Python网络爬虫 一、requests的用法详解
Python网络爬虫
一、requests的用法详解
什么是网络爬虫?
如何搞笑的获取互联网上的海量数据,是大数据时代的我们面临的重要问题。而爬虫就是解决这些问题而生的。
1.requests的基础知识
requests是用Python语言编写的HTTP库。它比python标准库urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。
2.安装
pip install requests #一句话搞定
3.用法
import requests #导入包
获取豆瓣首页
r =
requests.get('https://www.douba.com/')#r是一个response对象
http协议的请求类型介绍
GET:向特定的资源发出请求
POST:向指定的资源提交数据进行处理请求(例如提交表单或者上传文件)。数据包括在请求体中。
PUT:向指定的资源位置上传最新的内容。
DELETE:请求服务器删除Request-URI所表示的资源。
HEAD:只请求页面的首部。
OPTIONS:允许客户端查看服务器的性能。
r.encoding#编码方式
![]()
r.text#可查看内容,进行解码

r.content#二进制代码,获取图片

进入豆瓣首页之后,搜索‘requests’,可发现网址栏的变化:

’q=‘之后即为搜索内容,因此进行构造网址
dict = {'q':'java'}#构造搜索内容位Java
r.url#查看网址
![]()
可以在请求网址的时候通过构造params传递参数。
当然也可以构造多个参数:
在豆瓣中在书籍中查找java:

可以发现网址栏又多出了
cat = 1001
因此,重新构造dict
dict = {'q':'java','cat':1001}
r.url
![]()
构造成功。
如果需要发送信息,则需要使用post,例如登陆douban.
dict1 = {'user':'longwenhan','password':'1234567'}#构造用户名和登陆密码
w = requests.post('https://www.douban.com',data = dict1)#进行发送,注意在此使用的是data,而不是params.
w.status_code#查看状态
![]()
http状态码补充
.status_code:可以查看请求是否成功
HTTP状态码:
成功(2开头):表示请求已成功被服务起接收、理解、并接受。比如200表示OK.
重定向(3开头):301重定向
请求错误(4开头):代表客户端看起来发生了错误,妨碍了服务器的处理。
服务器错误(5,6开头):服务器在处理请求的过程中有错误或者异常的状态发生。
查看请求头
进入豆瓣网站,点击右键->检查(或者直接按F12),进入network(F5刷新,出现数据):
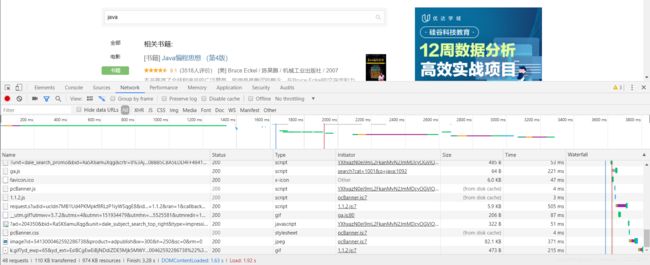
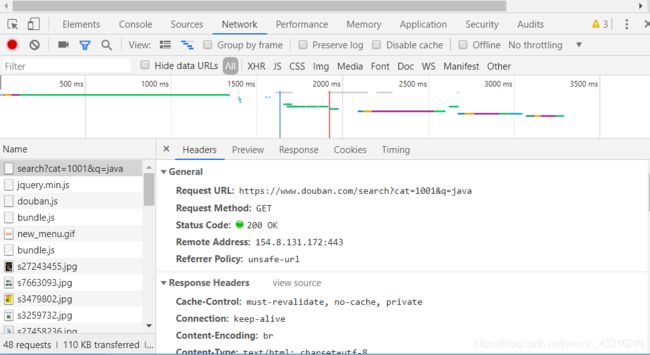
Header为请求头部,很多服务器会通过请求头部来进行判断你是一个机器人还是真正的浏览器。
通过模拟头部进行请求:

复制以上内容。
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}#模拟浏览器头部
注意空格,不然会无法成功。
r = requests.post('http://www.douban.com',headers = header)#重新请求
重定向
r = requests.post('http://www.douban.com')#注意这里为http
当重新观察网址的时候
r.url
![]()
这里已经变成了https.
超时
如果在一次请求的时候,超过多少秒没有回应,可以进行中断。
r = requests.get('http://www.douban.com/',timeout = 3)#超过3秒则自动停止
回话
保持某一状态,保持参数。
s = requests.session()
代理
反爬虫机制对同一ID进行检测,如果一段时间内访问次数过多,则会拒绝访问。因此,可以通过代理ID进行访问。
proxies = {
'https':'120.83.101.19'
}
r = requests.get('http://www.douban.com/',proxies = proxies)
免费的代理地址网站:https://www.xicidaili.com/