Redis -- 高频面试题
文章目录
-
- 1. Redis 默认数据库数量
- 2. Redis是单线程的,为什么那么快
- 3. 原子性
- 4. List
- 5. Redis的事务定义
- 6. Multi、Exec、discard
- 7. 悲观锁和乐观锁
- 8. WATCH 与 unwatch
- 9. 三特性
- 10. 数据持久化
- 11. 主从复制
- 12. 薪火相传
- 13. 哨兵模式(sentinel)
- 14. 什么是Redis集群
- 15. 什么是slots
- 16. Redis集群的好处:
- 17. Redis集群的不足:
- 18 . 缓存穿透、缓存雪崩、缓存击穿
1. Redis 默认数据库数量
默认16个数据库,类似数组下标从0开始,初始默认使用0号库
统一密码管理,所有库都是同样密码,要么都OK要么一个也连接不上。
2. Redis是单线程的,为什么那么快
1)完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
2)数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的
3)采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不
用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
4)使用多路I/O复用模型,非阻塞IO
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll和epoll函
数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正
的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
5)使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了
VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
3. 原子性
所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何
context switch (切换到另一个线程)。
(1) 在单线程中, 能够在单条指令中完成的操作都可以认为是" 原子操作",因为中断只能发生于指令之间。
(2)在多线程中,不能被其它进程(线程)打断的操作就叫原子操作。
Redis单命令的原子性主要得益于Redis的单线程
4. List
1) 单键多值
2) Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
3) 它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
5. Redis的事务定义
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis事务的主要作用就是串联多个命令防止别的命令插队
6. Multi、Exec、discard
1) 从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,至到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
2) 组队的过程中可以通过discard来放弃组队。
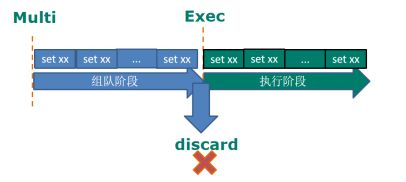
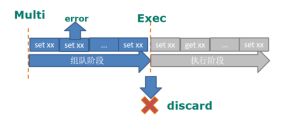
组队中某个命令出现了报告错误,执行时整个的所有队列会都会被取消。
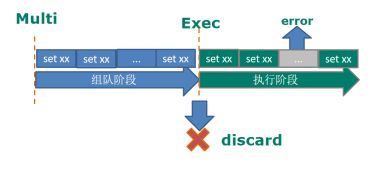
如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
7. 悲观锁和乐观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿
数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多
这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,
但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的
应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
8. WATCH 与 unwatch
Watch : 在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前
这个(或这些) key 被其他命令所改动,那么事务将被打断。
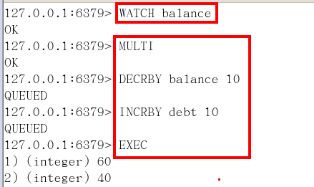
Unwatch :
1)取消 WATCH 命令对所有 key 的监视。
2)如果在执行 WATCH 命令之后, EXEC 命令或 DISCARD 命令先被执行了的话,那么就不需要再执行 UNWATCH 了。
9. 三特性
1) 单独的隔离操作
事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
2) 没有隔离级别的概念
队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在
“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题
3) 不保证原子性
Redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
10. 数据持久化
1)RDB持久化:
① 在指定的时间间隔内持久化
② 服务shutdown会自动持久化
③ 输入bgsave也会持久化
优点:
1. 节省磁盘空间
2. 恢复速度快
缺点:
1. 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
2. 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
2)AOF : 以日志形式记录每个更新操作
Redis重新启动时读取这个文件,重新执行新建、修改数据的命令恢复数据。
保存策略:
推荐(并且也是默认)的措施为每秒持久化一次,这种策略可以兼顾速度和安全性。
优点:
备份机制更稳健,丢失数据概率更低。
可读的日志文本,通过操作AOF稳健,可以处理误操作。
缺点:
1 比起RDB占用更多的磁盘空间
2 恢复备份速度要慢
3 每次读写都同步的话,有一定的性能压力
4 存在个别Bug,造成恢复不能
11. 主从复制
主从复制,就是主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
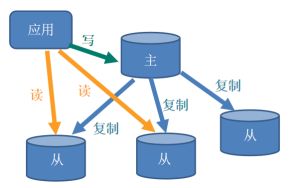
用处 :
1. 读写分离,性能扩展
2. 容灾快速恢复
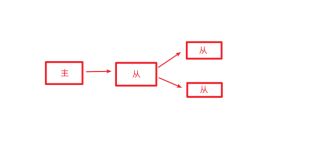
12. 薪火相传
1) 上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave
作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
2) 用 slaveof
3) 中途变更转向:会清除之前的数据,重新建立拷贝最新的
4) 风险是一旦某个slave宕机,后面的slave都没法备份
13. 哨兵模式(sentinel)
如果主机Down掉,哨兵会从从机中选择一台作为主机,并将它设置为其他从机的主机,而且如果原来的主机再次
启动的话也会成为从机。
14. 什么是Redis集群
1. Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点
存储总数据的1/N。
2. Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效
或者无法进行通讯, 集群也可以继续处理命令请求。
15. 什么是slots
1. 一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中
一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键
key 的 CRC16 校验和 。
2. 集群中的每个节点负责处理一部分插槽。
16. Redis集群的好处:
1.实现扩容
2.分摊压力
3.无中心配置相对简单
17. Redis集群的不足:
1. 多键操作是不被支持的
2. 多键的Redis事务是不被支持的。lua脚本不被支持。
3. 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
18 . 缓存穿透、缓存雪崩、缓存击穿
1)缓存穿透是指查询一个一定不存在的数据。由于缓存命不中时会去查询数据库,查不到数据则不写入缓存,这将导致这个
不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
解决方案:
①是将空对象也缓存起来,并给它设置一个很短的过期时间,最长不超过5分钟
② 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,
从而避免了对底层存储系统的查询压力
2)如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,就会造成缓存雪崩。
解决方案:
尽量让失效的时间点不分布在同一个时间点
3)缓存击穿,是指一个key非常热点,在不停的扛着大并发,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求
数据库,就像在一个屏障上凿开了一个洞。
解决方案:
可以设置key永不过期