再做一次职工离职预测,我有什么新的收获
最近好好的恶补了一下特征工程和机器学习的过程,发现之前自己做的离职预测项目,在特征工程的选择上有一定的主观性,因此决定趁着周末再试着预测一下准确率。
增加更多维度
这次我引入了培训记录、籍贯区域、工作种类、奖惩情况,学历情况相较之前更丰富了特征属性,
![]()
数据转换
数据转换上,将文本转换为更多离散型数值代替
性别:男、女转换为1,0
籍贯区域 按地理区域划分为7个区域
0、未知
1、华北五省二市——北京市、天津市、河北省、河南省、内蒙古自治区、山西省、山东省
2、华东五省一市——上海市、江苏省、江西省、安徽省、浙江省、福建省
3、东北三省——黑龙江省、吉林省、辽宁省
4、西北五省——陕西省、甘肃省、宁夏回族自治区、青海省、新疆维吾尔自治区
5、西南四省一市——四川省、重庆市、贵州省、云南省、西藏自治区
6、华南五省——湖北省、湖南省、广东省、广西省、海南省
7、港澳台及其他
工作种类:从飞行到乘务到机务、航务再到行政、营销最后是勤务外包
定义出五类,分别用5,4,3,2,1代替
学历情况从研究生及以上、本科、大专、专科及以下
分别用4,3,2,1作为替代
数据清洗
简单逻辑异常值
工作年限为负数,仅6名,直接删去

进公司时间缺失或为1900年,一种是用年龄倒推,另一种直接删去

开始分析
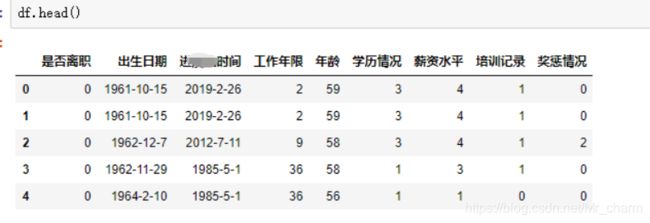
老样子,先倒入处理后的数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import seaborn as sns
%matplotlib inline
df=pd.read_csv('final.csv')
df

删去工号重复值
df.drop_duplicates('工号').head()

看看是否存在空值

共28219人,其中7300为离职人数
先删去和离职不影响的字段
del df['id']
del df['工号']

onehot独热编码
针对离散值的数据,进行向量化,即用0,1来编码
df_one_hot = pd.get_dummies(df, prefix="dep")
df_one_hot.shape
得到(28219, 12092)
特征选择-相关系数法
关于皮尔逊和斯皮尔曼,一个是连续值,一个是含离散值,本次用的是后者
corr=df.corr(method='spearman')
fig=plt.figure(figsize=(10,8))
sns.heatmap(corr,vmax=1,linewidths=0.01,
square=True,annot=True, cmap='viridis',linecolor='white')
plt.title('互相影响度')
plt.show()

删去绝对值|相关性|小于0.1的
del df['性别']
del df['籍贯区域']
del df['工作种类']
模型运用
一、逻辑回归
from sklearn.model_selection import train_test_split
#划分训练集和测试集
X = df_one_hot.drop(['是否离职'], axis=1)
y = df_one_hot['是否离职']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
#逻辑回归模型
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
print(LR.fit(X_train, y_train))
print("训练集准确率: ", LR.score(X_train, y_train))
print("测试集准确率: ", LR.score(X_test, y_test))

from sklearn import metrics
X_train_pred = LR.predict(X_train)
X_test_pred = LR.predict(X_test)
print('训练集混淆矩阵:')
print(metrics.confusion_matrix(y_train, X_train_pred))
print('测试集混淆矩阵:')
print(metrics.confusion_matrix(y_test, X_test_pred))

from sklearn.metrics import classification_report
print('训练集:')
print(classification_report(y_train, X_train_pred))
print('测试集:')
print(classification_report(y_test, X_test_pred))
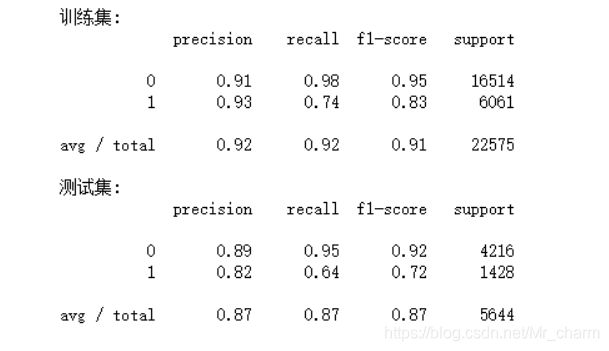
此时,逻辑回归在测试集的查准率为0.82,召回率为0.64,还是有待提高
怎么评估模型
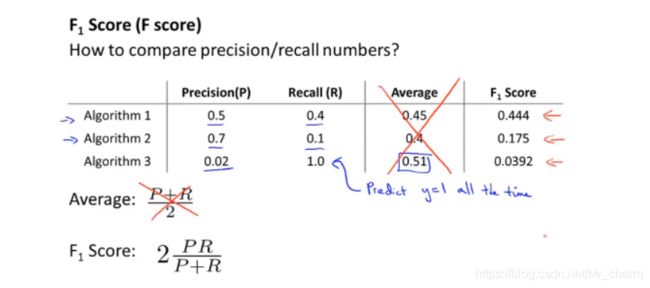
单独看查准率或召回率很难看出,是否模型有优化。
需要利用F值来评估
①原来第一次做这个项目,我的P是0.84,R是0.57
②这次重做得到的P是0.82,R是0.64
计算得到
①F=20.840.57/(0.84+0.57)=0.679
②F=20.820.64/(0.82+0.64)=0.719
说明模型多少有所提升哈哈哈,不过一定还有很多地方需要修正的,
二、朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import cross_val_score
#构建高斯朴素贝叶斯模型
gnb = GaussianNB()
gnb.fit(X_train, y_train)
print("训练集准确率: ", gnb.score(X_train, y_train))
print("测试集准确率: ", gnb.score(X_test, y_test))
X_train_pred =gnb.predict(X_train)
X_test_pred = gnb.predict(X_test)
print('训练集混淆矩阵:')
print(metrics.confusion_matrix(y_train, X_train_pred))
print('测试集混淆矩阵:')
print(metrics.confusion_matrix(y_test, X_test_pred))
print('训练集:')
print(classification_report(y_train, X_train_pred))
print('测试集:')
print(classification_report(y_test, X_test_pred))
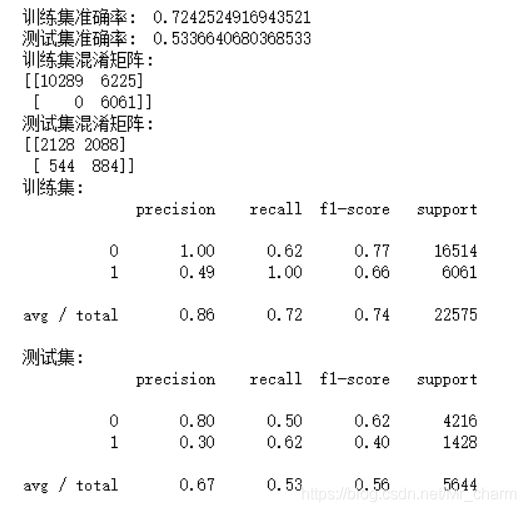
此时,朴素贝叶斯在测试集的表现查准率0.3,召回率0.62,低的不行啊
ROC
from sklearn import metrics
from sklearn.metrics import roc_curve
#将逻辑回归模型和高斯朴素贝叶斯模型预测出的概率均与实际值通过roc_curve比较返回假正率, 真正率, 阈值
lr_fpr, lr_tpr, lr_thresholds = roc_curve(y_test, LR.predict_proba(X_test)[:,1])
gnb_fpr, gnb_tpr, gnb_thresholds = roc_curve(y_test, gnb.predict_proba(X_test)[:,1])
#分别计算这两个模型的auc的值, auc值就是roc曲线下的面积
lr_roc_auc = metrics.auc(lr_fpr, lr_tpr)
gnb_roc_auc = metrics.auc(gnb_fpr, gnb_tpr)
plt.figure(figsize=(8, 5))
plt.plot([0, 1], [0, 1],'--', color='r')
plt.plot(lr_fpr, lr_tpr, label='LogisticRegression(area = %0.2f)' % lr_roc_auc)
plt.plot(gnb_fpr, gnb_tpr, label='GaussianNB(area = %0.2f)' % gnb_roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.title('ROC')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.legend()
plt.show()
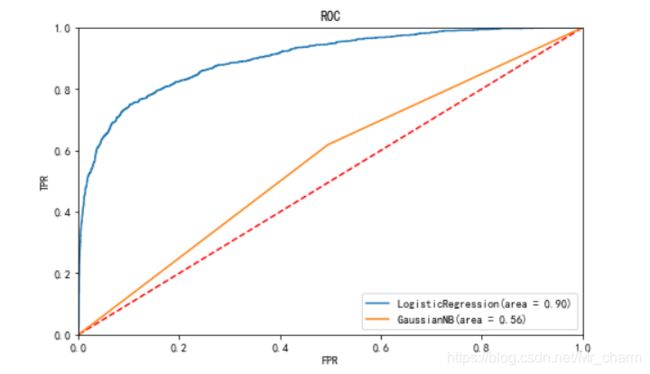
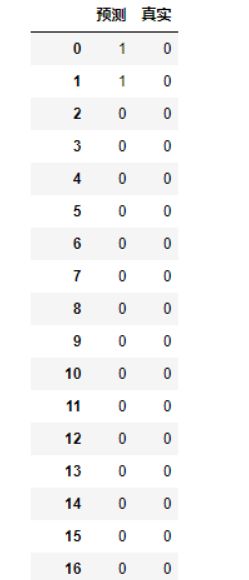
最后预测到实际数据看看
最后选用逻辑回归模型
m=pd.DataFrame(LR.predict(X))
m['预测']=m
del m[0]
m['真实']=df['是否离职']
m