连Process函数都没有,可见运行比较特殊,估计是运行一次就结束的那种),在初始化某种组件的时候,会先初始化Node然后读入配置文件,如果发现配置文件里设置的reader数量少于该种类Component定义的接受消息个数的话,就会报错。 - 接下去会查看当前运行是在现实环境还是虚拟环境并读取配置文件里定义的
reader的各种设置(channel名字,qos策略,pending队列长度),然后根据这些配置创建相应的Reader并放入组件的阅读器队列中。 - 如果是现实环境,创建的
Reader和Writer都是普通的,如果是虚拟环境最终创建的会是IntraReader和IntraWriter(在cyber/blocker/中),并且虚拟环境下,调度器也是不会使用的,所以接下去我们也主要看现实环境。 - 现实环境下,
Initialize函数接下来就会获取调度器实例,创建回调函数,设置数据获取器(data::DataVisitor见通信章节博客),然后以该回调函数以及数据获取器为参数创建协程工厂,最后创建Task。
- 每个
几个基本概念
Croutine & Task
Croutine(协程)就是可以人为暂停执行的函数,cyber中的croutine位于cyber/croutine/croutine.h。在cyber中,task可以和croutine划上等号,task是协程更形象的表述。
Croutine主要的成员有自己的idid_名字name_(名字就是Component创建task时CreateTask()指定的组件的node_的名字,id和name一一对应),实际运行的函数RoutineFunc func_,当前状态RoutineState state_,上下文std::shared_ptr,对应的Processor的idint processor_id(这个只有choreography模式中绑定processor才会用到),优先级priority_,组名group_name_,还有两个线程变量(thread_local关键词修饰,表示每个线程独立拥有的变量实例,在线程开始时生成,结束时销毁)*current_routine_ & *main_stack_。
cyber用汇编实现了一套切换上下文的方法(位于cyber/croutine/detail/swap_*.S),在协程被挂起时就会被切换上下文并设置状态。
凡是调用到Scheduler::CreateTask()的都会创建协程,其中比较常用的是,每个Component::Proc(主要涉及DataVisitor),每个Reader,需要注意Writer是不会创建task的。
RoutineFactory
协程工厂实际上就是把DataVisitor和Component::Process()即Proc()进行一个封装,将它们包成一个匿名函数(RoutineFactory::create_routine)。该函数就是用DataVisitor去尝试拿数据,如果拿到了就传入Process()运行,最后设置当前RoutineState为Ready;如果没拿到就直接调用CRoutine::Yield()挂起。
该函数其实就是Task实际执行的协程代码。
Processor
位于cyber/scheduler/processor.h,它有一个Thread以及一个ProcessorContext。这个结构实际上就是一个线程,它承载了多个协程。在配置文件中的一个group对应了多个Processor(数量等于配置文件中的processor_num),也就是说Processor就是某个group中所有task(协程)的实际运行载体,类似于工作节点。
Processor::Run()就是不停地从ProcessorContext中拿下一个状态是READY的任务来跑(SwapContext())。
Scheduler
调度器(位于cyber/scheduler/scheduler.h),负责把Task发放到协程上运行,有两个子类SchedulerClassic & SchedulerChoreography。
- 调度器保存了一个map记录id和协程的对应关系
id_cr_,两个数组,一个是记录所有ProcessorContext的pctxs_,一个是记录所有Processor的processors_,还有一个记录特殊线程配置的mapinner_thr_confs_(这其实就是系统的进程,不属于某个module,最典型的就是cyber/init.cc中创建的日志线程async_log)。 Scheduler::CreateTask()实际上就是创建协程(使用协程工厂里封装的函数为协程主体),然后将该协程调用Scheduler::DispatchTask()发放这些任务。然后给DataVisitor注册一个数据到来后的回调函数,当收到消息后调用NotifyProcessor(),其最终会调用到XxxContext::Notify()来触发cpu上的线程Processor::Run运行一次。- 层次结构:每次mainboard启动有一个进程,那个进程会创建出n个线程,n这个值通过在调度器配置文件中每个group的
processo_num字段来指定(所有之和),默认情况下,使用的classic调度器会创建16个线程(根据conf/cyber.pb.conf),这些线程全在一个组default_grp中。
两种策略
现在我们通过两种调度策略来理解运行过程,两种策略对应了Scheduler的两个子类。每次运行整个cyber,都会先从配置文件conf/xx_sched.conf中确定使用哪个子类,然后实例化该子类作为此次运行的调度器(只会创建一次,如果存在则直接返回)。
ProcessorContext
它有两个子类ClassicContext & ChoreographyContext分别对应两种策略。
- ClassicContext
需要注意它里面有几个所有上下文共享的static变量,其中的CR_GROUP cr_group_这张map保存了group_name对应的多条优先级等待的协程队列。每个group对应多条不同优先级的队列,每条队列保存了某个优先级的所有协程。
ClassicContext::NextRoutine()有两级索引,会按照优先级从高到低的顺序取出队列,然后从队列中按顺序返回协程。(这里感觉如果只有一个协程,那么会导致高优先级永远抢占低优先级,TODO) - ChoreographyContext
它的成员主要就是一个condition_variable变量和一个multimapcr_queue_按优先级顺序保存协程。
ChoreographyContext::NextRoutine()会按队列里的优先级顺序返回协程。
SchedulerClassic
- 成员多了一张用名字索引的保存
ClassicTask的map(即保存所有的task对应的配置)cr_confs_以及一个ClassicConf classic_conf_(代码位于cyber/proto/classic_conf.proto)。ClassicTask有一个名字,一个优先级和一个group_name。ClassicConf保存了conf/xx.conf中每个group的配置,每个group都会有名字,分配的Processor的数量processor_num,亲和度策略affinity(亲和度由pthread_setaffinity_np()设置,作用是指定线程在哪些个cpu上运行;总共有两个策略:1to1表示一个线程对应一个cpu,range表示一个线程对应一组cpu),可用cpu的编号cpuset,cpu上线程切换的策略processor_policy,Processor的优先级processor_prio,以及多个ClassicTask。 - 实例化时,做的工作是读入配置并创建线程
Processor及其ClassicContext。- 实例化时,它首先将配置中的threads的配置放入
Scheduler::inner_thr_confs_,然后判断有没有设置process_level_cpuset,如果有则设置线程的亲和度为设置的这几个cpu(即绑定自身只能在这几个cpu上运行)。接下来,读取配置里的classic_conf(没有的话就用默认配置),将配置里的每个task的配置放入SchedulerClassic::cr_confs_。最后调用SchedulerClassic::CreateProcessor()。 SchedulerClassic::CreateProcessor()先设置task_pool_size_为第一个group的processor_num,然后创建processor_num个Processor以及其对应的ClassicContext。创建的时候,会设置该Processor里的线程的cpu亲和度和调度策略,并调用Processor::BindContext()给每个Processor绑定一个ClassicContext(绑定时调用了std::call_once把Processor::Run()运行了起来),最后把创建的这两个实例分别加入pctxs & processors_中。
- 实例化时,它首先将配置中的threads的配置放入
- 在
Scheduler::CreateTask()时,主要是调用了DispatchTask()来分配协程,然后给DataVisitor注册一个数据到来后的回调函数,该回调函数调用了Scheduler::NotifyProcessor()。DispatchTask()函数首先把这个新协程放入保存的mapScheduler::id_cr_中,然后根据名字查找保存的cr_confs_中是否有该task对应的策略,如果有就根据策略设置该协程的优先级和group_name。最后往ClassicContext中的全局变量cr_group_中对应该协程的group_name和优先级的队列中加入该协程。最后调用ClassicContext::Notify()来通知。ClassicContext::Notify()函数就是调用了对应group_name的condition_variable的notify_one()来唤醒等待该group的condition_variable的线程。注意这里是线程而不是协程,因为ClassicContext::Wait()是在Processor::Run()函数中被调用的,也就是说这里唤醒的是Processor::Run,它随后才会去拿ClassicContext中不同优先级的队列中的协程来运行。SchedulerClassic::NotifyProcessor()先会通过一个方法标记协程READY(不是直接设置,具体过程请自行阅读代码),最后就是调用了一下ClassicContext::Notify()。
SchedulerChoreography
- 成员相比于
SchedulerClassic,cr_confs_没变,而ClassicTask则被展开成了choreography_processor_* & pool_processor_*对应的优先级、亲和度、策略以及cpuset。 - 实例化时
- 前一段直到判断配置文件里的
process_level_cpuset和SchedulerClassic一样,接下去,它会先设置choreography_processor相关的cpu、策略、优先级等等,然后设置pool_processor相关的。最后再在cr_confs_中记录每个task。然后仍然是调用SchedulerChoreography::CreateProcessor()。 SchedulerChoreography::CreateProcessor()和SchedulerClassic类似,只不过它需要额外为pool也创建指定数量的Processor,同时我们看到,给choreography创建的Processor绑定的是ChoreographyContext,而给pool中绑定的则是ClassicContext。由此可见,SchedulerChoreography中的pool实际就是classic式的管理。
- 前一段直到判断配置文件里的
SchedulerChoreography::DispatchTask函数又有什么不同呢?- 首先它也是为当前协程根据配置设置优先级,然后它会去判断该task是否在配置文件中指定了
processor(只有choreography模式的task配置中有该字段),如果指定了就设置该协程的processor_id。然后同样把该协程添加进id_cr_中。 - 接下来首先将指定processor的协程加入对应的
ChoreographyContext的multimap中(按优先级顺序)。 - 然后将其余没有指定processor的协程设置一个默认的group,再将它们按照classic的方式加入全局的
cr_group。
- 首先它也是为当前协程根据配置设置优先级,然后它会去判断该task是否在配置文件中指定了
SchedulerChoreography::NotifyProcessor- 依然是先标记,然后如果该协程有绑定processor,则直接调用该
Processor对应的ChoreographyContext的condition_variable的notify_one来唤醒一个线程。如果没绑定则和classic的过程一样。
- 依然是先标记,然后如果该协程有绑定processor,则直接调用该
注意点
- 如果某次运行无法找到对应的配置文件,那么会默认使用classic模式并且将所有task都放在默认的一个group里,所有组参数也是默认的
- 如果某个task没有出现在配置文件中,那么在classic模式下,它会被放入配置文件中第一个group里,优先级为默认值;在choreography模式下,这些task和那些虽然有配置但指定的
processor_id值超出了proc_num的task都会被放入pool中进行调度。
跟随scheduler_classic探寻全部流程
据有些同学反馈,希望能见到实际运行时的流程,所以这里结合实际运行流程来看一看scheduler_classic的过程,可以结合前文中的解析来看。(笔者也准备再更新一期cyber实操教程,这里部分内容会放入实操篇)。言归正传下面开始:
- Scheduler是针对一个mainboard的,在mainboard启动一组dag(视作module)时会在-p参数中指定读取的scheduler配置文件名(在
cyber/conf/xxx.conf)。在启动过程中,总共读了两次该文件:第一次读配置文件中的policy,决定是用classic还是choreography;第二次是在SchedulerXxx的实例化函数中读相应的classic_conf或choreography_conf。 - 在
SchedulerClassic::SchedulerClassic()中第二次读,这次会具体把配置读出来,下面我们来看看都是些什么(如果没有配置文件以下这些都会被设置为默认值,默认值散布在cyber.pb.conf和global data中。。。)。threads字段,设置inner thread的调度策略,典型的就是cyber初始化时的日志进程async_log和TimerComponent的timer。这里需要注意,这些线程是不会创建协程的,它们直接创建了线程并且根据配置来设置cpu set、调度策略(OS层面非cyber的协程层面)和优先级等等,所以它们的调度是系统直接负责的process_level_cpuset限制了只有那些cpu可以用- 读取
classic_conf字段填入cr_confs_并设置task.group为配置中的group.name(注意区分配置中的group.name和mainboard的参数process_group的区别,process_group仅仅用来找到该配置文件,后面就没用了),索引为配置中task.name - 对于每一个配置中的
group,有以下几个配置字段:name,组名group_nameprocessor_num:proc_num=task_pool_size(task_pool_size在classic模式用于TimerComponent),这个是线程数量,也就是说一个group会有这么多个线程,如果有多个group,task_pool_size等于第一个group的proc_num,默认是default_proc_numaffinity:两个策略:1to1表示一个线程对应一个cpu,range表示一个线程对应一组cpu,通过SetSchedAffinity函数设置。如果是1to1需要注意,它会从限定的那几个cpu里一个个为组里的processor_num个线程分配,但如果不够那就完全不管了(没有报错信息,多出来的那个线程也不会被限制cpu,所以一定要注意不能超)processor_policy&processor_prio:cpu上线程切换策略以及线程优先级:processor_policy有SCHED_OTHER,SCHED_RR,SCHED_FIFO,具体什么含义请搜pthread_setschedparam,调用这个函数的时候需要制定策略processor_policy以及优先级processor_prio。但需要注意的是这里的SCHED_OTHER不会调用pthread_setschedparam(没必要,因为默认就是它:分时调度策略),而是调用setpriority设置一下优先级processor_prio。这里涉及很多os线程调度的知识,后续有机会可以深入再探究一下,具体对应关系见cyber实操的文章。- 至于每个task的优先级,也是值越大优先级越高,优先级越高的,但这个优先级是协程的优先级,由cyber管理,和系统无关。task如果没有配置,那么会用默认优先级0并且加入第一个group
- task的
name字段如何指定?只要记住每个Component的Proc以及每一个Reader都会创建出协程,所以名字一般为component的名字或是component名字+_channel名字,还有就是TimerComponent的/internel/task[num]
总结
- 配置文件,classic模式有group的概念,choreography模式的task可以指定processor,并且存在一个pool。
- choreography模式实际上就是classic模式额外再加上可以为某些task单独分配processor的功能,并且把所有剩余task合并成一个默认的group。
- classic模式是scheduler的默认模式,具体情况见专栏中的cyber实操部分。
最后照例再上两张盗图(来自参考链接1)
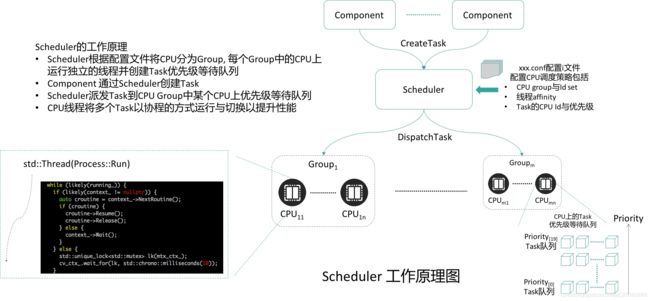
参考链接
【架构分析】Apollo CyberRT Framework分析 - Scheduler调度器
Apollo 3.5 Cyber - Scheduler 模塊
百度Apollo系统学习-Cyber RT 注册启动模块
百度Apollo系统学习-Cyber RT 通信-上层
百度Apollo系统学习-Cyber RT 通信-底层