python - 作业7:简单数据分析(附代码)
python - 作业7:简单数据分析
- pandas数据处理
- 调用方式
- Series
- 创建Series的方法
- *10.29晚上* 补充更新
- DataFrame
- 行索引和列索引
- 基本操作
- 比较Series和DataFrame
- 数据处理
- pd.concat纵向连接
- 作业
- read_csv的常用参数
- 运行结果
- *2020/02/04* 更新code
github指路 冲冲冲冲冲
----------------------------------原文–如下--------------------------------
第八周的python 没有迟到但是睡着了= =在最后的时候,我什么时候才可以不迟到不睡觉最正常地上一节ldw老师的python课呀555555
这节课的题目是
pandas数据处理
主要讲的就是pandas这个模块
那么pandas是什么
回答:基于numpy的一个更高级的数据分析结构,非官方
提问:他能用来干嘛
回答:pandas可以用来处理类似于excel文件的数据(比如我们的实验作业就是处理csv数据 虽然是操作非常简单但是也算是处理数据惹)
提问:能不能说的具体一点
回答:可以,可以对数据进行增、删、改、查等操作,pandas里面还有很多数据处理的函数
提问:excel也能做的话,pandas有什么优势呢
回答:pandas便于写脚本,可以用来批量处理数据(老师上课讲的原话意思是,如果你就修改数据的某一个地方,excel会更方便一点,单击单元格修改就可以了,但是如果要批量修改的话,也就是改很多个excel里面的某个值,某段值,那么就不太方便了)
接下来就讲一下
调用方式
,(因为上课主要涉及到了Series和DataFrame这两个模块所以调用的时候选择from … import 的这条语句)
from pandas import Series,DataFrame
import pandas as pd
在这之前别忘了
pip install pandas 这个库
然后介绍了一下series
Series
是一种既像字典又像数组的,(就是可以用按键索引,也可以用序号索引的意思)
一种有序的,同构的(老师说如果里面存的东西不同构的话,比如既放了int又放了float,那么聪明的series就会把int转化为float,让他们以另一种方式变成同构的,即暗搓搓改变不给你报错的机会)数据结构
然后series里面的元素采用的都是numpy中的数据类型,(毕竟是基于numpy写的,总的留点什么痕迹)
接下来讲
创建Series的方法
10.29晚上 补充更新
-
以默认索引(自然数)生成:
obj1 = Series([2,2,3,3]) -
常规创建(在讲完这个常规创建之后,老师后面接了一句,其实也不算是常规创建,因为真正的常规创建是从文件里面读取的数据)
obj2 = Series([2,2,3,3],index=['a','b','c','d']) -
用字典创建Series
dir={'a':123,'b':456,'c':789} obj3 = dir
然后series可以索引一个或多个值,然后这是老师上课给出的一些例子

然后 算术运算中都是按键来对齐的
讲到这里的话 就得提到一个特殊的数值,默认为float类型,NaN,老师说他的全称应该是not a number,即不是一个数字,它的作用是填充,主要就是放在series中没有数据的部分,保证数据具有同构性。
需要注意的是,NaN和任何数值进行任何运算的结构都为NaN
接下来,就回到按键来对齐的算术运算里面

obj4和obj5进行运算的话,(其实我现在还不是很懂,我决定去问老师,但是老师现在还没有回我,所以我先bb一下我的猜测,大概就是obj5它里面有键值为’e’的但是obj4没有所以运算的时候obj4里面的’a’相加找的是obj5里面的’a’对应的数值
先跳过这个模糊的说法,然后series里面有一个属性,name,就是这个对象的名字,特殊的是不仅仅这个对象可以有name,他的index也可以有name属性
赋值的话 就 obj1.name='fool' obj1.index.name='bar'这个样子
那么这个name有什么用呢
回答:引出DataFrame数据结构,有了name之后的Series数据结构可以成为DataFrame中的一部分
okey,接下来看这个
DataFrame
模块,他的数据存储形式很像excel表格,里面包含着一组有序的列,列内同构(就很像Series),列之间可以不同构
DataFrame中既有行索引又有列索引 ,是以二维结构保存数据的= =(所以和excel表格很像)
同样的创建DataFrame,可以指定 columns和index,具体的可以看图

接下来讲
行索引和列索引
列索引的话就普通的方括号,frame['name']
行索引就是方括号之前加上.ix,就是frame.ix['01']
然后讲了一些
基本操作
,包括丢弃指定行和列 和 插入行之类的
丢弃指定的 行和列 ,drop方法默认丢弃列 frame.drop('name'),要修改axis参数(默认为0)才可以丢弃行 - -举个栗子:frame.drop('name',axis=1)
插入行,这个insert函数没有预先定义插入行的方法(也就是说只能插入列吗?不不不,插入行的话你可以之间索引一个不存在的键值然后他就加进去了…不讲道理…)那么插入行 就是 frame.insert(1,'new_name',s) 这里面的1指的是index,就是插入列的下标,'new_name’指的是插入列的名称,s指的是Series的对象
比较Series和DataFrame

Series和DataFrame在进行运算的时候是把Series看作一行,然后把Series的索引和DataFrame的列索引对齐,再在纵向上广播,(简单点说就是重复)
然后老师把DataFrame模块里的index对象和index属性单独拎出来讲了一下,这里我开始犯困,听的不是很明白
创建index的话就是 index1 = frame.index()
然后pd.index是不可以原位修改的,(就是不能对它的索引值进行直接修改的意思)Series可以通过共享index来创建同样结构的DataFrame(就很方便???)
index对象可以做的操作,
单个运算的比如说 delete() / drop() / insert() / update()
双目的比如说 append() – 连接 / different() – 差集 / intersection() --交集
然后讲到了(个人认为比较实用的)
数据处理
的方法
-
数据过滤 (就是丢掉有些没有用的数据……)

-
按索引排序

-
处理缺失数据(NaN)

顺便还讲了 在算术运算中,索引值不匹配也会产生NaN - -
顺便顺便讲了一些算术运算

-
合并数据集
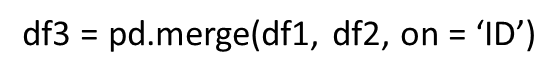
最后提了一下
pd.concat纵向连接
= =(此时睡死过去的我T - T,根本没听到)
然后是作业(我努力强行清醒听完了作业要求,氦,心里有个底,沉沉睡去……)
上完课w同学和我说,我感觉这次的作业不是很难欸bulabula应该没有上次的难吧
我想想觉得有道理,结果这一口毒奶,给我读了一小时的csv文件,绝惹5555555
作业

有点曲折,我决定还原我当时的过程:
首先我的代码长这个样子
import pandas as pd
csv_file = "yourfilename.csv" #csv文件名
csv_data = pd.read_csv(csv_file, low_memory = False)#防止弹出警告
csv_df = pd.DataFrame(csv_data)
但是我现在已经是上帝视角了,所以没得必要
ok第一个报错(其实也就一个)
<pandas.io.parsers.TextFileReader object at 0x0000027988E487F0>
看了一个竞赛选手的博客,他说= =的,我,看不懂= =
贴上来大家康康吧,顺便希望有人给我解释一下下

这是大佬博客的原地址:https://blog.csdn.net/Anasta198110/article/details/79590157
然后,我就懵懵懂懂得了解了,怕是我撞到了那个错误5555,然后不知道解决的办法,所以没办法呀,我就去网上拷代码试
于是,有一次,终于,我成功了,我就知道我会成功的!!!!我看到了for循环!我觉得我肯定会对的这次,然后,果然不出意外(表面成功)
path = r"C:\Users\……\liupy\homework"#文件路径
file = glob.glob(os.path.join(path, '*csv_name.csv'))#文件名
d1 = []
for f in file:
d1.append(pd.read_csv(f, engine='python'))
data = pd.concat(d1)
print(d1)
print('-------')
print(d1['Country'])
print(d1[1])
那个pd.concat就是纵向连接= =
最后一行他会报错,为什么呢= =
我仔细一看,发现他的循环只有一次呀(其实花了点时间= =)
那怎么办呢 然后我就想着给他弄成字典的样子,手动输出查错一番操作之后我得出结论,行不通啊,氦
然后,我眼睛一咪,发现事情并不简单啊!为什么在for循环里不报错呢
为什么为什么为什么,明明他调用的也是read_csv方法为什么不报错,

之前参考我的代码,我发现
那个参数
可能
有点
问题
但是
之前我也试着把那个参数删掉,但是没有用,没有用啊
所以,我本着再试一次我不亏的信念加上了engine='python’这个参数
我就
成功了
真容易啊~哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈
好吧言归正传,其实我看到了这个(我加粗了重点嘻嘻嘻,原来是没有的)
所以他给我们一个启发,没事多看看api还是有用的- -
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer',
names=None, index_col=None, usecols=None, squeeze=False,
prefix=None, mangle_dupe_cols=True, dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, nrows=None,
na_values=None, keep_default_na=True, na_filter=True,
verbose=False, skip_blank_lines=True, parse_dates=False,
infer_datetime_format=False, keep_date_col=False, date_parser=None,
dayfirst=False, iterator=False, chunksize=None, compression='infer',
thousands=None, decimal=b'.', lineterminator=None, quotechar='"',
quoting=0, escapechar=None, comment=None, encoding=None,
dialect=None, tupleize_cols=None, error_bad_lines=True,
warn_bad_lines=True, skipfooter=0, doublequote=True,
delim_whitespace=False, low_memory=True, memory_map=False,
float_precision=None)
解释一下:
read_csv的常用参数
filepath_or_buffer : 类型str,代表CSV文件地址。
sep : 类型str, 默认值为‘,’,用于指定分隔符。如果不指定参数,则会尝试使用逗号分隔。
header : 类型为int或者int的列表,它指定用来作为列名行号,然后数据从行号的下一行开始读取。 默认情况下header是根据参数names(如下)
来推断header的值。如果names为None,则等价于header=0,默认把文件中第一行作为列名,数据从第一行开始读取。如果names显示地传入,
则等价于header=None,则数据从0行开始读取。如果传入header=0,names不为None,则将替换原有的列名。header参数可以是一个list。
例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉(例如本例中的2;
本例中的数据1,2,4行将被作为多级标题出现,第3行数据将被丢弃,dataframe的数据从第5行开始。)
names : 一个数组, 默认为None。列名列表,如果数据文件中没有列标题行,就需要执行header=None。
usecols : 一个数组, 默认为None,返回数据列一个子集。如果传入字符,则列名需要与表中列名对应。如果传入整数列表,则表示列的索引值。
例如:usecols有效参数可能是 [0,1,2]或者是 [‘foo’, ‘bar’, ‘baz’]。
prefix : 类型str, 默认为None。在没有列标题时,给列添加前缀。例如:添加‘X’ 成为 X0, X1, …
engine : {‘c’, ‘python’},可选。使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。
nrows : 类型int, 默认为None。需要读取的行数(从文件头开始算起)。
iterator : 类型boolean, 默认为False。返回一个TextFileReader 对象,以便逐块处理文件。
这是从这位大佬的博客里发现的~然后希望我也能养成天天阅读api的习惯555
传送门:https://blog.csdn.net/MOU_IT/article/details/78762196#1%E3%80%81%E4%BB%8ECSV%E6%96%87%E4%BB%B6%E8%AF%BB%E5%8F%96%E5%88%B0DataFrame
言归正传,代码和series创建及后面的上课内容我下次再补,我饿了先吃饭= =
然后= =
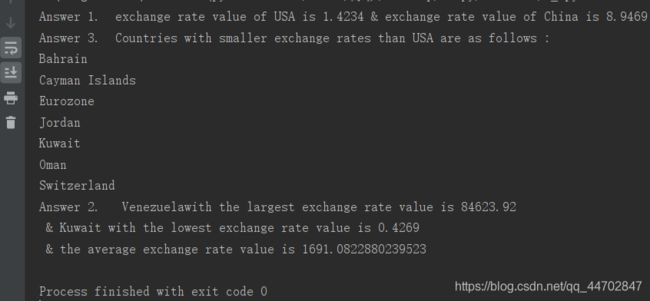
运行结果
2020/02/04 更新code
有错误的话要注意一下我的文件路径,改一下应该就对了(奥力给
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/10/29 10:32
# @Author : Chen Shan
# Function : Simple data analysis, read csv file and save it in DataFrame
import os, glob
from pandas import Series,DataFrame
import pandas as pd
csv_file = "../py-data/7_exrates.csv"
csv_data = pd.read_csv(csv_file,engine='python')
csv_df = DataFrame(csv_data)
# print(csv_df)
# print('-----')
# print(csv_df['Country'])
# print('-----')
# print(csv_df.shape)
# print(csv_df['Currency units per �1'])
shape = csv_df.shape
usa_cur = 0
china_cur = 0
for i in range (shape[0]):
if csv_df['Country'][i]=='USA':
usa_cur = csv_df['Currency units per �1'][i]
if csv_df['Country'][i]=='China':
china_cur = csv_df['Currency units per �1'][i]
print("Answer 1. exchange rate value of USA is "+str(usa_cur)+" & exchange rate value of China is "+ str(china_cur))
sum_cur = 0
max_cur = 0
max_country = 0
min_cur = 10010
min_country = 0
print("Answer 3. Countries with smaller exchange rates than USA are as follows :")
for i in range (shape[0]):
if csv_df['Currency units per �1'][i]< usa_cur:
print(csv_df['Country'][i])
if csv_df['Currency units per �1'][i] > max_cur:
max_cur = csv_df['Currency units per �1'][i]
max_country = csv_df['Country'][i]
if csv_df['Currency units per �1'][i] < min_cur:
min_cur = csv_df['Currency units per �1'][i]
min_country = csv_df['Country'][i]
sum_cur = sum_cur + csv_df['Currency units per �1'][i]
avg_cur = sum_cur / shape[0]
print("Answer 2. " + max_country + "with the largest exchange rate value is " + str(max_cur) )
print(" & " + min_country + " with the lowest exchange rate value is " + str(min_cur))
print(" & the average exchange rate value is " +str(avg_cur))