【数据结构与算法Python描述】——单向线性链表简介、Python实现及应用
文章目录
- 一、单链表介绍
-
- 1. 单链表定义
- 2. 单链表模型
- 3. 单链表ADT
- 4. 单链表实现
-
- (1)结点定义
- (2)异常定义
- (3)ADT实现
-
- a. 链表基本操作
- b. 添加元素操作
- c. 删除元素操作
- (4)单链表完整实现
- 5. 链表操作时间复杂度
- 二、单链表应用
-
- 1. 单链表实现栈
- 2. 单链表实现队列
- 三、总结
通过文章:
- 【数据结构与算法Python描述】——字符串、元组、列表内存模型简介
- 【数据结构与算法Python描述】——列表实现原理深入探究及其常用操作时间复杂度分析
我们深入探究了Python中list类基于数组实现的本质。后续在以下两篇文章:
- 【数据结构与算法Python描述】——栈的Python实现及其简单应用
- 【数据结构与算法Python描述】——队列和双端队列简介及其高效率版本Python实现
我们又通过将list类的实例作为元素存储容器实现了栈、队列、双端队列等基本数据结构的ADT。
虽然Python的list类已经过高度优化了,但是其作为元素存储容器依然有如下显著问题:
- 列表的长度可能大于栈、队列、双端队列中的元素个数;
- 列表底层基于数组实现,其
append(e)和pop(0)操作经摊销后的时间复杂度才是 O ( 1 ) O(1) O(1),这决定了其不适用于对实时性要求较高的场合; - 列表在向其内部单元处插入或删除元素时的代价较大。
基于上述考量,从本文起,我们将学习另外一种数据结构——链表。链表和基于数组实现的列表都可以让元素按某一顺序排列,但二者使用的策略大相径庭:
- 列表代表了一种更加集中式的表示形式,即一片连续的内存空间可以保存多个对象的索引;
- 链表则代表了一种较为分散式的表示形式,链表上的每一个单元称为一个节点(Node),该节点除了引用了元素对象以外,还引用了前/后节点,因此遍历链表就像顺着一条打了很多结的链子捋过去。
一、单链表介绍
1. 单链表定义
单链表是一系列结点的集合,该集合中的每个结点保存了一个对象的引用(关于引用的概念,请见文章Python中变量赋值的本质——“引用”的概念)以及下一个结点的引用,集合中的所有结点以这种方式形成一个线性序列。
2. 单链表模型
对于单链表的模型,可以使用一系列机场之间的关系来类比,如下图所示:假设某商务人士需要从北京大兴机场(代号:PKX)经由上海浦东国际机场(代号:PVG)最终到达深圳宝安机场(代号:SZX),每一个机场都相当于一个结点,每个机场节点既会保存本机场的代号,也会保存下一个机场的结点信息。

3. 单链表ADT
单链表的ADT主要包含下列方法:
| 方法名称 | 功能描述 |
|---|---|
__len__() |
重写__len__(),使得通过len()可以返回单链表的长度 |
__str__() |
重写__str__(),结合使用_traverse()方法使得可以打印单链表实例的无歧义字符串表现形式 |
_traverse() |
遍历整个单链表,这里使用一个生成器函数实现 |
is_empty() |
判断单链表是否为空,如是则返回True |
append(element) |
在单链表尾部插入元素element |
add_first(element) |
在单链表的头部插入元素element |
insert(pos, element) |
在单链表指定位置pos处插入元素element |
remove(element) |
删除第一个匹配的element所在的结点,当链表为空时抛出异常 |
search(element) |
查询单链表是否存在某一包含元素element的结点 |
4. 单链表实现
(1)结点定义
根据上述讨论,为了实现单链表,首先需要将每一个节点通过代码抽象出来。由于一个节点需要保存两部分信息,即对象元素的引用和下一个节点的引用,因此可以通过定义一个节点类_Node并在其中定义self.element和self.next两个实例属性来实现:
class _Node:
"""节点类"""
def __init__(self, element, next):
"""
:param element: 节点代表的对象元素
:param next: 下一个节点
"""
self.element = element
self.next = next
(2)异常定义
由于上述单链表ADT中的删除类操作要求当链表为空时抛出异常,因此类似【数据结构与算法Python描述】——队列和双端队列简介及其高效率版本Python实现需要自定义如下形式的异常类:
class Empty(Exception):
"""尝试对空链表进行删除操作时抛出的异常"""
pass
(3)ADT实现
为具体实现单链表ADT的各个方法,需要在单链表类中定义下列两个实例属性:
_head:保存单链表头节点引用的实例属性,对于非空链表可根据该节点找到链表中的所有其他节点;_size:保存当前单链表元素个数的实例属性。
a. 链表基本操作
__len__():只需返回当前单链表的self._size属性值即可;__str__():请见文章对象的字符串表示形式之repr、__repr__、str、__str__;_traverse():生成器是一种特殊的迭代器,因此请见文章Python中for循环运行机制探究以及可迭代对象、迭代器详解和文章Python中的yield关键字及表达式、生成器、生成器迭代器、生成器表达式详解;search(element):实现方式和_traverse()方法基本一致,即使用一个辅助游标current实现链表的遍历;is_empty():只需判断self._size是否为0或单链表的头节点是否为None即可。
b. 添加元素操作
append(element):对该方法需要留意如果当前单链表为空则需要做特殊处理,其他情况的算法具有一般性:- 首先,将对象元素封装成节点对象;
- 其次,如果此时链表为空,则只需让
self._head指向新创建的节点即可; - 然后,如果此时链表不为空,则需要:
- 先定义一个辅助游标变量
current并使其和self._head指向同一处; - 然后使用辅助游标变量
current移动至链表最后一个节点; - 最后让链表当前最后一个节点的
next域指向新创建的节点并将self._size加1即可。
- 先定义一个辅助游标变量

add_first(element):下列算法具有一般性,即使当前链表为空也适用:- 首先,将对象元素封装成节点对象;
- 然后,让新节点的
next域指向当前头节点; - 最后,让新节点成为新的头节点并将
self._size加1。

insert(pos, element):实现该方法可以采用以下几个步骤:- 首先,将对象元素封装成节点对象;
- 其次,定义并初始化辅助游标
predecessor以及记录游标滑动次数的计算器count; - 然后,使用循环使得游标
predecessor指向当前pos位置的前一个节点处; - 再次,先将新节点后端入链,即新节点的
next域指向当前pos位置处的节点(即predecessor.next指向的节点); - 最后,让新节点前端入链并让
self._size加1。

对于上述方法,可能还会存在以下问题:
- 用户传入的
pos参数可能不是整数; - 用户传入的
pos参数小于等于0或大于最大索引。
针对以上两个可能的问题,可以如此解决:
- 方法的一开始判断
pos是否为整数,如不是则抛出TypeError异常; - 如传入的
pos参数小于等于0则默认调用add_first()方法进行头部元素插入,如传入的pos参数大于最大索引,则默认调用append()方法向链表尾部进行元素插入。
c. 删除元素操作
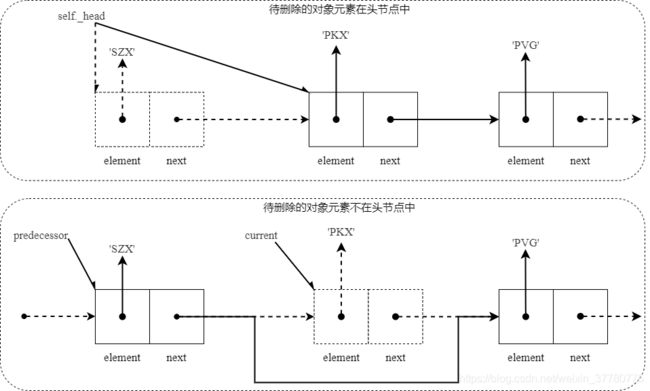
remove(element):为了实现根据对象元素element来删除链表中的节点,直观的一种方式使用两个辅助游标——前序游标predecessor和当前游标current:- 首先,初始化两个辅助游标;
- 其次,从头开始遍历整个链表,判断当前节点的
element域是否是待删除的对象元素:- 如果是且当前节点为头节点,则直接将
self._head指向当前节点next域指向的下一个节点(如果只有一个节点则指向None); - 如果当前节点不是头节点,则直接将前序游标指向的节点和当前游标后一个节点进行链接即可;
- 最后将
self._size减1即可。
- 如果是且当前节点为头节点,则直接将
(4)单链表完整实现
基于上述讨论给出了实现了单链表ADT中所有方法的Singly_Linked_List类:
class _Node:
"""节点类"""
def __init__(self, element, next=None):
"""
:param element: 节点代表的对象元素
:param next: 下一个节点
"""
self.element = element
self.next = next
class Singly_Linked_List:
"""单链表类"""
def __init__(self, head=None):
self._head = head # 初始化头节点
self._size = 0
def __len__(self):
"""
返回当前单链表长度
:return: 单链表长度
"""
return self._size
def __str__(self):
"""
以无歧义的方式返回单链表的字符串表示形式
:return: 单链表的无歧义字符串表示形式
"""
return str(list(self._traverse()))
def _traverse(self):
"""
用于遍历整个单链表的生成器
:return: None
"""
current = self._head # 初始化遍历所需游标
while current is not None:
yield current.element
current = current.next # 移动游标
def search(self, element):
"""
查找当前单链表是否有节点元素为element
:param element: 待查找的元素
:return:
"""
current = self._head # 初始化游标
while current is not None:
if current.element == element:
return True
else:
current = current.next
return False # 若遍历完整个单链表后未找到element,则返回False
def is_empty(self):
"""
判断单链表是否为空
:return: 当前单链表为空时,返回True
"""
# return self._size == 0
return self._head is None
def append(self, element):
"""
向单链表尾部追加一个节点
:param 待追加的元素
:return: None
"""
node = _Node(element) # 为传入的元素对象构造节点
if self.is_empty(): # 处理单链表为空的特殊情况
self._head = node
else:
current = self._head # 初始化遍历所需的游标
while current.next is not None:
current = current.next # 移动游标
current.next = node # 将新节点连接至原尾节点
self._size += 1
def add_first(self, element):
"""
在当前单链表的头部插入节点
:param element: 待插入的元素
:return: None
"""
node = _Node(element) # 将元素封装进节点
node.next = self._head # 先让新节点的next域指向原头节点
self._head = node # 让新节点成为头节点
self._size += 1
def insert(self, pos, element):
"""
向单链表的任意位置插入节点
:param pos: 期望插入节点的位置
:param element: 期望插入的元素
:return: None
"""
if not isinstance(pos, int): # 如果pos不是整数,则抛出异常
raise TypeError('pos应该是整数!')
if pos <= 0: # 如果pos为负整数,默认是在当前单链表头部插入节点
self.add_first(element)
elif pos > (self._size - 1): # 如果pos大于单链表最大索引,默认是在当前单链表尾部插入节点
self.append(element)
else:
node = _Node(element) # 将元素封装为节点
predecessor = self._head # 初始化游标
count = 0
while count < (pos - 1):
predecessor = predecessor.next
count += 1
# 循环结束后,游标指向pos位置前的一个节点
node.next = predecessor.next # 先将新节点和原pos处的节点链接
predecessor.next = node # 再将新节点和(pos - 1)处的节点链接
self._size += 1
def remove(self, element):
"""
删除单链表中含有element的节点
:param element: 期望删除的元素
:return: 被删除的元素
"""
if self.is_empty():
raise Empty("当前链表为空!")
predecessor = None # 初始化指向前继节点的游标
current = self._head # 初始化指向当前节点的游标
while current is not None:
if current.element == element: # 判断是否有包含element的节点
if current == self._head: # 先判断此节点是否为头节点
self._head = current.next
else:
predecessor.next = current.next
self._size -= 1
return current.element # 返回被删除的元素,同时终止循环
else:
# 移动游标
predecessor = current
current = current.next
5. 链表操作时间复杂度
| 链表操作 | 时间复杂度 |
|---|---|
__len__() |
O ( 1 ) O(1) O(1) |
__str__() |
O ( n ) O(n) O(n) |
_traverse() |
O ( n ) O(n) O(n) |
is_empty() |
O ( 1 ) O(1) O(1) |
append(element) |
O ( n ) O(n) O(n) |
add_first(element) |
O ( 1 ) O(1) O(1) |
insert(pos, element) |
O ( p o s − 1 ) O(pos-1) O(pos−1) |
remove(element) |
O ( n ) O(n) O(n) |
search(element) |
O ( n ) O(n) O(n) |
二、单链表应用
1. 单链表实现栈
在文章【数据结构与算法Python描述】——栈的Python实现及其简单应用中,我们通过使用列表作为存储元素的方式实现了栈的所有ADT方法,但由于:
push(element)和pop()操作底层分别使用列表的append()和pop()方法实现;- 列表底层又使用了连续内存序列模型即数组实现;
所以由【数据结构与算法Python描述】——列表实现原理深入探究及其常用操作时间复杂度分析可知,由于有时使用push()和pop()操作需要扩增或缩减底层数组容量以及后续内存拷贝的操作,故使用列表实现栈的push()和pop()方法,其平均时间复杂度才为 O ( 1 ) O(1) O(1)。
因此,下面使用上述单链表重新实现栈的所有ADT方法:
class Empty(Exception):
"""尝试对空栈进行删除操作时抛出的异常"""
pass
class _Node:
"""节点类"""
def __init__(self, element, next=None):
"""
:param element: 节点代表的对象元素
:param next: 节点对象中用于指向下一个节点的实例属性
"""
self.element = element
self.next = next
class LinkedStack:
"""使用单链表实现的栈"""
def __init__(self):
"""创建一个空的栈"""
self._head = None # 初始化头节点
self._size = 0 # 保存栈的元素数量
def __len__(self):
"""
返回栈中当前元素数目
:return: 栈的元素数量
"""
return self._size
def is_empty(self):
"""
判断当前栈是否为空,如是则返回True
:return: 栈是否为空
"""
return self._size == 0
def push(self, element):
"""
:param element:
:return: None
"""
node = _Node(element) # 将元素封装进节点
node.next = self._head # 先让新节点的next域指向原头节点
self._head = node # 让新节点成为头节点
self._size += 1
def top(self):
"""
返回但不删除栈顶元素,当栈为空时抛出异常
:return: 栈顶元素
"""
if self.is_empty():
raise Empty('栈为空!')
return self._head.element # 栈顶元素即为单链表头部元素
def pop(self):
"""
删除并返回栈顶元素,当栈为空时抛出异常
:return: 栈顶元素
"""
if self.is_empty():
raise Empty('栈为空!')
ans = self._head.element
self._head = self._head.next # 使当前头节点的下一个节点作为新的头节点
self._size -= 1
return ans
def main():
stack = LinkedStack()
stack.push(5)
stack.push(3)
print(len(stack)) # 输出为:2
print(stack.pop()) # 输出为:3
print(stack.is_empty()) # 输出为:False
print(stack.pop()) # 输出为:5
print(stack.is_empty()) # 输出为:True
if __name__ == '__main__':
main()
需要说明的是,上述push(element)方法和上述单链表中add_first(element)方法完全一致,而实现pop()方法只要使当前头节点的下一个节点作为新的头节点即可。
通过上述单链表实现的栈ADT各方法,其最坏时间复杂度如下:
| 方法名称 | 时间复杂度 |
|---|---|
stack.push(element) |
O ( 1 ) O(1) O(1) |
stack.pop(element) |
O ( 1 ) O(1) O(1) |
stack.top() |
O ( 1 ) O(1) O(1) |
len(stack) |
O ( 1 ) O(1) O(1) |
stack.is_empty() |
O ( 1 ) O(1) O(1) |
即各方法的最坏时间复杂度均为 O ( 1 ) O(1) O(1),与【数据结构与算法Python描述】——栈的Python实现及其简单应用中的使用列表实现的栈的同名方法相比,没有任何方法的最坏时间复杂度是经过摊销后的结果。
2. 单链表实现队列
在文章【数据结构与算法Python描述】——队列和双端队列简介及其高效率版本Python实现,我们使用列表实现了队列的所有ADT,但是和使用列表实现栈的ADT方法一样,对于使用列表实现的队列,其ADT的部分方法也存在上述提及的类似问题。
基于上述原因,下面给出基于单链表实现的队列,使其所有操作的最坏时间复杂度均为 O ( 1 ) O(1) O(1)。
因为对于队列而言,我们需要对其两端都进行操作,因此这里除了使用实例属性_head保存队头节点引用,使用_size来保存当前队列元素数量外,还额外使用_tail保存队尾节点引用。
下面是使用单链表实现队列所有ADT方法的代码:
class Empty(Exception):
"""尝试对空队列进行删除操作时抛出的异常"""
pass
class _Node:
"""节点类"""
def __init__(self, element, next=None):
"""
:param element: 节点代表的对象元素
:param next: 节点对象中用于指向下一个节点的实例属性
"""
self.element = element
self.next = next
class LinkedQueue:
"""使用单链表保存对象元素实现的队列数据结构"""
def __init__(self):
"""创建一个空队列"""
self._head = None # 初始化头节点
self._tail = None # 初始化尾节点
self._size = 0 # 队列元素个数
def __len__(self):
"""
返回队列中的元素个数
:return: 元素个数
"""
return self._size
def is_empty(self):
"""
如果队列为空则返回True
:return: 队列是否为空的状态
"""
return self._size == 0
def first(self):
"""
返回但不删除队头元素
:return: 队头元素
"""
if self.is_empty():
raise Empty('当前队列为空!')
return self._head.element
def enqueue(self, element):
"""
向队列尾部插入对象元素
:param element: 待插入队列尾部的对象元素
:return: None
"""
node = _Node(element)
if self.is_empty():
self._head = node
else:
self._tail.next = node
self._tail = node # 使新入队尾的元素成为尾节点
self._size += 1
def dequeue(self):
"""
删除并返回队头的节点,并返回其中的对象元素,如此时队列为空则抛出异常
:return: 队头节点的element域
"""
if self.is_empty():
raise Empty('队列为空!')
ans = self._head.element
self._head = self._head.next
self._size -= 1
if self.is_empty(): # 如果执行本次出对操作时队列中仅有一个节点,则此时该节点同时也是尾节点,需对此做处理
self._tail = None
return ans
对于上述代码,有如下几点需要注意:
- 上述
LinkedQueue类中的dequeue()方法和LinkedStack类中的pop()方法类似,即都从单链表的头部删除一个节点,当单链表此时只有一个节点时,该节点既是头节点也是为尾节点。因此,对于LinkedQueue,此时删除队头元素的同时还需要将self._tail设为None; - 对于上述
enqueue()方法,需要注意的是,入队的节点总是最新的尾节点,但是当入队前队列为空时,此时该节点同时也将成为队头节点。
三、总结
至此,回到本文开头提到的使用列表作为元素存储容器实现栈、队列等数据结构的缺陷,使用单链表来保存各个对象元素后:
- 栈和队列所有操作的时间复杂度都是 O ( 1 ) O(1) O(1);
- 栈和队列中的元素数量严格等于单链表所链接的元素数量。