【Flink】批式处理--DataSet API 开发
目录
一、统计单词个数
Flink 批处理程序的一般流程
统计单词个数
将程序打包,提交到 yarn
二、输入数据集 Data Sources
1 基于本地集合的 source(Collection-based-source)
2 基于文件的 source(File-based-source)
2.1、读取本地文件
2.2 读取 HDFS 数据
2.3 读取 CSV 数据
2.4 读取压缩文件
2.5 基于文件的 source(遍历目录)
三、DateSet 的 Transformation
1 map 函数
2 flatMap 函数
3 mapPartition 函数
4 filter
5 reduce
6 reduceGroup
7 Aggregate
8 minBy 和 maxBy
9 distinct 去重
10 Join
11 LeftOuterJoin
12 RightOuterJoin
13 fullOuterJoin
14 cross 交叉操作
15 Union
16 Rebalance
17 First
四、数据输出 Data Sinks
1 基于本地集合的 sink
2 基于文件的 sink
五、广播变量
六、Flink 的分布式缓存
七、Flink Accumulators & Counters
谢谢你长得这么好看还给我点赞
一、统计单词个数
pom文件
1.8
1.8
UTF-8
2.11.2
2.11
2.6.0
1.7.2
2.11
1.4.3
1.2.7
org.scala-lang
scala-library
${scala.version}
org.apache.flink
flink-streaming-scala_2.11
${flink.version}
org.apache.flink
flink-scala_2.11
${flink.version}
org.apache.flink
flink-clients_2.11
${flink.version}
org.apache.flink
flink-table_2.11
${flink.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
xml-apis
xml-apis
mysql
mysql-connector-java
5.1.38
com.alibaba
fastjson
1.2.60
com.jayway.jsonpath
json-path
2.3.0
org.apache.flink
flink-connector-kafka-0.11_2.11
${flink.version}
com.fasterxml.jackson.core
jackson-core
2.9.9
com.fasterxml.jackson.core
jackson-databind
2.9.9.3
com.fasterxml.jackson.module
jackson-module-scala_2.11
2.9.9
redis.clients
jedis
2.7.1
Flink 批处理程序的一般流程
统计单词个数
步骤
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object test01 {
def main(args: Array[String]): Unit = {
//1、创建执行环境
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2、接入数据源
val textDataSet: DataSet[String] = environment.fromCollection (
List("hadoop hive spark", "flink mapreduce hadoop hive", "flume spark spark hive")
)
//3、进行数据处理
//切分
val wordDataSet: DataSet[String] = textDataSet.flatMap(_.split(" "))
//每个单词标记1
val wordAndOneDataSet: DataSet[(String, Int)] = wordDataSet.map(_ -> 1)
//按照单词进行分组
val groupDataSet: GroupedDataSet[(String, Int)] = wordAndOneDataSet.groupBy(0)
//对单词进行聚合
val sumDataSet: AggregateDataSet[(String, Int)] = groupDataSet.sum(1)
//4、数据保存或输出
sumDataSet.writeAsText("./ResultData/BatchWordCount")
sumDataSet.print()
// sumDataSet.writeAsText("hdfs://node01:8020/test/output/BatchWordCount ")
// environment.execute("BatchWordCount")
}
}
将程序打包,提交到 yarn
src/main/scala
src/test/scala
org.apache.maven.plugins
maven-compiler-plugin
2.5.1
${maven.compiler.source}
${maven.compiler.target}
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
-dependencyfile
${project.build.directory}/.scala_dependencies
org.apache.maven.plugins
maven-surefire-plugin
2.18.1
false
true
**/*Test.*
**/*Suite.*
org.apache.maven.plugins
maven-shade-plugin
2.3
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
cn.czxy.batch.BatchWordCount

二、输入数据集 Data Sources
1 基于本地集合的 source(Collection-based-source)
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
object BatchFromCollection {
def main(args: Array[String]): Unit = {
//获取flink执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.api.scala._
//0.用element创建DataSet(fromElements)
val ds0: DataSet[String] = env.fromElements("spark", "flink")
ds0.print()
//1.用Tuple创建DataSet(fromElements)
val ds1: DataSet[(Int, String)] = env.fromElements((1, "spark"), (2, "flink"))
ds1.print()
//2.用Array创建DataSet
val ds2: DataSet[String] = env.fromCollection(Array("spark", "flink"))
ds2.print()
//3.用ArrayBuffer创建DataSet
val ds3: DataSet[String] = env.fromCollection(ArrayBuffer("spark", "flink"))
ds3.print()
//4.用List创建DataSet
val ds4: DataSet[String] = env.fromCollection(List("spark", "flink"))
ds4.print()
//5.用List创建DataSet
val ds5: DataSet[String] = env.fromCollection(ListBuffer("spark", "flink"))
ds5.print()
//6.用Vector创建DataSet
val ds6: DataSet[String] = env.fromCollection(Vector("spark", "flink"))
ds6.print()
//7.用用Queue创建DataSet
val ds7: DataSet[String] = env.fromCollection(mutable.Queue("spark", "flink"))
ds7.print()
//8.用Stack创建DataSet
val ds8: DataSet[String] = env.fromCollection(mutable.Stack("spark", "flink"))
ds8.print()
//9.用Stream创建DataSet(Stream相当于lazy List,避免在中间过程中生成不必要的集合
val ds9: DataSet[String] = env.fromCollection(Stream("spark", "flink"))
ds9.print()
//10.用Seq创建DataSet
val ds10: DataSet[String] = env.fromCollection(Seq("spark", "flink"))
ds10.print()
//11.用Set创建DataSet
val ds11: DataSet[String] = env.fromCollection(Set("spark", "flink"))
ds11.print()
//12.用Iterable创建DataSet
val ds12: DataSet[String] = env.fromCollection(Iterable("spark", "flink"))
ds12.print()
//13.用ArraySeq创建DataSet
val ds13: DataSet[String] = env.fromCollection(mutable.ArraySeq("spark", "flink"))
ds13.print()
//14.用ArrayStack创建DataSet
val ds14: DataSet[String] = env.fromCollection(mutable.ArrayStack("spark", "flink"))
ds14.print()
//15.用Map创建DataSet
val ds15: DataSet[(Int, String)] = env.fromCollection(Map(1 -> "spark", 2 -> "flink"))
ds15.print()
//16.用Range创建DataSet
val ds16: DataSet[Int] = env.fromCollection(Range(1, 9))
ds16.print()
//17.用formElements创建DataSet
val ds17: DataSet[Long] = env.generateSequence(1, 9)
ds17.print()
}
}
2 基于文件的 source(File-based-source)
2.1、读取本地文件
object BatchFromLocalFileSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从本地文件构建数据集
val localFileSource: DataSet[String] = env.readTextFile("day02/data/input/wordcount.txt")
//3.打印输出
localFileSource.print()
}
}2.2 读取 HDFS 数据
object BatchFromHDFSFileSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.从HDFS文件构建数据集
val hdfsFileSource: DataSet[String] = env.readTextFile("hdfs://node01:8020/test/input/wordcount.txt")
//3.输出打印
hdfsFileSource.print()
}
}2.3 读取 CSV 数据
object BatchFromCSVFileSource {
case class Subject(id:Int,name:String)
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从csv文件构建数据集
import org.apache.flink.api.scala._
val csvDataSet: DataSet[Subject] = env.readCsvFile[Subject]("day02/data/input/subject.csv")
//3.输出打印
csvDataSet.print()
}
}2.4 读取压缩文件
object BatchFromCompressFileSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.从压缩文件中构建数据集
val compressFileSource: DataSet[String] = env.readTextFile("day02/data/input/wordcount.txt.gz")
//3.输出打印
compressFileSource.print()
}
}2.5 基于文件的 source(遍历目录)
object BatchFromFolderSource {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.开启recursive.file.enumeration
val configuration: Configuration = new Configuration()
configuration.setBoolean("recursive.file.enumeration", true)
//3.根据遍历多级目录来构建数据集
val result: DataSet[String] = env.readTextFile("day02/data/input/a").withParameters(configuration)
result.print()
}
}三、DateSet 的 Transformation
1 map 函数
import org.apache.flink.api.scala.ExecutionEnvironment
/**
* 需求:
* 使用 map 操作, 将以下数据
* "1,张三", "2,李四", "3,王五", "4,赵六"
* 转换为一个 scala 的样例类。
*/
object BatchMapDemo {
//3.创建样例类
case class user(id:Int,name:String)
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.构建数据集
import org.apache.flink.api.scala._
val sourceDataSet: DataSet[String] = env.fromElements("1,张三", "2,李四", "3,王五", "4,赵六")
//4.数据转换处理
val userDataSet: DataSet[user] = sourceDataSet.map(item => {
val itemsArr: Array[String] = item.split(",")
user(itemsArr(0).toInt, itemsArr(1))
})
//5.打印输出
userDataSet.print()
}
}2 flatMap 函数
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable
/**
* 需求:
* 分别将以下数据, 转换成 国家 、 省份 、 城市 三个维度的数据。
* 将以下数据
* 张三,中国,江西省,南昌市
* 李四,中国,河北省,石家庄市
* Tom,America,NewYork,Manhattan
* 转换为
* 张三,中国
* 张三,中国江西省
* 张三,中国江西省南昌市
*/
object BatchFlatMapDemo {
def main(args: Array[String]): Unit = {
/**
* 1) 构建批处理运行环境
* 2) 构建本地集合数据源
* 3) 使用 flatMap 将一条数据转换为三条数据
* a. 使用逗号分隔字段
* b. 分别构建国家、 国家省份、 国家省份城市三个元组
* 4) 打印输出
*/
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val sourceDatSet: DataSet[String] = env.fromCollection(List(
"张三,中国,江西省,南昌市",
"李四,中国,河北省,石家庄市",
"Tom,America,NewYork,Manhattan"
))
val resultDataSet: DataSet[(String, String)] = sourceDatSet.flatMap(item => {
val itemsArr: mutable.ArrayOps[String] = item.split(",")
List(
(itemsArr(0), itemsArr(1)),
(itemsArr(0), itemsArr(1) + itemsArr(2)),
(itemsArr(0), itemsArr(1) + itemsArr(2) + itemsArr(3))
)
})
resultDataSet.print()
}
}3 mapPartition 函数
import org.apache.flink.api.scala.ExecutionEnvironment
/**
* 需求:
* 使用 mapPartition 操作, 将以下数据
* "1,张三", "2,李四", "3,王五", "4,赵六"
* 转换为一个 scala 的样例类。
*/
object BatchMapPartitionDemo {
case class user(id:Int,name:String)
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.构建数据集
import org.apache.flink.api.scala._
val sourceDataSet: DataSet[String] = env.fromElements("1,张三", "2,李四", "3,王五", "4,赵六")
//3数据处理
val userDataSet: DataSet[user] = sourceDataSet.mapPartition(itemPartition => {
itemPartition.map(item => {
val itemsArr: Array[String] = item.split(",")
user(itemsArr(0).toInt, itemsArr(1))
})
})
//4.打印数据
userDataSet.print()
}
}4 filter
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/**
* 过滤出来以下以 h 开头的单词。
* "hadoop", "hive", "spark", "flink"
*/
object BatchFilterDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromElements("hadoop",
"hive", "spark", "flink")
val filterDataSet: DataSet[String] = textDataSet.filter(x => x.startsWith("h")) filterDataSet
.print()
}
}5 reduce
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/**
* 请将以下元组数据,
* 使用 reduce 操作聚合成一个最终结果 ("java" , 1) , ("java", 1) ,("java" , 1)
* 将上传元素数据转换为 ("java",3)
*/
object BatchReduceDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java", 1), ("java", 1), ("java", 1)))
val groupedDataSet: GroupedDataSet[(String, Int)] = textDataSet.groupBy(0)
val reduceDataSet: DataSet[(String, Int)] = groupedDataSet.reduce((v1, v2) => (v1._1, v1._2 + v2._2)) reduceDataSet
.print()
}
}6 reduceGroup
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.api.scala._
/**
* 请将以下元组数据,先按照单词使用 groupBy 进行分组,
* 再使用 reduceGroup 操作进行单词计数
* ("java" , 1) , ("java", 1) ,("scala" , 1)
*/
object BatchReduceGroupDemo {
def main(args: Array[String]): Unit = {
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java", 1), ("java", 1), ("scala", 1)))
val groupedDataSet: GroupedDataSet[(String, Int)] = textDataSet.groupBy(0)
val reduceGroupDataSet: DataSet[(String, Int)] = groupedDataSet.reduceGroup(group => {
group.reduce((v1, v2) => {
(v1._1, v1._2 + v2._2)
})
})
reduceGroupDataSet.print()
}
}7 Aggregate
import org.apache.flink.api.java.aggregation.Aggregations
import org.apache.flink.api.scala._
/**
* 请将以下元组数据,使用 aggregate 操作进行单词统计
* ("java" , 1) , ("java", 1) ,("scala" , 1)
*/
object BatchAggregateDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet = env.fromCollection(List(("java", 1), ("java", 1), ("scala", 1)))
val grouped = textDataSet.groupBy(0)
val aggDataSet: AggregateDataSet[(String, Int)] = grouped.aggregate(Aggregations.MAX, 1) aggDataSet
.print()
}
}8 minBy 和 maxBy
import org.apache.flink.api.java.aggregation.Aggregations
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable
import scala.util.Random
object BatchMinByAndMaxBy {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val data = new mutable.MutableList[(Int, String, Double)]
data.+=((1, "yuwen", 89.0))
data.+=((2, "shuxue", 92.2))
data.+=((3, "yingyu", 89.99))
data.+=((4, "wuli", 98.9))
data.+=((1, "yuwen", 88.88))
data.+=((1, "wuli", 93.00))
data.+=((1, "yuwen", 94.3))
//导入隐式转换
import org.apache.flink.api.scala._
//fromCollection将数据转化成DataSet
val input: DataSet[(Int, String, Double)] = env.fromCollection(Random.shuffle(data))
input.print()
println("===========获取指定字段分组后,某个字段的最大值 ==================")
val output = input.groupBy(1).aggregate(Aggregations.MAX, 2)
output.print()
println("===========使用【MinBy】获取指定字段分组后,某个字段的最小值 ==================")
// val input: DataSet[(Int, String, Double)]= env.fromCollection(Random.shuffle(data))
val output2: DataSet[(Int, String, Double)] = input.groupBy(1)
//求每个学科下的最小分数
// minBy的参数代表要求哪个字段的最小值
.minBy(2)
output2.print()
println ("===========使用【maxBy】获取指定字段分组后,某个字段的最大值 ==================")
// val input: DataSet[(Int, String, Double)] = env.fromCollection(Random.shuffle(data))
val output3: DataSet[(Int, String, Double)] = input.groupBy(1)
//求每个学科下的最小分数
// minBy的参数代表要求哪个字段的最小值
.maxBy(2)
output3.print()
}
}9 distinct 去重
import org.apache.flink.api.scala._
/**
** 请将以下元组数据,使用 distinct 操作去除重复的单词
** ("java" , 1) , ("java", 1) ,("scala" , 1)
** 去重得到 ** ("java", 1), ("scala", 1)
* */
object BatchDistinctDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[(String, Int)] = env.fromCollection(List(("java", 1), ("java", 1), ("scala", 1)))
textDataSet.distinct(1).print()
}
}10 Join
import org.apache.flink.api.scala._
/**
** 使用join可以将两个DataSet连接起来
**/
object BatchJoinDemo {
case class Subject(id: Int, name: String)
case class Score(id: Int, stuName: String, subId: Int, score: Double)
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val subjectDataSet: DataSet[Subject] = env.readCsvFile[Subject]("day01/data/input/subject.csv")
val scoreDataSet: DataSet[Score] = env.readCsvFile[Score]("day01/data/input/score.csv")
//join的替代方案:broadcast
val joinDataSet: JoinDataSet[Score, Subject] = scoreDataSet.join(subjectDataSet).where(_.subId).equalTo(_.id)
joinDataSet.print()
}
}优化 join
通过给Flink一些提示,可以使得你的 join 更快,但是首先我们要简单了解一下Flink如何执行join的。
当 Flink 处理批量数据的时候,每台机器只是存储了集群的部分数据。为了执行 join,Flink 需 要找到两个数据集的所有满足 join 条件的数据。为了实现这个目标,Flink 需 要将两个数据集有相同 key 的数据发送到同一台机器上。
有两种策略:
1. repartition-repartition strategy
在该情况下,两个数据集都会使用key进行重分区并使用通过网络传输。这就意味着假如数据集太大的话,网络传输数据集将耗费大量的时间。
2. broadcast-forward strategy 在该情况下,一个数据集不动,另一个数据集会 copy 到有第一个数据集部分数据的所有机 器上。如果使用小数据集与大数据集进行 join,可以选择 broadcast-forward 策略,将小数据集广播,避免代价高的重分区。 ds1.join(ds2, JoinHint.BROADCAST_HASH_FIRST) 第二个参数就是提示,第一个数据集比第二个小。 也可以使用下面几个提示:
BROADCAST_HASH_SECOND: 第二个数据集是较小的数据集
REPARTITION_HASH_FIRST: 第一个书记集是较小的数据集
REPARTITION_HASH_SECOND: 第二个数据集是较小的数据集。
REPARTITION_SORT_MERGE: 对数据集进行重分区,同时使用 sort 和 merge 策略。
OPTIMIZER_CHOOSES: (默认的)Flink 的优化器决定两个数据集如何 join。
11 LeftOuterJoin
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* 左外连接,左边的Dataset中的每一个元素,去连接右边的元素
*/
object BatchLeftOuterJoinDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data1 = ListBuffer[Tuple2[Int, String]]()
data1.append((1, "zhangsan"))
data1.append((2, "lisi"))
data1.append((3, "wangwu"))
data1.append((4, "zhaoliu"))
val data2 = ListBuffer[Tuple2[Int, String]]()
data2.append((1, "beijing"))
data2.append((2, "shanghai"))
data2.append((4, "guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first, second) => {
if (second == null) {
(first._1, first._2, "null")
} else {
(first._1, first._2, second._2)
}
}).print()
}
}12 RightOuterJoin
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
/**
* 左外连接,左边的Dataset中的每一个元素,去连接右边的元素
*/
object BatchLeftOuterJoinDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data1 = ListBuffer[Tuple2[Int, String]]()
data1
.append((1, "zhangsan"))
data1
.append((2, "lisi"))
data1.append((3, "wangwu"))
data1.append((4, "zhaoliu"))
val data2 = ListBuffer[Tuple2[Int, String]]()
data2.append((1, "beijing"))
data2.append((2, "shanghai"))
data2.append((4, "guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.rightOuterJoin(text2).where(0).equalTo(0).apply((first, second) => {
if (second == null) {
(first._1, first._2, "null")
} else {
(first._1, first._2, second._2)
}
}).print()
}
}13 fullOuterJoin
import org.apache.flink.api.common.operators.base.JoinOperatorBase.JoinHint
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import scala.collection.mutable.ListBuffer
/** ** 左外连接,左边的Dataset中的每一个元素,去连接右边的元素 * */
object BatchFullOuterJoinDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val data1 = ListBuffer[Tuple2[Int, String]]()
data1.append((1, "zhangsan"))
data1.append((2, "lisi"))
data1.append((3, "wangwu"))
data1.append((4, "zhaoliu"))
val data2 = ListBuffer[Tuple2[Int, String]]()
data2.append((1, "beijing"))
data2.append((2, "shanghai"))
data2.append((4, "guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
/**
* OPTIMIZER_CHOOSES:将选择权交予Flink优化器,相当于没有给提示;
* BROADCAST_HASH_FIRST:广播第一个输入端,同时基于它构建一个哈希表,而第 二个输入端作为探索端,选择这种策略的场景是第一个输入端规模很小;
* BROADCAST_HASH_SECOND:广播第二个输入端并基于它构建哈希表,第一个输入端 作为探索端,选择这种策略的场景是第二个输入端的规模很小;
* REPARTITION_HASH_FIRST:该策略会导致两个输入端都会被重分区,但会基于第 一个输入端构建哈希表。该策略适用于第一个输入端数据量小于第二个输入端的数据量,但这 两个输入端的规模仍然很大,优化器也是当没有办法估算大小,没有已 存在的分区以及排序 顺序可被使用时系统默认采用的策略;
* REPARTITION_HASH_SECOND:该策略会导致两个输入端都会被重分区,但会基于 第二个输入端构建哈希表。该策略适用于两个输入端的规模都很大,但第二个输入端的数据量 小于第一个输入端的情况;
* REPARTITION_SORT_MERGE:输入端被以流的形式进行连接并合并成排过序的输入。 该策略适用于一个或两个输入端都已 排过序的情况;
*/
text1.fullOuterJoin(text2, JoinHint.REPARTITION_SORT_MERGE).where(0).equalTo(0).apply((first, second) => {
if (first == null) {
(second._1, "null", second._2)
} else if (second == null) {
(first._1, first._2, "null")
} else {
(first._1, first._2, second._2)
}
}).print()
}
}14 cross 交叉操作
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.api.scala._
/**
** 通过形成这个数据集和其他数据集的笛卡尔积,创建一个新的数据集。
**/
object BatchCrossDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
println ("============cross==================")
cross (env)
println ("============cross2==================")
cross2 (env)
println ("============cross3==================")
cross3 (env)
println ("============crossWithTiny==================")
crossWithTiny (env)
println ("============crossWithHuge==================")
crossWithHuge (env)
}
/**
* @param benv
* 交叉。拿第一个输入的每一个元素和第二个输入的每一个元素进行交叉操作。
* res71: Seq[((Int, Int, Int), (Int, Int, Int))] = Buffer(
* ((1,4,7),(10,40,70)), ((2,5,8),(10,40,70)), ((3,6,9),(10,40,70)),
* ((1,4,7),(20,50,80)), ((2,5,8),(20,50,80)), ((3,6,9),(20,50,80)),
* ((1,4,7),(30,60,90)), ((2,5,8),(30,60,90)), ((3,6,9),(30,60,90)))
*/
def cross(benv: ExecutionEnvironment): Unit = {
//1.定义两个DataSet
val coords1 = benv.fromElements((1, 4, 7), (2, 5, 8), (3, 6, 9))
val coords2 = benv.fromElements((10, 40, 70), (20, 50, 80), (30, 60, 90))
//2.交叉两个DataSet[Coord]
val result1 = coords1.cross(coords2)
// 3.显示结果
println(result1.collect)
}
/**
*@param benv
* res69: Seq[(Coord, Coord)] = Buffer(
* (Coord(1,4,7),Coord(10,40,70)), (Coord(2,5,8),Coord(10,40,70)), (Coord(3,6,9),Coord(10,40,70)),
* (Coord(1,4,7),Coord(20,50,80)), (Coord(2,5,8),Coord(20,50,80)), (Coord(3,6,9),Coord(20,50,80)),
* (Coord(1,4,7),Coord(30,60,90)), (Coord(2,5,8),Coord(30,60,90)), (Coord(3,6,9),Coord(30,60,90)))
*/
def cross2(benv: ExecutionEnvironment): Unit = {
//1.定义 case class
case class Coord(id: Int, x: Int, y: Int)
// 2.定义两个DataSet[Coord]
val coords1: DataSet[Coord] = benv.fromElements(
Coord(1, 4, 7),
Coord(2, 5, 8),
Coord(3, 6, 9))
val coords2: DataSet[Coord] = benv.fromElements(
Coord(10, 40, 70),
Coord(20, 50, 80),
Coord(30, 60, 90))
//3.交叉两个DataSet[Coord]
val result1 = coords1.cross(coords2)
//4.显示结果
println(result1.collect)
}
/**
* @param benv
* res65: Seq[(Int, Int, Int)] = Buffer(
* (1,1,22), (2,1,24), (3,1,26),
* (1,2,24), (2,2,26), (3,2,28),
*(1,3,26), (2,3,28), (3,3,30)
* )
*/
def cross3(benv: ExecutionEnvironment): Unit = {
//1.定义 case class
case class Coord(id: Int, x: Int, y: Int)
//2.定义两个DataSet[Coord]
val coords1: DataSet[Coord] = benv.fromElements(
Coord(1, 4, 7),
Coord(2, 5, 8),
Coord(3, 6, 9))
val coords2: DataSet[Coord] = benv.fromElements(
Coord(1, 4, 7),
Coord(2, 5, 8),
Coord(3, 6, 9))
//3.交叉两个DataSet[Coord],使用自定义方法
val r = coords1.cross(coords2) { (c1, c2) => {
val dist = (c1.x + c2.x) + (c1.y + c2.y)
(c1.id, c2.id, dist)
}
}
//4.显示结果
println(r.collect)
}
/**
* 暗示第二个输入较小的交叉。
* 拿第一个输入的每一个元素和第二个输入的每一个元素进行交叉操作。
*@param benv
* res67: Seq[(Coord, Coord)] = Buffer(
* (Coord(1,4,7),Coord(10,40,70)), (Coord(1,4,7),Coord(20,50,80)), (Coord(1,4,7),Coord(30,60,90)),
* (Coord(2,5,8),Coord(10,40,70)), (Coord(2,5,8),Coord(20,50,80)), (Coord(2,5,8),Coord(30,60,90)),
* (Coord(3,6,9),Coord(10,40,70)), (Coord(3,6,9),Coord(20,50,80)), (Coord(3,6,9),Coord(30,60,90)))
*/
def crossWithTiny(benv: ExecutionEnvironment): Unit = {
//1.定义 case class
case class Coord(id: Int, x: Int, y: Int)
//2.定义两个DataSet[Coord]
val coords1: DataSet[Coord] = benv.fromElements(
Coord(1, 4, 7),
Coord(2, 5, 8),
Coord(3, 6, 9))
val coords2: DataSet[Coord] = benv.fromElements(
Coord(10, 40, 70),
Coord(20, 50, 80),
Coord(30, 60, 90))
//3.交叉两个DataSet[Coord],暗示第二个输入较小
val result1 = coords1.crossWithTiny(coords2)
//4.显示结果
println(result1.collect)
}
/**
* @param benv
* 暗示第二个输入较大的交叉。
* 拿第一个输入的每一个元素和第二个输入的每一个元素进行交叉操作。
* res68: Seq[(Coord, Coord)] = Buffer((Coord(1,4,7),Coord(10,40,70)), (Coord(2,5,8),Coord(10,40,70)), (Coord(3,6,9),Coord(10,40,70)),
* (Coord(1,4,7),Coord(20,50,80)), (Coord(2,5,8),Coord(20,50,80)), (Coord(3,6,9),Coord(20,50,80)),
* (Coord(1,4,7),Coord(30,60,90)), (Coord(2,5,8),Coord(30,60,90)), (Coord(3,6,9),Coord(30,60,90)))
*
*/
def crossWithHuge(benv: ExecutionEnvironment): Unit = {
//1.定义 case class
case class Coord(id: Int, x: Int, y: Int)
//2.定义两个DataSet[Coord]
val coords1: DataSet[Coord] = benv.fromElements(
Coord(1, 4, 7),
Coord(2, 5, 8),
Coord(3, 6, 9))
val coords2: DataSet[Coord] = benv.fromElements(
Coord(10, 40, 70),
Coord(20, 50, 80),
Coord(30, 60, 90))
//3.交叉两个DataSet[Coord],暗示第二个输入较大
val result1 = coords1.crossWithHuge(coords2)
//4.显示结果
println(result1.collect)
}
}15 Union
import org.apache.flink.api.scala._
/** * 将两个DataSet取并集,并不会进行去重。 */
object BatchUnionDemo {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
// 使用`fromCollection`创建两个数据源
val wordDataSet1 = env.fromCollection(List("hadoop", "hive", "flume"))
val wordDataSet2 = env.fromCollection(List("hadoop", "hive", "spark"))
val wordDataSet3 = env.fromElements("hadoop")
val wordDataSet4 = env.fromElements("hadoop")
wordDataSet1.union(wordDataSet2).print()
wordDataSet3.union(wordDataSet4).print()
}
}16 Rebalance
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
/**
* 实现步骤:
* 1) 构建批处理运行环境
* 2) 使用 env.generateSequence 创建 0-100 的并行数据
* 3) 使用 fiter 过滤出来 大于 8 的数字
* 4) 使用 map 操作传入 RichMapFunction , 将当前子任务的 ID 和数字构建成一个元组
* 5) 在 RichMapFunction 中可以使用 getRuntimeContext.getIndexOfThisSubtask 获取子
* 任务序号
* 6) 打印测试
*/
object BatchRebalanceDemo {
def main(args: Array[String]): Unit = {
//1) 构建批处理运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2) 使用 env.generateSequence 创建 0-100 的并行数据
val source: DataSet[Long] = env.generateSequence(0,100)
//3) 使用 fiter 过滤出来 大于 8 的数字
val filter: DataSet[Long] = source.filter(_>8)
//使用rebalance进行处理数据
val rebalance: DataSet[Long] = filter.rebalance()
//4) 使用 map 操作传入 RichMapFunction , 将当前子任务的 ID 和数字构建成一个元组
import org.apache.flink.api.scala._
val result: DataSet[(Int, Long)] = rebalance.map(new RichMapFunction[Long, (Int, Long)] {
override def map(value: Long): (Int, Long) = {
(getRuntimeContext.getIndexOfThisSubtask, value)
}
})
result.print()
}
}17 First
import org.apache.flink.api.common.operators.Order
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable.ListBuffer
object BatchFirstNDemo {
def main(args: Array[String]): Unit = {
val env=ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data = ListBuffer[Tuple2[Int,String]]()
data.append((2,"zs"))
data.append((4,"ls"))
data.append((3,"ww"))
data.append((1,"xw"))
data.append((1,"aw"))
data.append((1,"mw"))
val text = env.fromCollection(data)
//获取前3条数据,按照数据插入的顺序
text.first(3).print()
println("==============================")
//根据数据中的第一列进行分组,获取每组的前2个元素
text.groupBy(0).first(2).print()
println("==============================")
//根据数据中的第一列分组,再根据第二列进行组内排序[升序],获取每组的前2个元素
text.groupBy(0).sortGroup(1,Order.ASCENDING).first(2).print()
println("==============================")
//不分组,全局排序获取集合中的前3个元素,
text.sortPartition(0,Order.ASCENDING).sortPartition(1,Order.DESCENDING).first(3).print()
}
}四、数据输出 Data Sinks
1 基于本地集合的 sink
import org.apache.flink.api.scala.ExecutionEnvironment
//基于本地集合的sink
object BatchSinkCollection {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.构建数据集
import org.apache.flink.api.scala._
val source: DataSet[(Int, String, Double)] = env.fromElements(
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
)
//3.数据打印
source.print()
println(source.collect())
source.printToErr()
}
}2 基于文件的 sink
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.core.fs.FileSystem.WriteMode
//基于文件的 sink
object BatchSinkFile {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.构建数据集
import org.apache.flink.api.scala._
val source: DataSet[(Int, String, Double)] = env.fromElements(
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
)
//保存到本地文件
// source.writeAsText("day02/data/output/sinkLocalFile").setParallelism(1)
//保存到HDFS文件中
source.writeAsText("hdfs://node01:8020/test/output/sinkHDFSFile0708",WriteMode.OVERWRITE).setParallelism(1)
env.execute(this.getClass.getSimpleName)
}
}五、广播变量
Flink 支持广播变量,就是将数据广播到具体的 taskmanager 上,数据存储在内存中, 这样可以减缓大量的 shuffle 操作; 比如在数据 join 阶段,不可避免的就是大量的 shuffle 操作,我们可以把其中一个 dataSet 广播出去,一直加载到 taskManager 的内存 中,可以直接在内存中拿数据,避免了大量的 shuffle, 导致集群性能下降; 广播变量创 建后,它可以运行在集群中的任何 function 上,而不需要多次传递给集群节点。另外需要 记住,不应该修改广播变量,这样才能确保每个节点获取到的值都是一致的。
一句话解释,可以理解为是一个公共的共享变量,我们可以把一个 dataset 数据集广 播出去, 然后不同的 task 在节点上都能够获取到,这个数据在每个节点上只会存在一份。 如果不使用 broadcast,则在每个节点中的每个 task 中都需要拷贝一份 dataset 数据集, 比较浪费内存(也 就是一个节点中可能会存在多份 dataset 数据)。
因为广播变量是要把 dataset 广播到内存中,所以广播的数据量不能太大,否则会 出 现OOM 这样的问题。
- Broadcast:Broadcast 是通过 withBroadcastSet(dataset,string)来注册的
- Access:通过 getRuntimeContext().getBroadcastVariable(String)访问广播变量
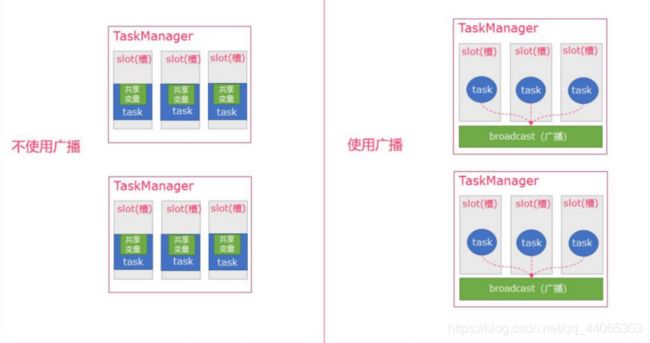
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的 Task 都可以在节点上获取到
- 每个节点 只存一份
- 如果不使用广播,每一个 Task 都会拷贝一份数据集,造成内存资源浪费
import java.util
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
/**
* 需求:
*创建一个 学生数据集,包含以下数据
*|学生ID | 姓名|
* |------|------|
* List((1, "张三"), (2, "李四"), (3, "王五"))
*再创建一个 成绩数据集,
*|学生ID | 学科| 成绩|
* |------|------|-----|
* List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86))
*请通过广播获取到学生姓名,将数据转换为
* List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86))
*/
object BatchBroadcastDemo {
def main(args: Array[String]): Unit = {
/**
*1. 获取批处理运行环境
*2. 分别创建两个数据集
*3. 使用RichMapFunction 对成绩数据集进行map转换
*4. 在数据集调用map 方法后,调用withBroadcastSet 将学生数据集创建广播
*5. 实现RichMapFunction
*将成绩数据(学生ID,学科,成绩) -> (学生姓名,学科,成绩)
*重写 open 方法中,获取广播数据
*导入 scala.collection.JavaConverters._ 隐式转换
*将广播数据使用asScala 转换为Scala集合,再使用toList转换为scala List集合
*在map 方法中使用广播进行转换
*6. 打印测试
*/
//1. 获取批处理运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2. 分别创建两个数据集
// 创建学生数据集
val stuDataSet: DataSet[(Int, String)] = env.fromCollection( List((1, "张三"), (2, "李四"), (3, "王五")))
//创建成绩数据集
val socreDataSet: DataSet[(Int, String, Int)] = env.fromCollection(List((1, "语文", 50),(2, "数学", 70), (3, "英文", 86)))
//3. 使用RichMapFunction 对成绩数据集进行map转换
// 返回值类型(学生名字,学科成名,成绩)
val result: DataSet[(String, String, Int)] = socreDataSet.map( new RichMapFunction[(Int, String, Int), (String, String, Int)] {
//定义获取学生数据集的集合
var studentMap:Map[Int, String] = null
//初始化的时候被执行一次,在对象的生命周期中只被执行一次
override def open(parameters: Configuration): Unit = {
//因为获取到的广播变量中的数据类型是java的集合类型,但是我们的代码是 scala因此需要将java的集合转换成scala的集合
//我们这里将list转换成了map对象,之所以能够转换是因为list中的元素是对偶 元祖,因此可以转换成kv键值对类型
//之所以要转换,是因为后面好用,传递一个学生id,可以直接获取到学生的名字
import scala.collection.JavaConversions._
val studentList: util.List[(Int, String)] = getRuntimeContext.getBroadcastVariable[(Int, String)]("student")
studentMap = studentList.toMap
}
//要对集合中的每个元素执行map操作,也就是说集合中有多少元素,就被执行多少次
override def map(value: (Int, String, Int)): (String, String, Int) = {
//(Int, String, Int)=》(学生id,学科名字,学生成绩)
//返回值类型(学生名字,学科成名,成绩)
val stuId = value._1
val stuName = studentMap.getOrElse(stuId, "")
//(学生名字,学科成名,成绩)
(stuName, value._2, value._3)
}
}).withBroadcastSet(stuDataSet, "student")
result.print()
}
}
六、Flink 的分布式缓存
缓存的使用流程:
使用 ExecutionEnvironment 实例对本地的或者远程的文件(例如:HDFS 上的文件),为缓
存 文件指定一个名字注册该缓存文件!当程序执行时候,Flink 会自动将复制文件或者目
录到所有 worker 节点的本地文件系统中,函数可以根据名字去该节点的本地文件系统中检
索该文件!
广播是将变量分发到各个 worker 节点的内存上,分布式缓存是将文件缓存到各个 worker 节点上;
package batch
import java.io.File
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.configuration.Configuration
import org.apache.flink.api.scala._
import scala.io.Source
/**
* 需求:
* 创建一个 成绩 数据集
* List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86))
* 请通过分布式缓存获取到学生姓名,将数据转换为
* List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86))
* 注: distribute_cache_student 测试文件保存了学生 ID 以及学生姓名
*/
object BatchDisCachedFile {
def main(args: Array[String]): Unit = {
/**
* 实现步骤:
* 1) 将 distribute_cache_student 文件上传到 HDFS /test/input/ 目录下
* 2) 获取批处理运行环境
* 3) 创建成绩数据集
* 4) 对成绩 数据集进行 map 转换,将(学生 ID, 学科, 分数)转换为(学生姓名, 学科,分数)
* a. RichMapFunction 的 open 方法中,获取分布式缓存数据
* b. 在 map 方法中进行转换
* 5) 实现 open 方法
* a. 使用 getRuntimeContext.getDistributedCache.getFile 获取分布式缓存文件
* b. 使用 Scala.fromFile 读取文件,并获取行
* c. 将文本转换为元组(学生 ID,学生姓名),再转换为 List
* 6) 实现 map 方法
* a. 从分布式缓存中根据学生 ID 过滤出来学生
* b. 获取学生姓名
* c. 构建最终结果元组
* 7) 打印测试
*/
//获取批处理运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//注册一个分布式缓存
env.registerCachedFile("hdfs://node01:8020/test/input/distribute_cache_student", "student")
//创建成绩数据集
val scoreDataSet: DataSet[(Int, String, Int)] = env.fromCollection(List((1, "语文", 50), (2, "数学", 70), (3, "英文", 86)))
val resultDataSet: DataSet[(String, String, Int)] = scoreDataSet.map(
new RichMapFunction[(Int, String, Int), (String, String, Int)] {
var studentMap: Map[Int, String] = null
//初始化的时候之被调用一次
override def open(parameters: Configuration): Unit = {
//获取分布式缓存的文件
val studentFile: File = getRuntimeContext.getDistributedCache.getFile("student")
val linesIter: Iterator[String] = Source.fromFile(studentFile).getLines()
studentMap = linesIter.map(lines => {
val words: Array[String] = lines.split(",")
(words(0).toInt, words(1))
}).toMap
}
override def map(value: (Int, String, Int)): (String, String, Int) = {
val stuName: String = studentMap.getOrElse(value._1, "")
(stuName, value._2, value._3)
}
})
//输出打印测试
resultDataSet.print()
}
}
七、Flink Accumulators & Counters
与 Mapreduce counter 的应用场景差不多,都能很好地观察 task 在运行期间的数据变化 可以在 Flink job 任务中的算子函数中操作累加器,但是只能在任务执行结束之后才能获得累加器的最终结果。
Counter 是 一 个 具 体 的 累 加 器 (Accumulator) 实 现 IntCounter, LongCounter 和DoubleCounter
package batch.transformation
import org.apache.flink.api.common.JobExecutionResult
import org.apache.flink.api.common.accumulators.IntCounter
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.java.ExecutionEnvironment
import org.apache.flink.api.java.operators.{DataSource, MapOperator}
import org.apache.flink.configuration.Configuration
import org.apache.flink.core.fs.FileSystem.WriteMode
/**
* 需求:
* 给定一个数据源
* "a","b","c","d"
* 通过累加器打印出多少个元素
*/
object BatchAccumulator {
def main(args: Array[String]): Unit = {
//1.创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.创建数据源
val sourceDataSet: DataSource[String] = env.fromElements("a", "b", "c", "d")
//3.对sourceDataSet 进行map操作
val resultDataSet: MapOperator[String, String] = sourceDataSet.map(new RichMapFunction[String, String] {
//创建累加器
val counter: IntCounter = new IntCounter
//初始化的时候被执行一次
override def open(parameters: Configuration): Unit = {
//注册累加器
getRuntimeContext.addAccumulator("MyAccumulator", this.counter)
}
//每条数据都会被执行一次
override def map(value: String): String = {
counter.add(1)
value
}
})
resultDataSet.print()
resultDataSet.writeAsText("./data/output/Accumulators",WriteMode.OVERWRITE)
val result: JobExecutionResult = env.execute("BatchAccumulator")
val MyAccumulatorValue: Int = result.getAccumulatorResult[Int]("MyAccumulator")
print("累加的值:"+MyAccumulatorValue)
}
}