并发包学习笔记
并发编程学习推荐:http://www.jianshu.com/u/42116042245c
BlockingQueue
ArrayBlockingQueue
| 抛异常 | 固定值(false/true) | 阻塞 | 超时 | |
| 插入 | add | offer | put | offer(o, timeout, timeunit) |
| 删除 | remove | poll | take | poll(timeout, timeunit) |
LinkedBlockingQueue 同ArrayBlockingQueue,只是内部是以链表结构实现。可以定长,若不限制,则默认是Integer.MAXVALUE长度
PriorityBlockingQueue
DelayQueue
定义:是一个无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的Delayed 元素
应用:缓存系统的设计,缓存中的对象,超过了空闲时间,需要从缓存中移出;任务调度系统,能够准确的把握任务的执行时间
eg:淘宝订单业务:下单之后如果三十分钟之内没有付款就自动取消订单。饿了吗订餐通知:下单成功后60s之后给用户发送短信通知。
实现:为了具有调用行为,存放到DelayDeque的元素必须继承Delayed接口。Delayed接口使对象成为延迟对象,它使存放在DelayQueue类中的对象具有了激活日期。该接口强制执行下列两个方法。
- CompareTo(Delayed o):Delayed接口继承了Comparable接口,因此有了这个方法。
- getDelay(TimeUnit unit):这个方法返回到激活日期的剩余时间,时间单位由单位参数指定。
SynchronousQueue
源码解析http://blog.csdn.net/vickyway/article/details/50113429
是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素
。
CountDownLatch 闭锁
应用场景 http://www.importnew.com/15731.html
使一个线程等待其他线程完成各自的工作后再执行
等待的线程调用await方法,当其等待的所有的线程执行完
CyclicBarrier栅栏
多个线程互相等待,直到所有的都调用了await()方法,才不等待。
闭锁和栅栏的区别:
CountDownLatch :
一个线程
(或者多个), 等待另外
N个线程
完成
某个事情
之后才能执行。 CyclicBarrier :
N个线程
相互等待,任何一个线程完成之前,所有的线程都必须等待。
这样应该就清楚一点了,对于CountDownLatch来说,重点是那个
“一个线程”
, 是它在等待, 而另外那N的线程在把
“某个事情”
做完之后可以继续等待,可以终止。而对于CyclicBarrier来说,重点是那
N个线程
,他们之间任何一个没有完成,所有的线程都必须等待。
Exchanger交换机
exchange() 当线程调用此方法后被阻塞,直到另一个线程与此交换数据。
用于两个线程之间交换数据
Semaphore信号量
多个线程对有限资源的访问。
类中函数解析http://blog.csdn.net/hechurui/article/details/49508439
应用:
Semaphore类是一个计数信号量,必须由获取它的线程释放, 通常用于限制可以访问某些资源(物理或逻辑的)线程数目。
一个信号量有且仅有3种操作,且它们全部是原子的:初始化、增加和减少
增加可以为一个进程解除阻塞;
减少可以让一个进程进入阻塞。
信号量维护一个许可集,会在获得许可之前阻塞每一个线程:
构造函数:
public Semaphore(int permits,boolean fair)
如何从信号量获得许可?
public void acquire() throws InterruptedException
如何释放一个许可,并返回信号量?
public void release()
面试题思考:
在很多情况下,可能有多个线程需要访问数目很少的资源。假想在服务器上运行着若干个回答客户端请求的线程。这些线程需要连接到同一数据库,但任一时刻
只能获得一定数目的数据库连接。你要怎样才能够有效地将这些固定数目的数据库连接分配给大量的线程?
答:1.给方法加同步锁,保证同一时刻只能有一个人去调用此方法,其他所有线程排队等待,但是此种情况下即使你的数据库链接有10个,也始终只有一个处于使 用状态。这样将会大大的浪费系统资源,而且系统的运行效率非常的低下。
2.
另外一种方法当然是使用
信号量
,通过信号量许可与数据库可用连接数相同的数目,将大大的提高效率和性能。
Lock 锁
lock() :将 Lock 实例锁定。如果该 Lock 实例已被锁定,调用 lock() 方法的线程将会阻塞,直到 Lock 实例解锁。
lockInterruptibly() :将会被调用线程锁定,除非该线程被打断。此外,如果一个线程在通过这个方法来锁定 Lock 对象时进入阻塞等待,而它被打断了的话,该线程将会退出这个方法调用。
tryLock():试图立即锁定 Lock 实例。如果锁定成功,它将返回 true,如果 Lock 实例已被锁定该方法返回 false。这一方法永不阻塞。
tryLock(long timeout, TimeUnit timeUnit) :类似于 tryLock() 方法,除了它在放弃锁定 Lock 之前等待一个给定的超时时间之外。
unlock() :对 Lock 实例解锁。一个 Lock 实现将只允许锁定了该对象的线程来调用此方法。其他(没有锁定该 Lock 对象的线程)线程对 unlock() 方法的调用将会抛一个未检查异常(RuntimeException)。
与Synchronized的区别?
读写锁 ReadWriteLock
允许多个线程在同一时间对某特定资源进行读取,但同一时间内只能有一个线程对其进行写入。
实现类:
- ReentrantReadWriteLock
- ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- readWriteLock.readLock().lock();
- readWriteLock.readLock().unlock();
- readWriteLock.writeLock().lock();
- readWriteLock.writeLock().unlock();
原子性布尔 AtomicBoolean
完整类名是为 java.util.concurrent.atomic.AtomicBoolean
创建一个 AtomicBoolean
AtomicBoolean atomicBoolean =
new
AtomicBoolean(); //新建了一个默认值为 false 的 AtomicBoolean。
- AtomicBoolean atomicBoolean = new AtomicBoolean(true);
获取 AtomicBoolean 的值
boolean
value = atomicBoolean.get();
设置 AtomicBoolean 的值
- AtomicBoolean atomicBoolean = new AtomicBoolean(true);
- atomicBoolean.set(false);
交换 AtomicBoolean 的值
- AtomicBoolean atomicBoolean = new AtomicBoolean(true);
- boolean oldValue = atomicBoolean.getAndSet(false);
以上代码执行后 oldValue 变量的值为 true,atomicBoolean 实例将持有 false 值。代码成功将 AtomicBoolean 当前值 ture 交换为 false。
比较并设置 AtomicBoolean 的值
compareAndSet() 方法允许你对 AtomicBoolean 的当前值与一个期望值进行比较,如果当前值等于期望值的话,将会对 AtomicBoolean 设定一个新值。compareAndSet() 方法是原子性的,因此在同一时间之内有单个线程执行它。因此 compareAndSet() 方法可被用于一些类似于锁的同步的简单实现。
- AtomicBoolean atomicBoolean = new AtomicBoolean(true);
- boolean expectedValue = true;
- boolean newValue = false;
- boolean wasNewValueSet = atomicBoolean.compareAndSet(
- expectedValue, newValue);
本示例对 AtomicBoolean 的当前值与 true 值进行比较,如果相等,将 AtomicBoolean 的值更新为 false。
原子性整型 AtomicInteger
一个可以进行原子性读和写操作的 int 变量,它还包含一系列先进的原子性操作,比如 compareAndSet()。
比较并设置 AtomicInteger 的值
AtomicInteger 类也通过了一个原子性的 compareAndSet() 方法。这一方法将 AtomicInteger 实例的当前值与期望值进行比较,如果二者相等,为 AtomicInteger 实例设置一个新值。AtomicInteger.compareAndSet() 代码示例:
- AtomicInteger atomicInteger = new AtomicInteger(123);
- int expectedValue = 123;
- int newValue = 234;
- atomicInteger.compareAndSet(expectedValue, newValue);
同理与AtomicBoolean,附加:
增加 AtomicInteger 值
AtomicInteger 类包含有一些方法,通过它们你可以增加 AtomicInteger 的值,并获取其值。这些方法如下:
- addAndGet()
- getAndAdd()
- getAndIncrement()
- incrementAndGet()
第一个 addAndGet() 方法给 AtomicInteger 增加了一个值,然后返回增加后的值。getAndAdd() 方法为 AtomicInteger 增加了一个值,但返回的是增加以前的 AtomicInteger 的值。具体使用哪一个取决于你的应用场景。以下是这两种方法的示例:
- AtomicInteger atomicInteger = new AtomicInteger();
- System.out.println(atomicInteger.getAndAdd(10));
- System.out.println(atomicInteger.addAndGet(10));
本示例将打印出 0 和 20。
getAndIncrement() 和 incrementAndGet() 方法类似于 getAndAdd() 和 addAndGet(),但每次只将 AtomicInteger 的值加 1。
减小 AtomicInteger 的值
AtomicInteger 类还提供了一些减小 AtomicInteger 的值的原子性方法。这些方法是:
- decrementAndGet()
- getAndDecrement()
decrementAndGet() 将 AtomicInteger 的值减一,并返回减一后的值。getAndDecrement() 也将 AtomicInteger 的值减一,但它返回的是减一之前的值。
原子性长整型 AtomicLong:同理于原子性整型
原子性引用型 AtomicReference
AtomicReference 提供了一个可以被原子性读和写的对象引用变量。
原子性的意思是多个想要改变同一个 AtomicReference 的线程不会导致 AtomicReference 处于不一致的状态。
AtomicReference 还有一个 compareAndSet() 方法,通过它你可以将当前引用于一个期望值(引用)进行比较,如果相等,在该 AtomicReference 对象内部设置一个新的引用。
比较并设置 AtomicReference 引用
AtomicReference 类具备了一个很有用的方法:compareAndSet()。compareAndSet() 可以将保存在 AtomicReference 里的引用于一个期望引用进行比较,如果两个引用是一样的(并非 equals() 的相等,而是 == 的一样),将会给 AtomicReference 实例设置一个新的引用。
如果 compareAndSet() 为 AtomicReference 设置了一个新的引用,compareAndSet() 将返回 true。否则 compareAndSet() 返回 false。
执行器服务 ExecutorService
java.util.concurrent.ExecutorService 接口表示一个异步执行机制,使我们能够在后台执行任务
java.util.concurrent 包提供了 ExecutorService 接口的以下实现类:
- ThreadPoolExecutor
- ScheduledThreadPoolExecutor
有几种不同的方式来将任务委托给 ExecutorService 去执行:
- execute(Runnable):无返回结果
- submit(Runnable):它返回一个 Future 对象。这个 Future 对象可以用来检查 Runnable 是否已经执行完毕。
- submit(Callable)
- invokeAny(...)
- invokeAll(...)
- submit(Runnable)
- Future future = executorService.submit(new Runnable() {
- public void run() {
- System.out.println("Asynchronous task");
- }
- });
- future.get(); //returns null if the task has finished correctly.
Callable 实例除了它的 call() 方法能够返回一个结果之外和一个 Runnable 很相像。Runnable.run() 不能够返回一个结果。
Callable 的结果可以通过 submit(Callable) 方法返回的 Future 对象进行获取。以下是一个 ExecutorService Callable 示例:
- Future future = executorService.submit(new Callable(){
- public Object call() throws Exception {
- System.out.println("Asynchronous Callable");
- return "Callable Result";
- }
- });
- System.out.println("future.get() = " + future.get());
以上代码输出:
Asynchronous Callable
future.get() = Callable Result
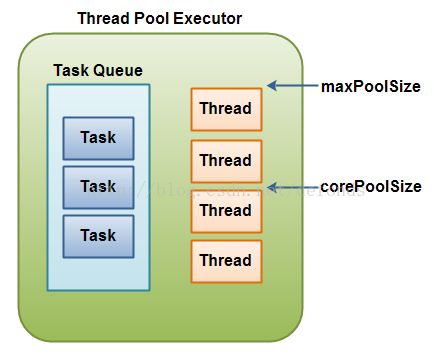
线程池执行者 ThreadPoolExecutor
java.util.concurrent.ThreadPoolExecutor 是 ExecutorService 接口的一个实现。ThreadPoolExecutor 使用其内部池中的线程执行给定任务(Callable 或者 Runnable)。
ThreadPoolExecutor 包含的线程池能够包含不同数量的线程。池中线程的数量由以下变量决定:
- corePoolSize
- maximumPoolSize
当一个任务委托给线程池时,如果池中线程数量低于 corePoolSize,一个新的线程将被创建,即使池中可能尚有空闲线程。
如果内部任务队列已满,而且有至少 corePoolSize 正在运行,但是运行线程的数量低于 maximumPoolSize,一个新的线程将被创建去执行该任务。
一个 ThreadPoolExecutor
创建一个 ThreadPoolExecutor
- int corePoolSize = 5;
- int maxPoolSize = 10;
- long keepAliveTime = 5000;
- ExecutorService threadPoolExecutor =
- new ThreadPoolExecutor(
- corePoolSize,
- maxPoolSize,
- keepAliveTime,
- TimeUnit.MILLISECONDS,
- new LinkedBlockingQueue
() - );
但是,除非你确实需要显式为 ThreadPoolExecutor 定义所有参数,使用 java.util.concurrent.Executors 类中的工厂方法之一会更加方便。
定时执行者服务 ScheduledExecutorService
java.util.concurrent.ScheduledExecutorService 是一个 ExecutorService, 它能够将任务延后执行,或者间隔固定时间多次执行。
作者线程异步执行,而不是由提交任务给 ScheduledExecutorService 的那个线程执行。
以下是一个简单的 ScheduledExecutorService 示例:
- ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
- ScheduledFuture scheduledFuture =
- scheduledExecutorService.schedule(new Callable() {
- public Object call() throws Exception {
- System.out.println("Executed!");
- return "Called!";
- }
- },
- 5,
- TimeUnit.SECONDS);
首先一个内置 5 个线程的 ScheduledExecutorService 被创建。之后一个 Callable 接口的匿名类示例被创建然后传递给 schedule() 方法。后边的俩参数定义了 Callable 将在 5 秒钟之后被执行。
Callable
Java并发编程:Callable、Future和FutureTask
有返回值且可以抛异常的接口
Future 表示异步计算的结果
1)判断任务是否完成;
2)能够中断任务;
3)能够获取任务执行结果。
- cancel方法用来取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。参数mayInterruptIfRunning表示是否允许取消正在执行却没有执行完毕的任务,如果设置true,则表示可以取消正在执行过程中的任务。如果任务已经完成,则无论mayInterruptIfRunning为true还是false,此方法肯定返回false,即如果取消已经完成的任务会返回false;如果任务正在执行,若mayInterruptIfRunning设置为true,则返回true,若mayInterruptIfRunning设置为false,则返回false;如果任务还没有执行,则无论mayInterruptIfRunning为true还是false,肯定返回true。
- isCancelled方法表示任务是否被取消成功,如果在任务正常完成前被取消成功,则返回 true。
- isDone方法表示任务是否已经完成,若任务完成,则返回true;
- get()只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。
- get(long timeout, TimeUnit unit)用来获取执行结果,如果在指定时间内,还没获取到结果,就直接返回null。
因为Future只是一个接口,所以是无法直接用来创建对象使用的,因此就有了下面的FutureTask。FutureTask是Future接口的一个唯一实现类。
FutureTask
深入学习:http://www.importnew.com/25286.html
应用场景:
1.
Future用于异步获取执行结果或者取消任务。
2.
在高并发场景下确保任务只执行一次。
------->
| 继承实现关系 | FutureTask |
RunnableFuture |
Runnable, Future |
FutureTask提供了2个构造器:
public
FutureTask(Callable callable)
public
FutureTask(Runnable runnable, V result)
可通过Excutor(线程池) 来执行,也可传递给Thread对象执行。
FutureTask是为了弥补Thread的不足而设计的,它可以让程序员准确地知道线程什么时候执行完成并获得到线程执行完成后返回的结果(如果有需要)。
FutureTask是一种可以取消的异步的计算任务。
一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。