iOS性能优化(一)卡顿优化
目录
一、性能优化从哪几方面入手?
二、卡顿优化
1.屏幕成像原理
2.卡顿原因
3.卡顿解决办法
3.1卡顿优化 — CPU
3.2卡顿优化 — GPU
4.卡顿检测
总结
前言
随着移动互联网的快速发展,各个领域都出现了巨头,各大App不再是以实现功能抢占市场,而是把App的用户体验做到最好,性能优化就是决定一款产品体验好坏的关键因素,也一定程度决定了用户的忠诚度和市场占有率,本文介绍几种常见的性能优化方式,让我们的App有更好的体验。
一、性能优化从哪几方面入手?
- 卡顿优化
- 启动速度优化
- 安装包瘦身
- 耗电量优化
- 网络流量优化
- 崩溃率优化
- 安全性优化
二、卡顿优化
1.屏幕成像原理
首先介绍两个处理器:CPU和GPU
CPU:中央处理器(CPU,central processing unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。
GPU:图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
CPU就像机器的大脑,主要负责计算工作,比如对象的创建和销毁、对象属性的调整、布局计算、文本的计算和排版、图片的格式转换和解码、图像的绘制等,图像的渲染就交给它的小弟GPU去做。
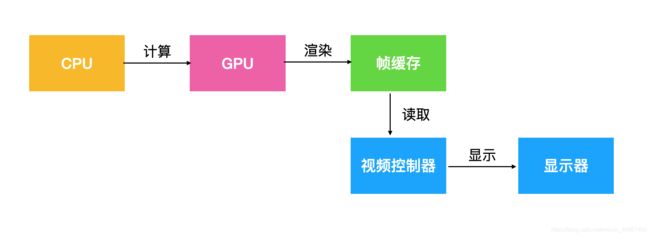
从屏幕成像过程可以看出,CPU完成显示图像的大小位置内容等计算后,交给GPU去绘制,GPU绘制完成一帧图像后放到帧缓存区,iOS中是双缓冲机制,有前帧缓存和后帧缓存,提高了渲染效率。
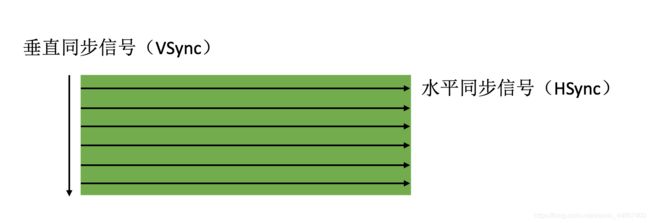
我们看到的动态屏幕其实也是一帧一帧的静态画面组成的,显示器会用硬件时钟产生一系列的定时信号,电子枪准备扫描新的一行时,显示器会发出一个水平同步信号(Horizonal Synchronization),简称 HSync,当前屏幕完全扫描完成,再次滑动时,需就要绘制新的一帧画面,显示器会发出一个垂直同步信号(Vertical Synchronization),简称 VSync,iPhone是以固定频率刷新进行刷新,默认刷新率是60hz,垂直同步信号大概16.7ms发送一次,
2.卡顿原因
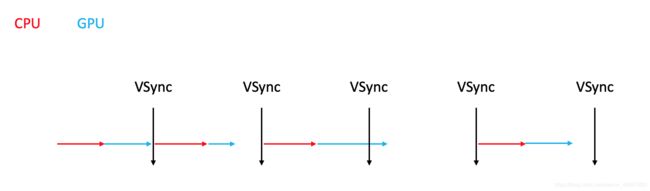
每隔16.7ms,视频控制器来帧缓存区拿数据去屏幕显示,
- 当垂直信号来时,GPU正好把CPU交给的数据渲染完成,视频控制器拿走数据显示到屏幕上,CPU和GPU马上搭配做下一帧数据的处理,没有卡顿
- 当垂直信号来时,可能CPU处理时间过长,也可能GPU渲染时间过长,总之桢缓存区没有这一桢的数据,那视频控制器就不要这一桢了,结果就是屏幕上显示着上一桢的数据,等下一次垂直信号来的时候,可能没及时显示的这一桢终于渲染完了,视频控制器拿走显示到屏幕上,桢画面没有及时显示,卡顿产生
- 当垂直信号来时,CPU和GPU配合早早完成了数据的渲染工作,就等视频控制器来取数据了,页面就会很流畅
3.卡顿解决办法
卡顿产生的原因就是CPU和GPU没有及时处理好数据,针对卡顿的优化就有思路了:尽可能减少 CPU 和 GPU 资源的消耗
3.1卡顿优化 — CPU
- 尽量用轻量级的对象,比如用不到事件处理的地方使用CALayer取代UIView、能用 int 就不要去使用 NSNumber
- 不要频繁地调用和调整UIView的相关属性,比如frame、bounds、transform等属性,尽量提前计算好布局,需要时一次性修改属性,减少不必要的调用和修改(UIView的显示属性实际都是CALayer的映射,而CALayer本身是没有这些属性的,都是初次调用属性时通过resolveInstanceMethod添加并创建Dictionry保存的,耗费资源)
- 如果对象不涉及 UI 操作,尽量放到后台子线程去处理
Autolayout会比直接设置 frame 消耗更多的 CPU 资源,相对布局最终到CPU那里也是计算出视图的绝对大小和位置的,如果不是特备复杂的位置关系,尽量用绝对布局,减少CPU的计算- 图片的 size 和 UIImageView 的 size 保持一致。大小一致,CPU不需要做拉伸压缩操作
- 控制线程的最大并发数量,线程过多CPU会很忙,而且CPU调度也需要时间
- 针对不规则列表,缓存cell的高度、通过设置view的显示和隐藏替代动态创建
- xib和storyboard创建视图比纯代码更加消耗资源,不推荐使用
- 耗时的操作放到子线程,如文本处理(尺寸计算、绘制)、图片在子线程强制解码
3.2卡顿优化 — GPU
- 尽量避免短时间内大量图片的显示,尽可能将多张图片合成一张进行显示
- 尽量减少透视图的数量和层次
- 减少透明的视图(alpha < 1),不透明的就设置 opaque 为 YES,透明度涉及到混合颜色的计算
- GPU 能处理的最大纹理尺寸是 4096 * 4096,超过这个尺寸就会占用 CPU 资源,所以纹理不能超过这个尺寸
- 尽量避免出现离屏渲染
离屏渲染
在OpenGL中,GPU有2种渲染方式
- On-Screen Rendering:当前屏幕渲染,在当前用于显示的屏幕缓冲区进行渲染操作
- Off-Screen Rendering:离屏渲染,在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作
离屏渲染消耗性能的原因
- 需要创建新的缓冲区,两个缓冲区都不够用
- 离屏渲染的整个过程,需要多次切换上下文环境,先是从当前屏幕(On-Screen)切换到离屏(Off-Screen),渲染结束后,将离屏缓冲区的渲染结果显示到屏幕上,上下文环境从离屏切换到当前屏幕,这个过程会造成性能的消耗。
哪些操作会触发离屏渲染?
- 光栅化,layer.shouldRasterize = YES
- 遮罩,layer.mask
- 圆角,同时设置layer.cornerRadius大于0、layer.masksToBounds = YES,可以通过CoreGraphics绘制裁剪圆角,或者使用圆角图片
- 阴影,layer.shadowXXX(shadowColor、shadowOffset等),如果设置了layer.shadowPath就不会产生离屏渲染
4.卡顿检测
卡顿是因为主线程执行了耗时的操作,通过添加 Observer 到主线程 RunLoop 中,监听 RunLoop 状态的切换的耗时,达到监控卡顿的目的。
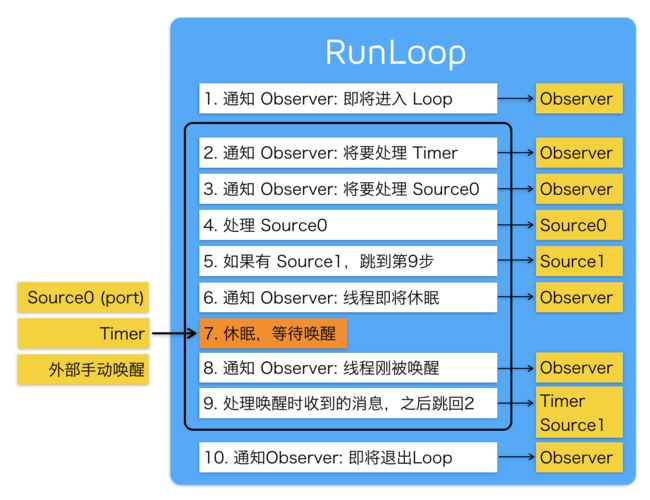
一张经典的RunLoop运行逻辑和对应的状态方法
// 1.进入loop
__CFRunLoopRun(runloop, currentMode, seconds, returnAfterSourceHandled)
// 2.RunLoop 即将触发 Timer 回调。
__CFRunLoopDoObservers(runloop, currentMode, kCFRunLoopBeforeTimers);
// 3.RunLoop 即将触发 Source0 (非port) 回调。
__CFRunLoopDoObservers(runloop, currentMode, kCFRunLoopBeforeSources);
// 4.RunLoop 触发 Source0 (非port) 回调。
sourceHandledThisLoop = __CFRunLoopDoSources0(runloop, currentMode, stopAfterHandle)
// 5.执行被加入的block等Source1事件
__CFRunLoopDoBlocks(runloop, currentMode);
// 6.RunLoop 的线程即将进入休眠(sleep)。
__CFRunLoopDoObservers(runloop, currentMode, kCFRunLoopBeforeWaiting);
// 7.调用 mach_msg 等待接受 mach_port 的消息。线程将进入休眠, 直到被下面某一个事件唤醒。
__CFRunLoopServiceMachPort(waitSet, &msg, sizeof(msg_buffer), &livePort)
// 进入休眠
// 8.RunLoop 的线程刚刚被唤醒了。
__CFRunLoopDoObservers(runloop, currentMode, kCFRunLoopAfterWaiting
// 9.1.如果一个 Timer 到时间了,触发这个Timer的回调
__CFRunLoopDoTimers(runloop, currentMode, mach_absolute_time())
// 9.2.如果有dispatch到main_queue的block,执行bloc
__CFRUNLOOP_IS_SERVICING_THE_MAIN_DISPATCH_QUEUE__(msg);
// 9.3.如果一个 Source1 (基于port) 发出事件了,处理这个事件
__CFRunLoopDoSource1(runloop, currentMode, source1, msg);
// 10.RunLoop 即将退出
__CFRunLoopDoObservers(rl, currentMode, kCFRunLoopExit);由于source0处理的是app内部事件,包括UI事件,所以可知处理事件主要是在kCFRunLoopAfterWaiting 和kCFRunLoopBeforeSources 之间。我们可以创建一个子线程去监听主线程状态变化,通过dispatch_semaphore在主线程进入状态时发送信号量,子线程设置超时时间循环等待信号量,若超过时间后还未接收到主线程发出的信号量则可判断为卡顿,保存响应的调用栈信息去进行分析。可参考LXDAppMonitor
总结
卡顿优化工作是一个复杂而艰巨的过程,尤其到后期更是如此,越是庞大的项目越需要对流畅度做优化,它涉及到代码的重构、逻辑的重写,甚至是底层架构,牵一发而动全身,所以开发人员必须在熟悉现有业务逻辑的前提下做优化,在不发生crash的情况下尽可能保持App的流畅性如行云流水一般。