pyspider爬取2018年自主招生初审数据
使用pyspider爬取了2018年自主招生的初审通过名单共计153008条数据(不含合肥工业大学宣城校区)
数据分析
数据分析之省市
省份排名前五如下:
| 排名 | 省份 | 人数 |
|---|---|---|
| 1 | 山东省 | 24788 |
| 2 | 江苏省 | 14696 |
| 3 | 河北省 | 13028 |
| 4 | 湖北省 | 10444 |
| 5 | 河南省 | 10199 |
数据分析之中学
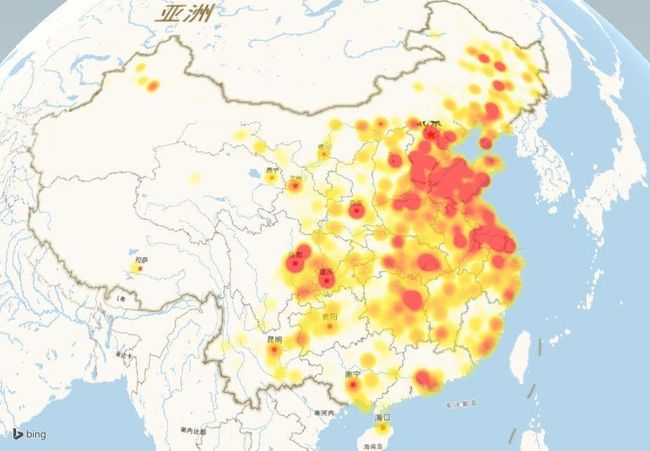
可以看出京津冀以及上海一带人数分布较多。
学校排名前五如下:
| 排名 | 学校 | 人数 |
|---|---|---|
| 1 | 衡水第一中学 | 1152 |
| 2 | 山东省莱芜市第一中学 | 1038 |
| 3 | 山东省实验中学 | 1038 |
| 4 | 石家庄市第二中学 | 938 |
| 5 | 邯郸市第一中学 | 793 |
数据分析之清北

数据分析之性别

源代码之pyspider
pyspider是一个国人编写的强大的网络爬虫系统并带有强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
但是由于url自动去重的原因,常规的编写只能每页返回一条结果,需要通过构造虚拟的url重载send_message以及on_message两个函数来完成单页的多输出
send_message和on_message源码如下:
1 def send_message(self, project, msg, url='data:,on_message'):
2 """Send messages to other project."""
3 self._messages.append((project, msg, url))
4 def on_message(self, project, msg):
5 """Receive message from other project, override me."""
6 pass
官方给出的解释:网页链接
网页地址:http://docs.pyspider.org/en/latest/apis/self.send_message/
1from pyspider.libs.base_handler import *
2class Handler(BaseHandler):
3 crawl_config = {
4 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
5 }
6 @every(minutes=24 * 60)
7 def on_start(self):
8 self.crawl('https://gaokao.chsi.com.cn/zzbm/mdgs/orgs.action?lx=1&a=a', callback=self.index_page, retries=10)
9 @config(age=10 * 24 * 60 * 60)
10 def index_page(self, response):
11 for each in response.doc('td a').items():
12 if 'subOrgs' not in each.attr.href:
13 self.crawl(each.attr.href + '&start=0', callback=self.detail_page, save={'collagename': each.text()},
14 allow_redirects=False, retries=10)
15 else:
16 self.crawl(each.attr.href, callback=self.second_page, allow_redirects=False, retries=10)
17 def second_page(self, response):
18 for each in response.doc('td a').items():
19 self.crawl(each.attr.href + '&start=0', callback=self.detail_page, save={'collagename': each.text()},
20 allow_redirects=False, retries=10)
21 @config(priority=2, age=10 * 24 * 60 * 60)
22 def detail_page(self, response):
23 list_data = response.doc('td').text().split()
24 del list_data[0:4]
25 for each in range(int(len(list_data) / 4)):
26 data_dict = {
27 'collagename': response.save['collagename'],
28 "url": response.url,
29 'name': list_data[each * 4 + 0],
30 'sex': list_data[each * 4 + 1],
31 'schoolname': list_data[each * 4 + 2],
32 'provice': list_data[each * 4 + 3],
33 }
34 self.send_message(self.project_name, data_dict, url="%s#%s" % (response.url, each))
35 for item in response.doc('form > a').items():
36 if item.text() == '下一页>>':
37 self.crawl(item.attr.href, callback=self.detail_page, allow_redirects=False,
38 save={'collagename': response.save['collagename']}, retries=10)
39 def on_message(self, project, msg):
40 return msg
源代码之经纬度
通过对接百度地图或者谷歌地图的api接口,可以轻松获取学校的经纬度信息。
api接口函数如下:
1import requests,time,random,csv,json
2def lon_lat_request_bd(address):#百度地图api接口
3 try:
4 url= 'http://api.map.baidu.com/geocoder?output=json&key=OBVgfrY37VoctmdWOCrCWDjw3EuGuomK&address='+str(address)
5 response = requests.get(url)
6 answer = response.json()
7 lon = float(answer['result']['location']['lng'])
8 lat = float(answer['result']['location']['lat'])
9 return (lon,lat)
10 except:
11 with open('wu_school_name.text','a',encoding='utf8') as file:
12 file.write(address+'\n')
13def lon_lat_request_gd(address):#高德地图api接口
14 try:
15 url= 'http://restapi.amap.com/v3/geocode/geo?key=ce11503ca47b2ce6d5d16b172ccc3fff&address='+str(address)
16 response = requests.get(url)
17 answer = response.json()
18 location = list(map(float,answer['geocodes'][0]['location'].split(',')))
19 lon = location[0]
20 lat = location[1]
21 print(lon,lat,address+'正在采集中')
22 return (lon,lat)
23 except:
24 with open('wu_school_name.text','a',encoding='utf8') as file:
25 file.write(address+'\n')
主代码如下:
1school_name_dict = {}
2school_loc = {}
3with open('zzzs_school_loc.js','w') as schoolfile_loc:
4 with open('zzzs_school_number.js','w',encoding='utf8') as schoolfile_number:
5 with open('zzzs.csv','r',encoding='utf8') as csvfile:
6 reader = csv.reader(csvfile)
7 for row in reader:
8 school_name = row[4]
9 if school_name != 'schoolname':
10 if school_name in school_name_dict:
11 school_name_dict[school_name] = school_name_dict[school_name] +1
12 else:
13 school_name_dict[school_name] = 1
14 for address in school_name_dict:
15 school_loc[address] = lon_lat_request_gd(address)
16 print(1)
17 json.dump(school_loc, schoolfile_loc)
18 json.dump(school_name_dict,schoolfile_number)
19 print('加载入完成……')
后续数据处理均使用Excel数据透视表以及相应的插件完成,故无代码。
数据来源:阳光高考网自主招生公示平台
文案:幻华