Linux 内核网络协议栈 ------sk_buff 结构体 以及 完全解释 (2.6.16)
在2.6.24之后这个结构体有了较大的变化,此处先说一说2.6.16版本的sk_buff,以及解释一些问题。
一、
先直观的看一下这个结构体~~~~~~~~~~~~~~~~~~~~~~在下面解释每个字段的意义~~~~~~~~~~~
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk;
struct skb_timeval tstamp;
struct net_device *dev;
struct net_device *input_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
struct dst_entry *dst;
struct sec_path *sp;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48];
unsigned int len,
data_len,
mac_len,
csum;
__u32 priority;
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3,
fclone:2,
ipvs_property:1;
__be16 protocol;
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_NETFILTER
__u32 nfmark;
struct nf_conntrack *nfct;
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct sk_buff *nfct_reasm;
#endif
#ifdef CONFIG_BRIDGE_NETFILTER
struct nf_bridge_info *nf_bridge;
#endif
#endif /* CONFIG_NETFILTER */
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
/* These elements must be at the end, see alloc_skb() for details. */
unsigned int truesize;
atomic_t users;
unsigned char *head,
*data,
*tail,
*end;
};> : next和prev,这两个域是用来连接相关的skb的(例如如果有分片,将这些分片连接在一起可以)
> : sk,指向报文所属的套接字指针
> : tstamp,记录接收或者传输报文的时间戳
> : dev和input_dev,记录接收或者发送的设备
>: union u,对于一个层次,例如tcp层,可能有很多不同的协议,他们的协议头不一样,那么这个联合体就是记录这些协议头的。
此处u就是代表传输层
> : union nh,代表网络层头
> : union mac,代表链路层头
> : dst,指向des_entry结构,记录了到达目的地的路由信息,以及其他的一些网络特征信息。
> : sp:安全路径,用于xfrm
> : cb[],保存与协议相关的控制信息,每个协议可能独立使用这些信息。
> : 重要的字段 len 和 data_len:
len代: 表整个数据区域的长度!这里要提前解释几个定义,skb的组成是有sk_buff控制 + 线性数据 + 非线性数据
(skb_shared_info) 组成!
后面会具体解释是什么意思!在sk_buff这个里面没有实际的数据,这里仅仅是控制信息,数据是通过后面的data指针指向其他内
存块的!那个内存块中是线性数据和
非线性数据!那么len就是length(线性数据) + length(非线性数据)!!!
data_len: 指的是length(非线性数据)!!!那么可以知道:length(线性数据) = skb->len - skb->data_len
> : mac_len,指的是mac头长度
> : csum,某时刻协议的校验和
> : priority,报文排队优先级,取决于ip中的tos域
> : local_df,允许在本地分配
> : cloned,保存当前的skb_buff是克隆的还是原始数据
> : ip_summed,是否计算ip校验和
> : nohdr,仅仅引用数据区域
> : pkt_type,报文类型,例如广播,多播,回环,本机,传出...
> : fclone,skb_buff克隆状态
> : ipvs_property,skb_buff是否属于ipvs
> : protocal,协议信息
> : nfmark,用于钩子之间通信
> : nfct_reasm,netfilter的跟踪连接重新组装指针
> : nf_bridge,保存桥接信息
> : tc_index: Traffic control index,tc_verd: traffic control verdict
> : truesize,该缓冲区分配的所有总的内存,包括:skb_buff + 所有数据大小
> : users,保存引用skb_buff的数量
> : 重要数据字段:head,data,tail,end!!!
head:指向分配给的线性数据内存首地址( 建立起一个观念:并不是分配这么多内存,就都能被使用作为数据存储,可能没这么多
数据也有可能!但是也不要认为分配这么多 就足够了,也不一定(非线性数据就是例子) )
data:指向保存数据内容的首地址!我们由head可以知道,head和data不一定就是指在同一个位置!!!
tail:指向数据的结尾!
end:指向分配的内存块的结尾! ( 由上面我们知道数据结尾 != 分配的内存块的结尾 )
下面还会具体分析!!!!!!!!!!!
二、
我觉得需要先了解一些对于一个数据skb到底有什么,或者说由哪些元素组成!这就需要知道所谓的 “线性数据” 和 “非线性数据”。
基本的组成如下:
> : sk_buff : 这是一个sk_buff的控制结构
> : 线性数据区域
> : 非线性数据区域( 由skb_shared_info结构体管理 )
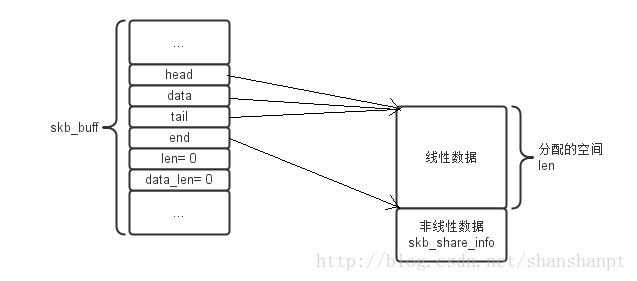
那么下面通过一个图来看看这个skb结构到底是怎么样的!看(图一)

(图一)
借助图一,我们先来分析两个重要字段:len和data_len!
之前说过len代表的是整个数据的长度,data_len代表的是非线性数据长度。我们由图一可以看到线性数据长度为l1,再看看非线性数据,其实就是看frags[]和frag_list
ok...那么我们可以知道非线性数据长度为( l2 + ... + ln ) + ( l(n+1) + ... + lm )
即:len = l1 + ( l2 + ... + ln ) + ( l(n+1) + ... + lm )
data_len = ( l2 + ... + ln ) + ( l(n+1) + ... + lm )
ok...
现在从分配内存开始解释这个图的由来:
我们使用skb_alloc给skb分配空间,那么刚刚分配结束返回时候,是什么样的情况呢?看下图(图二):

(图二)
刚刚开始初始化的时候,预分配一个一块线性数据区域,这个区域一般放入的是各个协议层次的不同的头,还有一些实际数据,下面的非线性区域是为了弥补当数据真的很多的时候,作为数据区域的扩展!关于skb_shared_info具体意思下面会继续说!注意在初始化的时候,head,data和tail都指向内存的开始位置,head在这个位置始终不变,它表示的是分配的内存的开始位置。end的位置也是不变的,表示的是分配的内存的结束位置。data和tail会随着数据的加入和减少变化,总之表示的是放入数据的内存区域(由图一)可知。
现在需要解释一下skb_shared_info这个结构体,这个结构体真的是很很有特色!主要是其中的两个字段frags和frag_list,下面继续解释:
struct skb_shared_info {
atomic_t dataref; // 对象被引用次数
unsigned short nr_frags; // 分页段数目,即frags数组元素个数
unsigned short tso_size;
unsigned short tso_segs;
unsigned short ufo_size;
unsigned int ip6_frag_id;
struct sk_buff *frag_list; // 一般用于分段(还没有非常清楚的理解)
skb_frag_t frags[MAX_SKB_FRAGS]; // 保存分页数据(skb->data_len=所有的数组数据长度之和)
};关于frags和frag_list没有必然的联系!
> : 对于frags[]一般用在,当数据真的很多,而且在线性数据区域装不下的时候,需要使用这个,skb_frag_t中是一页一页的数据,先看看结构体:
struct skb_frag_struct {
struct page *page; // 代表一页数据
__u16 page_offset; // 代表相对开始位置的页偏移量
__u16 size; // page中数据长度
};需要注意的是:只有在DMA支持物理分散页的Scatter/Gather(SG,分散/聚集)操作时候才可以使用frags[]来保存剩下的数据,否则,只能扩展线性数据区域进行保存!!!
这些页其实是其实就是虚拟页映射到物理页的结构,看下图(图三):

(图三)
> : 对于frag_list来说,一般我们在分片的时候里面装入每个片的信息,注意,每个片最终也都是被封装成一个小的skb,这个必须
的!
注意:具体怎么分片的看上一篇博文:数据分片 ( 看其中的ip_fragment函数 )
那么看一下其基本结构如图四:

(图四)
三、
最重要的是需要理解对于这个skb是怎么操作的,在操作的过程中,每一块的内存分配是怎么变化的,这才更重要!
看下面的函数们:
> : alloc_skb()函数
static inline struct sk_buff *alloc_skb(unsigned int size,
gfp_t priority)
{
return __alloc_skb(size, priority, 0);
}struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
int fclone)
{
kmem_cache_t *cache;
struct skb_shared_info *shinfo;
struct sk_buff *skb;
u8 *data;
cache = fclone ? skbuff_fclone_cache : skbuff_head_cache; // 根据克隆状态来判断在哪一个缓冲区进行分配cache
/* Get the HEAD */
skb = kmem_cache_alloc(cache, gfp_mask & ~__GFP_DMA); // 得到skb,注意这里没有包含数据,仅仅是skb_buff这个结构体
if (!skb)
goto out;
/* Get the DATA. Size must match skb_add_mtu(). */
size = SKB_DATA_ALIGN(size); // 获得线性数据分片长度(注意对齐)
data = kmalloc(size + sizeof(struct skb_shared_info), gfp_mask); // 注意分配的是什么,是size + skb_shared_info!!!!!
if (!data)
goto nodata;
memset(skb, 0, offsetof(struct sk_buff, truesize)); // 初始化
skb->truesize = size + sizeof(struct sk_buff); // 实际大小等于sk_buff + size,刚刚开始还没有非线性数据
atomic_set(&skb->users, 1);
skb->head = data; // 注意指针,这个结合上面的图一清二楚
skb->data = data;
skb->tail = data;
skb->end = data + size;
/* make sure we initialize shinfo sequentially */
shinfo = skb_shinfo(skb);
atomic_set(&shinfo->dataref, 1);
shinfo->nr_frags = 0;
shinfo->tso_size = 0;
shinfo->tso_segs = 0;
shinfo->ufo_size = 0;
shinfo->ip6_frag_id = 0;
shinfo->frag_list = NULL;
if (fclone) {
struct sk_buff *child = skb + 1;
atomic_t *fclone_ref = (atomic_t *) (child + 1);
skb->fclone = SKB_FCLONE_ORIG;
atomic_set(fclone_ref, 1);
child->fclone = SKB_FCLONE_UNAVAILABLE;
}
out:
return skb;
nodata:
kmem_cache_free(cache, skb);
skb = NULL;
goto out;
}那么alloc之后的图就是(图五):
(图五)
其实和图二是一样的!我们可以看到,现在仅仅是分配了线束数据区域,但是现在还没有数据!一定要注意!所以前面三个指针指在一起!因为没有数据,那么len和data_len的值就是0 !
> : skb_reserve函数
static inline void skb_reserve(struct sk_buff *skb, int len)
{
skb->data += len;
skb->tail += len;
}这个函数很重要,是为“协议头”预留空间!而且是尽最大的空间预留,因为很多头都会有可选项,那么我们不知道可选项是多大,所以只能是按照最大的分配,那么也说明了一点,预留的空间headroom也就是不一定都能使用完的!可能还有剩余的,由上面的图也可以看出来!这也是为什么需要这么多指针的问题!那么这个函数直接导致head指针和tail、data指针分离,入下面图六所示:

(图六)
注意headroom就是用来存储各个协议头的足够大的空间,tailroom就可以认为是存储其他线性数据的空间。( 这里不要曲解协议头不是线性数据,其实协议头也是!!!所以当增加头的时候,data指针向上移动,当增加其他数据的时候,tail指针向下移动 )。现在data和tail指向一起,那么还是说明数据没有!!!
> : skb_put函数 ----> 用于操作线性数据区域(tailroom区域)的用户数据
static inline unsigned char *skb_put(struct sk_buff *skb, unsigned int len)
{
unsigned char *tmp = skb->tail;
SKB_LINEAR_ASSERT(skb);
skb->tail += len; // 移动指针
skb->len += len; // 数据空间增大len
if (unlikely(skb->tail>skb->end)) // 如果tail指针超过end指针了,那么处理错误~
skb_over_panic(skb, len, current_text_addr());
return tmp;
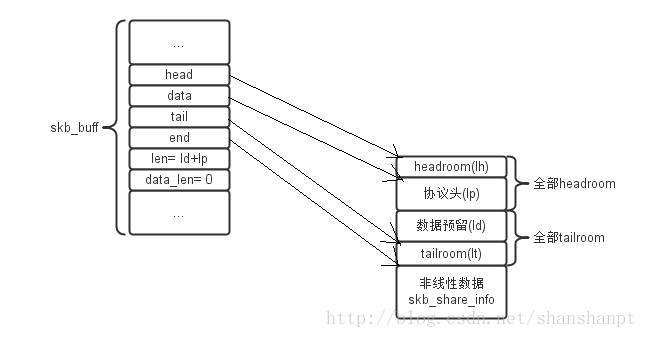
}这函数其实就是从tailroom预留空间,相当于是移动tail指针,这样如果从上图(图六)开始看,也就是tail开始向下移动,和data分离了。。。一般来说,这样做都是为了用户数据再次处理,或者说为TCP/IP的负载预留空间!
看图七,当使用skb_put时候,由图六---->图七

(图七)
我们可以看到指针的移动data还是在headroom的下面,中间的是用户数据预留的部分,由skb_put得到,tail表示数据结尾!再看一下sk_buff中的len,变成了数据长度ld!!
> : skb_push函数:----------> 用于操作headroom区域的协议头
static inline unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
{
skb->data -= len; // 向上移动指针
skb->len += len; // 数据长度增加
if (unlikely(skb->datahead)) // data指针超过head那么就是处理错误~
skb_under_panic(skb, len, current_text_addr());
return skb->data;
} 和skb_put对应,上面试操作用户数据的,这里是操作协议头的!其实就是data指针向上移动而已~注意len增大了哦~前面说了协议头也是属于数据!
如下面图所示,由图七---->图八
(图八)
我们可以知道,data向上移动了,同时注意len变成ld+lp了,其中lp是这个增加的协议头的长度!
> : skb_pull函数:-----------> 其实这个函数才是与skb_push函数对应的函数!因为这是去头函数,而skb_push是增头函数!所以这个函数一般用在解包的时候!
static inline unsigned char *skb_pull(struct sk_buff *skb, unsigned int len)
{
return unlikely(len > skb->len) ? NULL : __skb_pull(skb, len);
}
static inline unsigned char *__pskb_pull(struct sk_buff *skb, unsigned int len)
{
if (len > skb_headlen(skb) &&
!__pskb_pull_tail(skb, len-skb_headlen(skb)))
return NULL;
skb->len -= len; // 长度减小
return skb->data += len; // 移动指针
}其实就是data指针向下移动,当前一个协议头被去掉,headroom剩余的空间增大了!看下图:
由图八---->图九:

(图九)
虚线是data之前的指针位置,现在移动到下面实线!!需注意:len的长度减小,减小的大小是剥去的头的大小!!
四、
最后我们从两条线整体分析一下:
1:从应用层用户数据开始,直到物理层发送出去
> 初始化的什么就不多说了,和前面的差不多,现在也加入用户数据已经在了,如图七所示一样!那么到了TCP层,需要增加
TCP层的头:
如图10所示:

(图10)
需要注意的是这里是传输层,那么传输层的结构u中的th代表的是tcp的头,那么tcp指向tcp头OK!同时注意 len长度+=l1 哦~~~
> 再看到了IP层:如图11

(图11)
至于需要解释什么就没什么了,都是一样的~
> 到链路层了:如图12

(图12)
OK!
2:第二个过程其实是第一个逆过程,都差不多,所以不多说了~
五、
最后看一下操作skb的两个函数pskb_copy和skb_copy
前者仅仅是将sk_buff的结构体和线性数据copy过来,对于非线性数据,是引用原始的skb的数据的!而后者是不仅将sk_buff和线性数据拷贝,同时将非线性数据也copy了一份,看下面就明白了!这就在效率上就差了很多!所以如果不想修改数据,那么还是使用pskb_copy更好!
对于pskb_copy:

对于skb_copy:
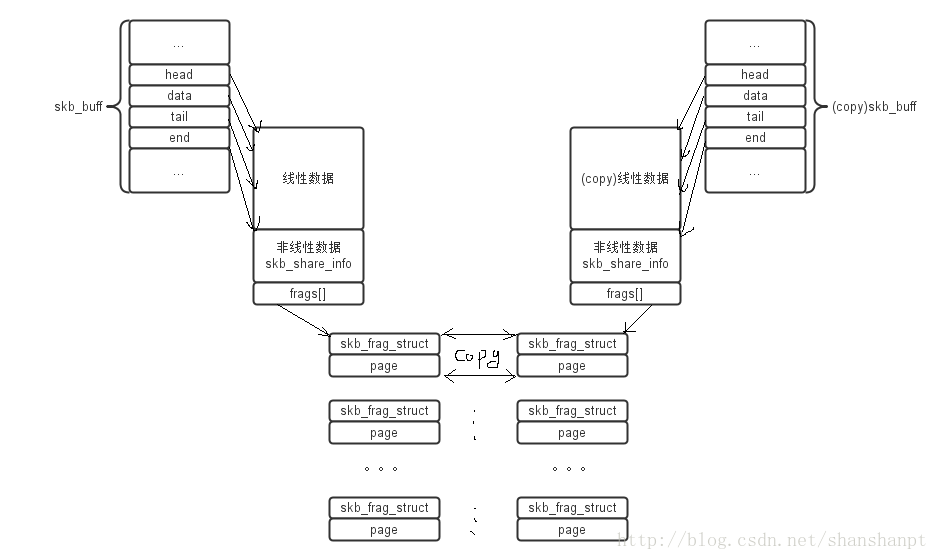
OK 我觉得差不多了~~~~~结束~~~~~~~~~~~~~