Nginx+Keepalived+LVS高可用集群----相关知识回顾
1、原理回顾
1.1、集群知识回顾
集群特点:
1)高性能performance。 一些需要很强的运算处理能力比如天气预报,核试验等。这需要上千台计算器协同来完成这个工作的,共同分担计算任务。
2)价格相对便宜且可集中管理: 通常一套系统集群架构,只需要几台或数十台服务器主机即可,且这些计算机的性能实际使用中也不必太高,甚至可利旧老式的服务器,与动则上百王的专用超级计算机具有更高的性价比。
3)弹性伸缩性: 当服务器负载压力增长的时候,系统扩展将变得相对容易,从而来满足业务增长需求,且不降低服务质量。
4)高可用性: 尽管部分硬件和软件发生故障,整个系统的服务必须是7*24小时运行的,集群内成员节点故障对用户透明。一部分服务器宕机了业务不受影响,一般耦合度没有那么高,依赖关系没有那么高。
********************************* 集群架构按照功能和结构一般分以下几类*****************************
1)负载均衡集群(Loadbalancingclusters)简称LBC
2)高可用性集群(High-availabilityclusters)简称HAC
3)高性能计算集群(High-perfomanceclusters)简称HPC
4)网格计算(Gridcomputing)
常主要用前三个,负载均衡和高可用集群式在互联网行业尤其是最常用的集群架构。
(1)负载均衡集群
负载均衡集群为:把很多客户集中访问的请求负载压力可能尽可能平均的分摊到计算机集群中处理。客户请求负载通常包括应用程度处理负载和网络流量负载。这样的系统非常适合向使用同一组应用程序为大量用户提供服务。每个节点都可以承担一定的访问请求负载压力,并且可以实现访问请求在各节点之间动态分配,以实现负载均衡。从而实现集群分担访问流量(负载均衡)和保持业务的连续性(高可用)。
负载均衡集群的实现方式,一般通过一个或多个前端负载均衡器将客户访问请求分发到后端一组服务器(即我们的RS上:真实服务器)上,从而达到整个系统的高性能和高可用性。一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点。
(2)高可用性集群
一般是指当集群中的任意一个节点失效的情况下,节点上的所有任务自动转移到其他正常的节点上,并且此过程不影响整个集群的运行,不影响业务的正常对外访问。
这类集群中通常运行着两个或两个以上的一样的节点,当某个主节点出现故障的时候,那么其他作为从 节点的节点就会自动接替主节点上面的任务。从节点可以接管主节点的资源(IP地址,架构身份等),此时用户不会发现提供服务的对象从主节点转移到从节点。
高可用性集群的作用:当一个机器宕机另一台进行接管,对用户透明。比较常用的高可用集群开源软件有:keepalive,heardbeat。
(3)高性能计算集群
高性能计算集群采用将计算任务分配到集群的不同计算节点儿提高计算能力,因而主要应用在科学计算领域。比较流行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算。这一集群配置通常被称为Beowulf集群。这类集群通常运行特定的程序以发挥HPCcluster的并行能力。这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI库。HPC集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它节点计算结果的情况。
常用集群软硬件:
常用开源集群软件有:lvs,keepalived,haproxy,nginx,apache,heartbeat
常用商业集群硬件有:F5,Netscaler,Radware,A10
1.2、LVS原理
LVS(linux virtual server)linux虚拟服务器,是一个虚拟的服务器集群系统,可以在unix/linux平台下实现负载均衡集群功能。该项目在1998年5月由我国章文嵩博士组织成立。该集群基于IP层和基于内容请求分发的负载平衡调度解决方法,并在Linux内核中实现了这些方法,将一组服务器构成一个实现可伸缩的、高可用网络服务的虚拟服务器。
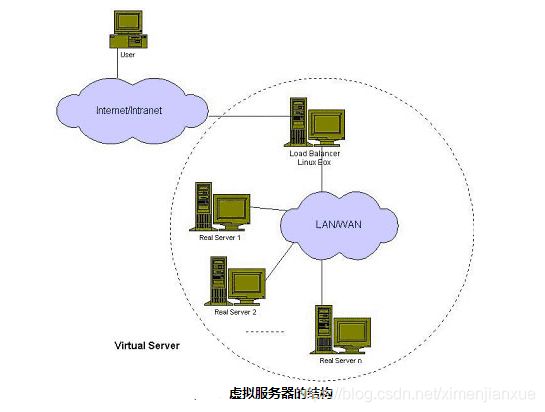
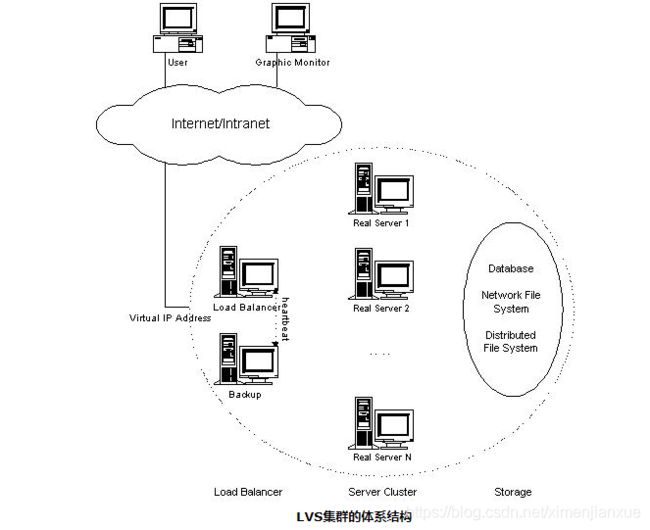
如上图所示,一组服务器通过高速的局域网或者地理分布的广域网相互连接,在它们的前端有一个负载调度器(Load Balancer)(负载调度器能够支持绝大多数的TCP和UDP协议)。负载调度器能无缝地将网络请求调度到真实服务器上,从而使得服务器集群的结构对客户是透明的,客户访问集群系统提供的网络服务就像访问一台高性能、高可用的服务器一样。客户程序不受服务器集群的影响不需作任何修改。系统的伸缩性通过在服务机群中透明地加入和删除一个节点来达到,该集群中通过检测节点或服务进程故障和正确地重置系统达到高可用性。由于该方案负载调度技术是在Linux内核中实现的,章教授团队为之起名为Linux虚拟服务器(Linux Virtual Server)。LVS提供了一个实现可伸缩网络服务的Linux Virtual Server框架。
一般来说,LVS集群采用三层结构,层与层之间相互独立,每一个层次提供不同的功能,但三者会通过高速网络相连接,如100Mbps交换网络、Myrinet和Gigabit网络等。使用高速的网络,主要为避免当系统规模扩大时互联网络成为整个系统的瓶颈。
负载调度器(load balancer),它是整个集群对外面的前端机,负责将客户的请求发送到一组服务器上执行,而客户认为服务是来自一个IP地址(我们可称之为虚拟IP地址)上的,即我们的VIP(虚拟IP地址)。调度器是服务器集群系统的唯一入口点(Single Entry Point),它可以采用IP负载均衡技术、基于内容请求分发技术或者两者相结合。在基于内容请求分发技术中,服务器可以提供不同的服务,当客户请求到达时,调度器可根据请求的内容选择服务器 执行请求。因为所有的操作都是在Linux操作系统核心空间中将完成的,它的调度开销很小,所以它具有很高的吞吐率。另外,为保证集群的高可用,调度器上有资源监测进程来时刻监视各个服务器结点的健康状况。当服务器对ICMP ping不可达时或者探测她的网络服务在指定的时间没有响应时,资源监测进程通知操作系统内核将该服务器从调度列表中删除或者失效。这样,新的服务请求就 不会被调度到坏的结点。资源监测进程能通过电子邮件或传呼机向管理员报告故障。一旦监测进程到服务器恢复工作,通知调度器将其加入调度列表进行调度。另 外,通过系统提供的管理程序,管理员可发命令随时可以将新机器加入服务来提高系统的处理性能,针对调度器本身,一般也设置主从结构,保证DR的高可用,集群DR上配置两个心跳(Heartbeat)进程[分别在主、从调度器上运行,它们通过串口线和UDP等心跳线来相互定时地汇报各自的健康状况。当从调度器不能听得主调度器的心跳时,从调度器通过ARP欺骗 (Gratuitous ARP)来接管集群对外的Virtual IP Address,同时接管主调度器的工作来提供负载调度服务。当主调度器恢复时,这里有两种方法,一是主调度器自动变成从调度器,二是从调度器释放 Virtual IP Address,主调度器收回Virtual IP Address并提供负载调度服务。这里,多条心跳线可以使得因心跳线故障导致误判(即从调度器认为主调度器已经失效,其实主调度器还在正常工作)。另外为了防止主DR宕机切换从DR时,用户会话/已建立连接的状态丢失,LVS调度器在Linux 内核中实现一种高效状态同步机制,将主调度器的状态信息及时地同步到从调度器。当从调度器接管时,绝大部分用户已建立的连接会持续下去。
服务器池(server pool),是一组真正执行客户请求的服务器,执行的服务有WEB、MAIL、FTP和DNS等。根据业务不同峰值,可弹性扩展服务器池,整个系统的性能基本上可以随着服务器池的结点数目增加而线性增长。
共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务;共享存储通常是数据库、网络文件系统或者分布式文件系统。动态更新的数据一般存储在数据库系统中,同时数据库会保证并发 访问时数据的一致性。静态的数据可以存储在网络文件系统(如NFS/CIFS)中,但网络文件系统的伸缩能力有限,一般来说,NFS/CIFS服务器只能支持3~6个繁忙的服务器结点。对于规模较大的集群系统,可以考虑用分布式文件系统,如AFS、GFS、Coda和 Intermezzo等。分布式文件系统可为各服务器提供共享的存储区,它们访问分布式文件系统就像访问本地文件系统一样,同时分布式文件系统可提供良好的伸缩性和可用性。此外,当不同服务器上的应用程序同时读写访问分布式文件系统上同一资源时,应用程序的访问冲突需要消解才能使得资源处于一致状 态。这需要一个分布式锁管理器(Distributed Lock Manager),它可能是分布式文件系统内部提供的,也可能是外部的。开发者在写应用程序时,可以使用分布式锁管理器来保证应用程序在不同结点上并发访 问的一致性。之所以使用共享存储,是考虑到当网络服务需要有相同的内容,非共享架构中每台服务器需要将相同的内容复制到本地硬盘上。当系统存储的内容越多,这种无共享结构(Shared-nothing Structure)的代价越大,因为每台服务器需要一样大的存储空间,任何的更新需要涉及到每台服务器,系统的维护代价会非常高。
Graphic Monitor是为系统管理员提供整个集群系统的监视器,它可以监视系统的状态。Graphic Monitor是基于浏览器的,所以无论管理员在本地还是异地都可以监测系统的状况。为了安全的原因,浏览器要通过HTTPS(Secure HTTP)协议和身份认证后,才能进行系统监测,并进行系统的配置和管理。
在LVS框架中,提供了含有三种IP负载均衡技术的IP虚拟服务器软件IPVS、基于内容请求分发的内核Layer-7交 换机KTCPVS和集群管理软件。可以利用LVS框架实现高可伸缩的、高可用的Web、Cache、Mail和Media等网络服务;在此基础上,可以开 发支持庞大用户数的、高可伸缩的、高可用的电子商务应用。LVS服务器集群系统具有良好的伸缩性,可支持几百万个并发连接。配置100M网卡,采用VS/TUN或VS/DR调度技术,集群系统的吞吐量可高达1Gbits/s;如配置千兆网卡,则系统的最大吞吐量可接近10Gbits/s。LVS集群系统已被应用于很多重负载的站点。
LVS:Linux Vritual Server项目的主页(http://www.LinuxVirtualServer.org/
这里我们在Linux平台主要应用IPvs软件实现,从2.4.24以后IPVS已经成为linux官方标准内核的一部分;IPVS软件实现了这三种IP负载均衡技术:
Virtual Server via Network Address Translation(VS/NAT)
通过网络地址转换,调度器重写请求报文的目标地址,根据预设的调度算法,将请求分派给后端的真实服务器;真实服务器的响应报文通过调度器时,报文的源地址被重写,再返回给客户,完成整个负载调度过程。
Virtual Server via IP Tunneling(LVS/TUN)
采用NAT技术时,由于请求和响应报文都必须经过调度器地址重写,当客户请求越来越多时,调度器的处理能力将成为瓶颈。为了解决这个问题,调度器把请求报文通过IP隧道转发至真实服务器,而真实服务器将响应直接返回给客户,所以调度器只处理请求报文。由于一般网络服务应答比请求报文大许多,采用 LVS/TUN技术后,集群系统的最大吞吐量可以提高10倍。
Virtual Server via Direct Routing(LVS/DR)
DR通过改写请求报文的MAC地址,将请求发送到真实服务器,而真实服务器将响应直接返回给客户。同LVS/TUN技术一样,LVS/DR技术可极大地提高集群系统的伸缩性。这种方法没有IP隧道的开销,对集群中的真实服务器也没有必须支持IP隧道协议的要求,但是要求调度器与真实服务器都有一块网卡连在同一物理网段上。
针对不同的网络服务需求和服务器配置,IPVS调度器实现了如下八种负载调度算法:
轮循(Round Robin)
调度器通过"轮叫"调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。
加权轮循(Weighted Round Robin)
调度器通过"加权轮叫"调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
最少链接(Least Connections)
调度器通过"最少连接"调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用"最小连接"调度算法可以较好地均衡负载。
加权最少链接(Weighted Least Connections)
在集群系统中的服务器性能差异较大的情况下,调度器采用"加权最少链接"调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
基于局部性的最少链接(Locality-Based Least Connections)
“基于局部性的最少链接” 调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器 是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用"最少链接"的原则选出一个可用的服务 器,将请求发送到该服务器。
带复制的基于局部性最少链接(Locality-Based Least Connections with Replication)
"带复制的基于局部性最少链接"调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个 目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务 器组,按"最小连接"原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器,若服务器超载;则按"最小连接"原则从这个集群中选出一 台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的 程度。
目标地址散列(Destination Hashing)
"目标地址散列"调度算法根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
源地址散列(Source Hashing)
"源地址散列"调度算法根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
1.3 LVS集群架构案例
1.3.1、可伸缩Web服务

第一层是负载调度器,一般采用IP负载均衡技术,可以使得整个系统有较高的吞吐率;第二层是 Web服务器池,在每个结点上可以分别运行HTTP服务或HTTPS服务、或者两者都运行;第三层是共享存储,它可以是数据库,可以是网络文件系统或分布 式文件系统,或者是三者的混合。集群中各结点是通过高速网络相连接的。
1.3.2、可伸缩媒体服务
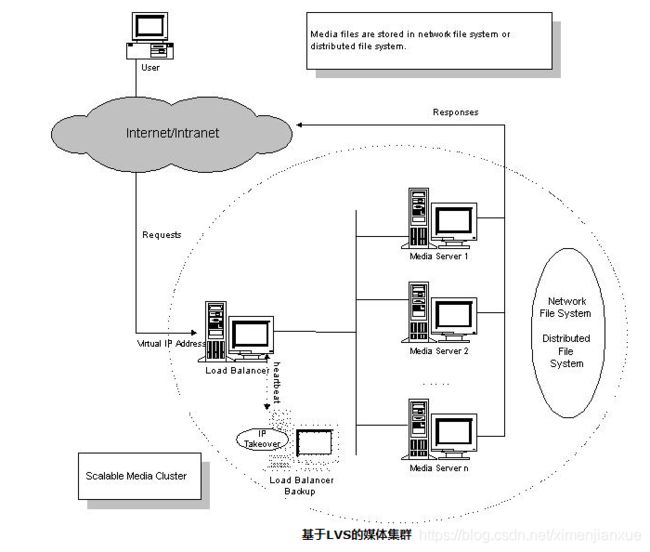
IPVS负载调度器一般使用直接路由方法(即LVS/DR方法,),来架构媒体集群系统。调度器将媒体服务请求较均衡地分发到 各个服务器上,而媒体服务器将响应数据直接返回给客户,这样可以使得整个媒体集群系统具有很好的伸缩性。
媒体服务器可以运行各种媒体服务软件。目前,LVS集群对于Real Media、Windows Media和Apple Quicktime媒体服务都有很好的支持,都有真实的系统在运行。一般来说,流媒体服务都会使用一个TCP连接(如RTSP协议:Real-Time Streaming Protocol)进行带宽的协商和流速的控制,通过UDP将流数据返回客户。这里,IPVS调度器提供功能将TCP和UDP集中考虑,保证来自同一客户 的媒体TCP和UDP连接会被转发到集群中同一台媒体服务器,使得媒体服务准确无误地进行。
共享存储是媒体集群系统中最关键的问题,因为媒体文件往往非常大(一部片子需要几百兆到几千兆的存储空间),这对存储的容量和读的速度 有较高的要求。对于规模较小的媒体集群系统,例如有3至6个媒体服务器结点,存储系统可以考虑用带千兆网卡的Linux服务器,使用软件RAID和日志型 文件系统,再运行内核的NFS服务;对于规模较大的媒体集群系统,最好选择对文件分段(File Stripping)存储和文件缓存有较好支持的分布式文件系统;媒体文件分段存储在分布式文件系统的多个存储结点上,可以提高文件系统的性能和存储结点 间的负载均衡;媒体文件在媒体服务器上自动地被缓存,可提高文件的访问速度。
1.3.3、可伸缩Cache服务

第一层是负载调度器,一般采用IP负载均衡技术,可以使得整个系统有较高的吞吐率; 第二层是Cache服务器池,一般Cache服务器放置在接近主干Internet连接处,它们可以分布在不同的网络中。调度器可以有多个,放在离客户接 近的地方。
IPVS负载调度器一般使用IP隧道方法(即VS/TUN方法,将在以后文章中详细叙述),来架构Cache集群系统,因为Cache服务器可能被 放置不同的地方(例如在接近主干Internet连接处),而调度器与Cache服务器池可能不在同一个物理网络中。采用VS/TUN方法,调度器只调度 Web Cache请求,而Cache服务器将响应数据直接返回给客户。在请求对象不能在本地命中的情况下,Cache服务器要向源服务器发请求,将结果取回,最 后将结果返回给客户;若采用NAT技术的商品化调度器,需要四次进出调度器,完成这个请求。而用VS/TUN方法(或者VS/DR方法),调度器只调度一 次请求,其他三次都由Cache服务器直接访问Internet完成。所以,这种方法对Cache集群系统特别有效。
Cache服务器采用本地硬盘来存储可缓存的对象,因为存储可缓存的对象是写操作,且占有一定的比例,通过本地硬盘可以提高I/O的访 问速度。Cache服务器间有专用的多播通道(Multicast Channel),通过ICP协议(Internet Cache Protocol)来交互信息。当一台Cache服务器在本地硬盘中未命中当前请求时,它可以通过ICP查询其他Cache服务器是否有请求对象的副本, 若存在,则从邻近的Cache服务器取该对象的副本,这样可以进一步提高Cache服务的命中率。
1.3.4、可伸缩邮件服务

前端是一个采用IP负载均衡技术的负载调度器;第二层 是服务器池,有LDAP(Light-weight Directory Access Protocol)服务器和一组邮件服务器。第三层是数据存储,通过分布式文件系统来存储用户的邮件。集群中各结点是通过高速网络相连接。
用户的信息如用户名、口令、主目录和邮件容量限额等存储在LDAP服务器中,可以通过HTTPS让管理员进行用户管理。在各个邮件服务 器上运行SMTP(Simple Mail Transfer Protocol)、POP3(Post Office Protocol version 3)、IMAP4(Internet Message Access Protocol version 4)和HTTP/HTTPS服务。SMTP接受和转发用户的邮件,SMTP服务进程查询LDAP服务器获得用户信息,再存储邮件。POP3和IMAP4通 过LDAP服务器获得用户信息,口令验证后,处理用户的邮件访问请求。这里,需要有机制避免不同服务器上的SMTP、POP3和IMAP4服务进程对用户 邮件的读写冲突。HTTP/HTTPS服务是让用户通过浏览器可以访问邮件。
IPVS调度器将SMTP、POP3、IMAP4和HTTP/HTTPS请求流负载较均衡地分发到各邮件服务器上,从上面各服务的处理 流程来看,不管请求被发送到哪一台邮件服务器处理,其结果是一样的。这里,将SMTP、POP3、IMAP4和HTTP/HTTPS运行在各个邮件服务器 上进行集中调度,有利于提高整个系统的资源利用率。
系统中可能的瓶颈是LDAP服务器,对LDAP服务中B+树的参数进行优化,再结合高端的服务器,可以获得较高的性能。若分布式文件系 统没有多个存储结点间的负载均衡机制,则需要相应的邮件迁移机制来避免邮件访问的倾斜。
1.3.5、NAT实现虚拟服务器(LVS/NAT)
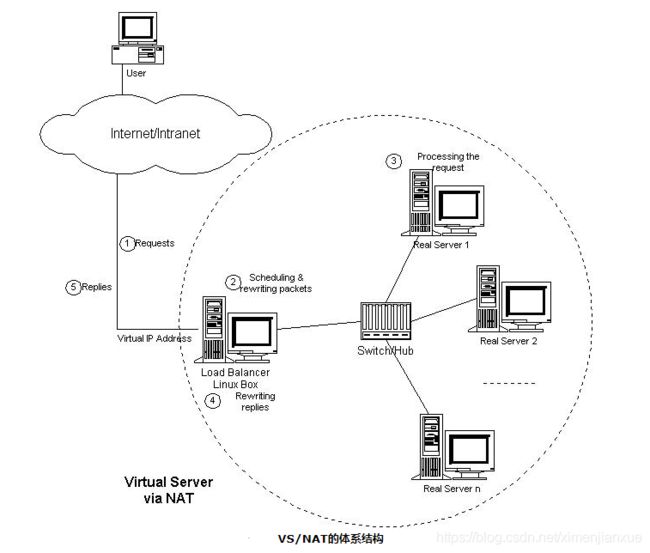
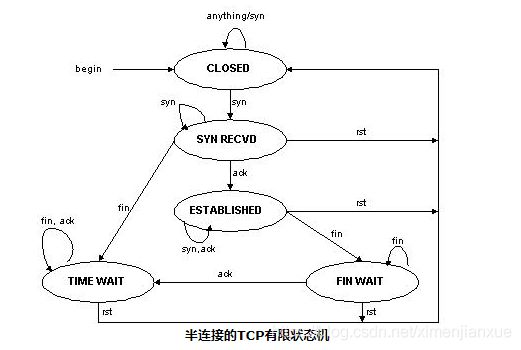
在一组服务器前有一个调度器,它们是通过Switch/HUB相连接的。这些服务器 提供相同的网络服务、相同的内容,即不管请求被发送到哪一台服务器,执行结果是一样的。服务的内容可以复制到每台服务器的本地硬盘上,可以通过网络文件系 统(如NFS)共享,也可以通过一个分布式文件系统来提供。客户通过Virtual IP Address(虚拟服务的IP地址)访问网络服务时,请求报文到达调度器,调度器根据连接调度算法从一组真实服务器中选出一台服务器,将报文的目标地址 Virtual IP Address改写成选定服务器的地址,报文的目标端口改写成选定服务器的相应端口,最后将修改后的报文发送给选出的服务器。同时,调度器在连接Hash 表中记录这个连接,当这个连接的下一个报文到达时,从连接Hash表中可以得到原选定服务器的地址和端口,进行同样的改写操作,并将报文传给原选定的服务 器。当来自真实服务器的响应报文经过调度器时,调度器将报文的源地址和源端口改为Virtual IP Address和相应的端口,再把报文发给用户。我们在连接上引入一个状态机,不同的报文会使得连接处于不同的状态,不同的状态有不同的超时值。在TCP 连接中,根据标准的TCP有限状态机进行状态迁移,这里我们不一一叙述,请参见W. Richard Stevens的《TCP/IP Illustrated Volume I》;在UDP中,我们只设置一个UDP状态。不同状态的超时值是可以设置的,在缺省情况下,SYN状态的超时为1分钟,ESTABLISHED状态的超 时为15分钟,FIN状态的超时为1分钟;UDP状态的超时为5分钟。当连接终止或超时,调度器将这个连接从连接Hash表中删除。
这样,客户所看到的只是在Virtual IP Address上提供的服务,而服务器集群的结构对用户是透明的。对改写后的报文,应用增量调整Checksum的算法调整TCP Checksum的值,避免了扫描整个报文来计算Checksum的开销。
在 一些网络服务中,它们将IP地址或者端口号在报文的数据中传送,若我们只对报文头的IP地址和端口号作转换,这样就会出现不一致性,服务会中断。所以,针 对这些服务,需要编写相应的应用模块来转换报文数据中的IP地址或者端口号。我们所知道有这个问题的网络服务有FTP、IRC、H.323、 CUSeeMe、Real Audio、Real Video、Vxtreme / Vosiac、VDOLive、VIVOActive、True Speech、RSTP、PPTP、StreamWorks、NTT AudioLink、NTT SoftwareVision、Yamaha MIDPlug、iChat Pager、Quake和Diablo。
1.3.6、通过IP隧道实现虚拟服务器(LVS/TUN)

在VS/NAT 的集群系统中,请求和响应的数据报文都需要通过负载调度器,当真实服务器的数目在10台和20台之间时,负载调度器将成为整个集群系统的新瓶颈。大多数 Internet服务都有这样的特点:请求报文较短而响应报文往往包含大量的数据。如果能将请求和响应分开处理,即在负载调度器中只负责调度请求而响应直 接返回给客户,将极大地提高整个集群系统的吞吐量。
IP隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,这可以使得目标为一个IP地址的数据报文能被封装和转发到另一个IP地址。IP隧道技 术亦称为IP封装技术(IP encapsulation)。IP隧道主要用于移动主机和虚拟私有网络(Virtual Private Network),在其中隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址。
我们利用IP隧道技术将请求报文封装转 发给后端服务器,响应报文能从后端服务器直接返回给客户。但在这里,后端服务器有一组而非一个,所以我们不可能静态地建立一一对应的隧道,而是动态地选择 一台服务器,将请求报文封装和转发给选出的服务器。这样,我们可以利用IP隧道的原理将一组服务器上的网络服务组成在一个IP地址上的虚拟网络服务。 VS/TUN的体系结构如图4所示,各个服务器将VIP地址配置在自己的IP隧道设备上。

VS/TUN 的工作流程如上图所示:它的连接调度和管理与VS/NAT中的一样,只是它的报文转发方法不同。调度器根据各个服务器的负载情况,动态地选择一台服务器, 将请求报文封装在另一个IP报文中,再将封装后的IP报文转发给选出的服务器;服务器收到报文后,先将报文解封获得原来目标地址为VIP的报文,服务器发 现VIP地址被配置在本地的IP隧道设备上,所以就处理这个请求,然后根据路由表将响应报文直接返回给客户。
根据缺省的TCP/IP协议栈处理,请求报文的目标地址为VIP,响应报文的源地址肯定也为VIP,所以响应报文不需要作任何修改,可以直接返回给客户,客户认为得到正常的服务,而不会知道究竟是哪一台服务器处理的。
1.3.7、通过直接路由实现虚拟服务器(LVS/DR)

VS/DR利用大多数Internet服务的非对称特点,负载调度器中只负责调度请求,而服务器直接将响应返回给客户,可以极大地提高整个集群 系统的吞吐量。该方法与IBM的NetDispatcher产品中使用的方法类似(其中服务器上的IP地址配置方法是相似的),但IBM的 NetDispatcher是非常昂贵的商品化产品,我们也不知道它内部所使用的机制,其中有些是IBM的专利。
VS/DR的体系结构如图 所示:调度器和服务器组都必须在物理上有一个网卡通过不分断的局域网相连,如通过高速的交换机或者HUB相连。VIP地址为调度器和服务器组共享,调度 器配置的VIP地址是对外可见的,用于接收虚拟服务的请求报文;所有的服务器把VIP地址配置在各自的Non-ARP网络设备上,它对外面是不可见的,只 是用于处理目标地址为VIP的网络请求。
所示:调度器和服务器组都必须在物理上有一个网卡通过不分断的局域网相连,如通过高速的交换机或者HUB相连。VIP地址为调度器和服务器组共享,调度 器配置的VIP地址是对外可见的,用于接收虚拟服务的请求报文;所有的服务器把VIP地址配置在各自的Non-ARP网络设备上,它对外面是不可见的,只 是用于处理目标地址为VIP的网络请求。
2、LVS+keepalived实现负载均衡&高可用
3、
待整理中……………………