docker学习笔记(10):docker迁移与升级等其它操作
引言
上一篇讲解了nvidia-docker中关于nvidia-docker的部署以及一些我遇到的相应错误总结,但最后并没有演示容器开启后的应用与步骤,因为我的理解还不够深,有些东西还是很模糊,而本篇博文想总结的是之前被我忽略掉的,然后想在本篇来个汇总,可能下一篇我就会进入k8s的笔记,所以这里也能成为杂续。
docker迁移与升级
docker迁移
因为我不想另开一帖子写迁移了,如果懂这部分的或者空间够的话,可以跳过这部分。我们可以用docker命令查看当前存储空间,下面日志是在我的腾讯云学生服务器上,没有带nvidia的版本,手头没有带nvidia的空闲服务器使用,有的都在跑不敢动也没这么试过。。。而且因为实际会很大,所以以测试机实验,如果装了nvidia-docker还这么试成功的可以告诉我:
[root@iZwz9dnzb8iugujf36fuw9Z ~]# docker system df
"""
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 3 1 1.019GB 563.1MB (55%)
Containers 1 0 0B 0B
Local Volumes 0 0 0B 0B
Build Cache 0 0 0B 0B
"""
[root@iZwz9dnzb8iugujf36fuw9Z ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@iZwz9dnzb8iugujf36fuw9Z ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
44f42b5c6347 mysql "docker-entrypoint.s…" 9 months ago Created 33060/tcp, 0.0.0.0:5075->3306/tcp cmysql
[root@iZwz9dnzb8iugujf36fuw9Z ~]# docker system prune
WARNING! This will remove:
- all stopped containers
- all networks not used by at least one container
- all dangling images
- all dangling build cache
Are you sure you want to continue? [y/N] y
Deleted Containers:
6b129e4a539bba0f9c88b48843b0d6269005ad55cf227bc262331c00955b25d0
Total reclaimed space: 7B
-
1 docker system df命令,类似于Linux上的df命令,用于查看Docker的磁盘使用情况:
-
2 docker system prune命令可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及无用(无tag)镜像。
-
3 docker system prune -a命令清理得更加彻底,可以将没有容器使用Docker镜像都删掉。注意,这两个命令会把你暂时关闭的容器,以及暂时没有用到的Docker镜像都删掉了。
当然如果想简洁点可以直接du -hs /var/lib/docker/ 命令查看磁盘使用情况。
因为我上面已经没有正在启动的容器了,如果有的话请在运行完prune后停止容器,然后关闭docker,因为下面日志太多就只贴命令了:
systemctl stop docker
mkdir -p /home/docker/lib # 创建本地迁移文件夹
rsync -avz /var/lib/docker /home/docker/lib/ # 迁移数据
# 如果没有 /etc/systemd/system/docker.service.d/ 就创建
sudo mkdir -p /etc/systemd/system/docker.service.d/
sudo vi /etc/systemd/system/docker.service.d/devicemapper.conf
# 在devicemapper.conf文件加上
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd --graph=/home/docker/lib/docker
# 重新加载docker
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
若没有报错,我们可以docker info查看当前更改后的目录:
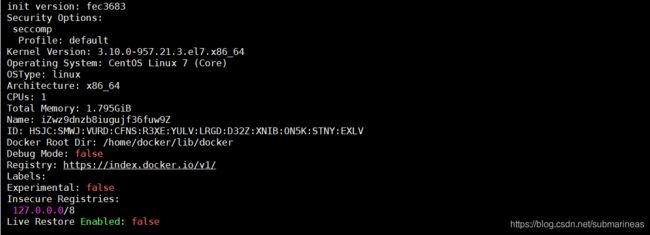
然后如果当时有容器断开的,可以进行重新连接:
[root@iZwz9dnzb8iugujf36fuw9Z home]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@iZwz9dnzb8iugujf36fuw9Z home]# docker restart cmysql
cmysql
[root@iZwz9dnzb8iugujf36fuw9Z home]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9bef8c609c43 mysql "docker-entrypoint.s…" 7 minutes ago Up 2 seconds 3306/tcp, 33060/tcp, 0.0.0.0:8888->8888/tcp cmysql
docker升级迭代
docker升级迭代的方式和迁移一样,可以先运行prune清理一遍空间,容器先要停止,不然无法进行升级,那么接下来就是升级的步骤,这里就不再演示具体的了:
[root@iZwz9dnzb8iugujf36fuw9Z ~]# rpm -qa | grep docker
docker-ce-cli-19.03.5-3.el7.x86_64
docker-ce-19.03.5-3.el7.x86_64
# 有多少就remove多少个
yum remove docker-ce-cli-19.03.5-3.el7.x86_64
yum remove docker-ce-19.03.5-3.el7.x86_64
# yum remove docker-common-19.03.5-3.el7.x86_64
# 因为在之前已经添加过Reso仓库,所以这里只需要拉取最新安装包并下载
curl -fsSL https://get.docker.com/ | sh
# 重启docker
systemctl restart docker
# 设置自启
systemctl enable docker
然后如果之前有迁移过并想升级,再重新安装完docker后,docker images无法看见之前做的镜像,那么再重复做一遍上面的操作,但不需要将新的/var/lib/docker下的数据覆盖进旧的,然后docker info看到目录改变,docker images也就能显示之前镜像。
这里还存在一个问题,如果docker没办法兼容当前服务器,启动各种报错,并并引起宿主机排异,甚至是崩溃的问题,这里同样需要考虑一下升级docker版本与内核,具体错误为:
kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
kernel: [400674] 0 400674 14361 1312 21 0 -998 runc:[2:INIT]
kernel: Memory cgroup out of memory: Kill process 400678 (runc:[2:INIT]) score 0 or sacrifice child
kernel: Killed process 400674 (runc:[2:INIT]) total-vm:57444kB, anon-rss:3616kB, file-rss:1632kB, shmem-rss:0kB
containerd: time="2019-12-19T21:51:12.766784752Z" level=info msg="shim reaped" id=c04ddba2ccfbbb317c96f65f4c9f1b555f2a62f3b31f8d99ed5463833dc2230c
dockerd: time="2019-12-19T21:51:12.776459692Z" level=error msg="stream copy error: reading from a closed fifo"
dockerd: time="2019-12-19T21:51:12.776493528Z" level=error msg="stream copy error: reading from a closed fifo"
dockerd: time="2019-12-19T21:51:12.868654737Z" level=error msg="c04ddba2ccfbbb317c96f65f4c9f1b555f2a62f3b31f8d99ed5463833dc2230c cleanup: failed to delete container from containerd: no such container"
那么解决方法为:
#升级docker版本
yum remove docker docker-engine docker-common \
docker-client docker-client-latest docker-latest docker-latest-logrotate \
docker-logrotate docker-selinux docker-engine-selinux -y
yum install yum-utils lvm2 device-mapper-persistent-data -y
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --disable docker-ce-edge docker-ce-test
yum install docker-ce.x86_64 -y
yum update containerd.io -y
#升级内核版本
yum update kernel.x86_64 -y
docker给容器update与core dump概念
docker update
关于update的用法,docker官网有更多详细的解释:
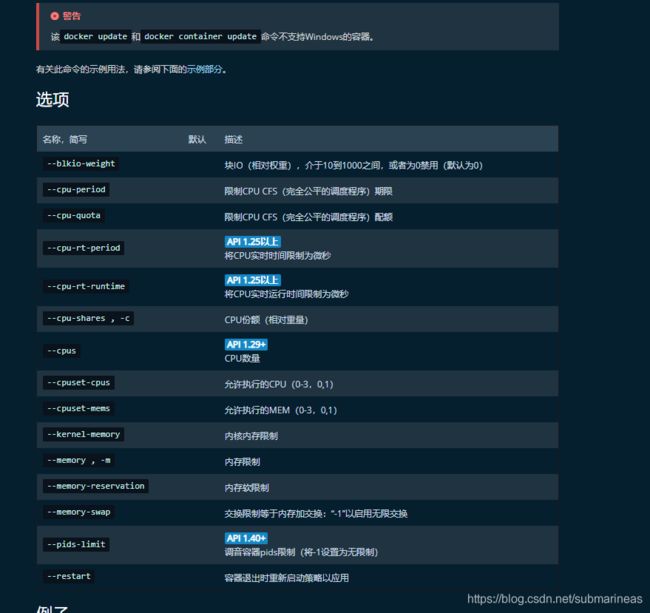
当容器已经启动后,如果想要更新一些参数进去,docker官网指明了可选参数比如CPU的核数,还有内存使用限制等等,而加数据卷等操作是不行的,可能还是得重启镜像了,另外,当我们运行一个和jvm相关的容器,我们想要获取更多的内存而不是限制,那么上面参数可能就不太可行,原因是docker会杀死占用过多资源的jvm而被重启,那么Running a JVM in a Container Without Getting Killed 给出了答案,用:
docker run
--cap-add=SYS_PTRACE
--ulimit core=-1
-m 1648M
-e JAVA_OPTS="
-XX:+UnlockExperimentalVMOptions
-XX:+UseCGroupMemoryLimitForHeap
-XX:MaxRAMPercentage=80.0 // jvm Xmx 占容器内存百分比,示例即Xmx=1648*0.8。此处供参考,自行调试,取值必须为double
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/data/logs/
"
使用-XX:MaxRAMFraction 我们告诉JVM使用可用内存/ MaxRAMFraction作为最大堆。使用-XX:MaxRAMFraction=1我们几乎所有可用的内存作为最大堆。
core dump
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景。
具体可看
Linux下core dump
在 Docker 中产生 Core Dump 文件
我发现这个的原因是,我在用nvidia-docker跑完项目准备转回镜像的时候,发现容器竟然从15个G涨到了30个G,当时我还以为是版本内容layer层没有进行清除,因为docker的机制如果是在原始镜像上进行修改,并产生了2.0、3.0等版本,还是会有1.0的记录,但当我进去查找内存的时候,发现确实是有缓存,但大部分原因来自于项目根目录多了一个core文件,整整12个G,所以了解了一下,在这里mark住。
nvidia-docker部署
在默认已经部署成功的时候,我们可以通过下面几条命令看当前nvidia-docker状态是否开启成功:
sudo systemctl start nvidia-docker.service # 查看nvidia-docker日志
nvidia-container-cli -k -d /dev/tty info # 已经跟GPU关联并successful
nvidia-docker运行容器
这里需要根据需求下载相应的镜像:
docker pull nvidia/cuda:10.2-base-ubuntu16.04
docker pull nvidia/cuda:10.2-runtime-ubuntu16.04
docker pull nvidia/cuda:10.2-devel-ubuntu16.04
docker pull nvidia/cuda:10.2-cudnn7-runtime-ubuntu16.04
docker pull nvidia/cuda:10.2-cudnn7-devel-ubuntu16.04
docker pull nvidia/cuda:10.2-base-ubuntu18.04
docker pull nvidia/cuda:10.2-base
docker pull nvidia/cuda:10.2-runtime-ubuntu18.04
docker pull nvidia/cuda:10.2-runtime
docker pull nvidia/cuda:10.2-devel-ubuntu18.04
docker pull nvidia/cuda:10.2-devel
docker pull nvidia/cuda:10.2-cudnn7-runtime-ubuntu18.04
docker pull nvidia/cuda:10.2-cudnn7-runtime
docker pull nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04
docker pull nvidia/cuda:10.2-cudnn7-devel
docker pull nvidia/cuda:10.2-base-ubi8
docker pull nvidia/cuda:10.2-runtime-ubi8
docker pull nvidia/cuda:10.2-devel-ubi8
docker pull nvidia/cuda:10.2-cudnn7-runtime-ubi8
docker pull nvidia/cuda:10.2-base-ubi7
docker pull nvidia/cuda:10.2-runtime-ubi7
docker pull nvidia/cuda:10.2-devel-ubi7
docker pull nvidia/cuda:10.2-cudnn7-runtime-ubi7
docker pull nvidia/cuda:10.2-cudnn7-devel-ubi8
docker pull nvidia/cuda:10.2-cudnn7-devel-ubi7
docker pull nvidia/cuda:10.2-base-centos7
docker pull nvidia/cuda:10.2-runtime-centos7
docker pull nvidia/cuda:10.2-devel-centos7
docker pull nvidia/cuda:10.2-cudnn7-runtime-centos7
docker pull nvidia/cuda:10.2-base-centos6
docker pull nvidia/cuda:10.2-runtime-centos6
docker pull nvidia/cuda:10.2-devel-centos6
docker pull nvidia/cuda:10.2-cudnn7-runtime-centos6
docker pull nvidia/cuda:10.2-cudnn7-devel-centos7
docker pull nvidia/cuda:10.2-cudnn7-devel-centos6
docker pull nvidia/cuda:10.2-base-ubuntu14.04
docker pull nvidia/cuda:10.2-runtime-ubuntu14.04
docker pull nvidia/cuda:10.2-devel-ubuntu14.04
docker pull nvidia/cuda:10.2-cudnn7-runtime-ubuntu14.04
docker pull nvidia/cuda:10.2-cudnn7-devel-ubuntu14.04
一般我会选择nvidia/cuda:10.2-base镜像,然后做成我需要的容器,而nvidia的服务基本都是ubuntu,所以这里的base也是ubuntu下的最小镜像,另外还用了下cudnn-runtime-ubuntu18.04,我记得是1.78G,和ubuntu的200M形成鲜明对比,我没去仔细看过为什么差距这么大,但共用资源基本一致。而如果要形成能使用的容器,还需要加一些依赖。
关于devel、runtime和base的区别,按照官网的解释为:
- base:从CUDA 9.0开始,包含部署预建CUDA应用程序的最低要求(libcudart)。
如果要手动选择要安装的CUDA软件包,请使用此映像。- runtime:base通过添加CUDA工具包中的所有共享库来扩展图像。
如果您具有使用多个CUDA库的预构建应用程序,请使用此映像。- devel:runtime通过添加编译器工具链,调试工具,标头和静态库来扩展图像。
使用此映像可从源代码编译CUDA应用程序。
ubuntu环境构建
1、GCC——GNU编译器集合(GCC可以使用默认包管理器的仓库(repositories)来安装,包管理器的选择依赖于你使用的Linux发布版本,包管理器有不同的实现:yum是基于Red
Hat的发布版本;apt用于Debian和Ubuntu;yast用于SuSE Linux等等。)
RedHat中安装GCC:
yum install gcc
Ubuntu中安装GCC:
apt-get install gcc
2、PCRE库(Nginx编译需要PCRE(Perl Compatible Regular
Expression),因为Nginx的Rewrite模块和HTTP核心模块会使用到PCRE正则表达式语法。这里需要安装两个安装包pcre和pcre-devel。第一个安装包提供编译版本的库,而第二个提供开发阶段的头文件和编译项目的源代码,这正是我们需要的理由。)
RedHat中安装PCRE:
yum install pcre pcre-devel
Ubuntu中安装PCRE:
apt-get install libpcre3 libpcre3-dev
3、zlib库(zlib库提供了开发人员的压缩算法,在Nginx的各种模块中需要使用gzip压缩。如同安装PCRE一样,同样需要安装库和它的源代码:zlib和zlib-devel。)
RedHat中安装zlib:
yum install zlib zlib-devel
Ubuntu中安装zlib:
apt-get install zlib1g zlib1g-dev
4、OpenSSL库(在Nginx中,如果服务器提供安全网页时则会用到OpenSSL库,我们需要安装库文件和它的开发安装包(openssl和openssl-devel)。)
RedHat中安装OpenSSL:
yum install openssl openssl-devel
Ubuntu中安装OpenSSL:(注:Ubuntu14.04的仓库中没有发现openssl-dev):
apt-get install openssl openssl-dev
另外还有make、cmake等等包都是没有的,如果想更全一点,可以运行如下命令:
yum -y install gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5-devel libidn libidn-devel openssl openssl-devel nss_ldap openldap openldap-devel openldap-clients openldap-servers libxslt-devel libevent-devel ntp libtool-ltdl bison libtool vim-enhanced