Coursera-Applied Data Science with Python-Introduction to Data Science in Python-Week2
一、The Series Data Structure:
Series是pandas的核心数据结构之一,在pandas中,Series是一个一维的类似的数组对象,可以看成一个介于list和dictionary之间的结构,它包含一个数组数据(任何numpy数据类型)和一个与数组关联的索引。为了方便理解,你可以把Series看着是一个有序字典。其中索引是连续的,从0开始。

在底层,pandas使用Numpy库将Series中的值存储到一个类型数组中(a typed array),这样的话,使得处理series比处理传统的python的list要快很多。
1.创建Series:
以list创建Series:
如果只给出了list而不给出相应的index的话,pandas会对值自动分配从0开始的自增的index。而且在没有指定Series的name属性的情况下,pandas会根据处理内容添加上相应的name,比如下面的两个例子中,第一个的name就是object,第二个是int64。
import pandas as pd
animals = ['Tiger', 'Bear', 'Moose']
pd.Series(animals)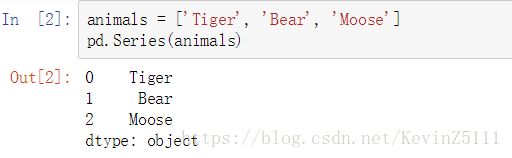
numbers = [1, 2, 3]
pd.Series(numbers)
在python中以None表示缺失的数据,而在pandas中会根据所处理的对象类型的不同分为None和NaN,None代表某个对象,字符串等的缺失;NaN代表的是数值上的缺失,它和None很相似,但是NaN是数值类型的(numeric value)。这样分开处理的原因是,NaN的处理效率更高。
animals = ['Tiger', 'Bear', None]
pd.Series(animals)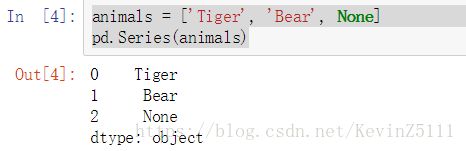
numbers = [1, 2, None]
pd.Series(numbers)
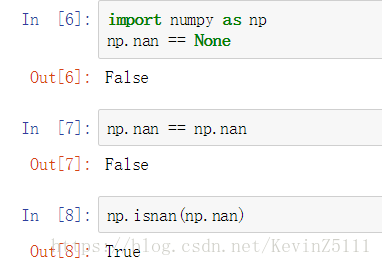
对于None和NaN来说,要注意下面几点:
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports)
s

使用dictionary创建series时,我们可以为series通过index参数指定series的index,具体来说就是,不管dictionary中的key值,以index参数列表中的值为准,即以后出现在series里的index一定是从index参数列表中来的,与dictionary中的key值无关。对于同时存在于index参数列表和dictionary的key的index值来说,series中会有相应的数据及标签;对于只在index参数列表中存在的index值来说,series中只有index值,相应的值被设置为None或者NaN;对于只在dictionary的key值中存在的index来说,series中不会出现。
指定index和value:
s = pd.Series(['Tiger', 'Bear', 'Moose'], index=['India', 'America', 'Canada'])
s
指定的index和dictionary的key不匹配:
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports, index=['Golf', 'Sumo', 'Hockey'])
s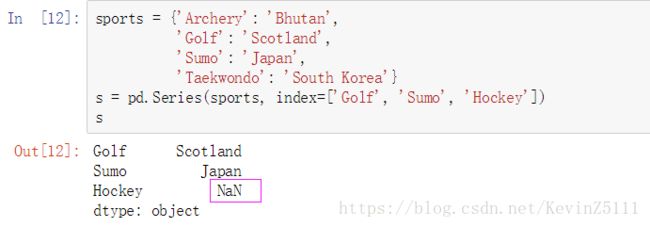
2.获得Series中的值:
在Series中,数据(value)可以通过位置(index position)和标签(index label)进行查询。在没有为series设置index的情况下,位置和标签其实是一回事,都是从0开始自增的整数。
如果是采用位置进行查询的话,使用iloc属性;如果是使用标签进行查询的话,使用loc属性:具体地,请看下面的例子
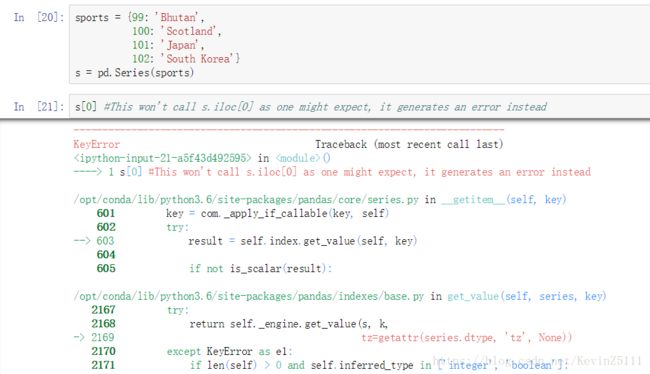
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports)
s.iloc[3]
s.loc['Golf']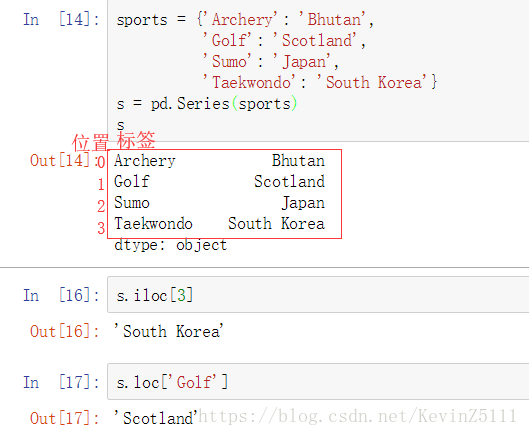
这个例子中,s.iloc[3]是指位置为3的对应的value,即South Korea;s.loc['Golf']是指标签为Golf的对应的value,即Scotland。
此外,loc属性还有一个功能,能修改该标签对应的值,而且如果这个标签不存在的话,就向series中添加该项:

还可以通过直接使用方括号(“[]”)的办法进行查询,pandas会根据方括号中的值的类型来判断是用iloc还是用loc,但是在按行进行查询时,不推荐使用这种做法,因为这样会使得代码的意思不清晰,而且有时候会带来bug。
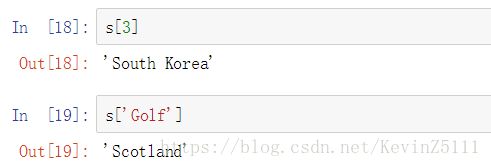
总结一下:如果要按行进行查询的话,一般使用loc、iloc属性进行查询;而按列进行查询的话,一般使用方括号("[]")进行查询。
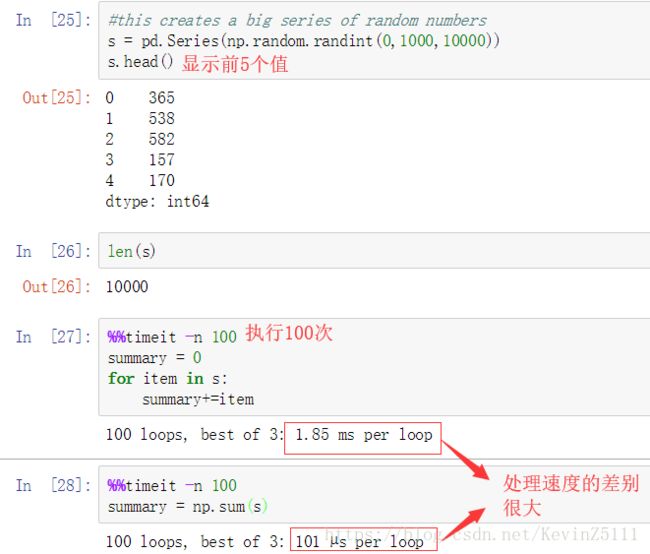
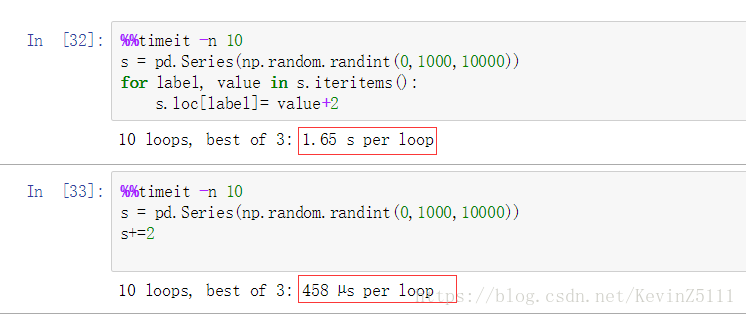
series也支持对其中的每个值进行迭代,但是如果要对series的值进行操作的话优先考虑使用处理速度快的向量化,而不是对series中的值迭代进行处理。下面我们使用Jupyter Notebook中的magic function来测试向量化和非向量化哪个的处理速度更快:
测试一:对10000个值在0~1000的随机数进行求和
%%timeit -n 100
summary = 0
for item in s:
summary+=item
%%timeit -n 100
summary = np.sum(s)结果为:
测试二:把所有随机数值加2:
%%timeit -n 10
s = pd.Series(np.random.randint(0,1000,10000))
for label, value in s.iteritems():
s.loc[label]= value+2
%%timeit -n 10
s = pd.Series(np.random.randint(0,1000,10000))
s+=2
结果为:
series的index的标签可以是不唯一的,也就是说同一个index的标签可以出现多次,如果查询不唯一的标签是,最后返回的结果的类型也是一个series:

要注意其中的append方法,它不会在原series上进行操作,而是返回一个新的series,这种现象在pandas中很常见。
二、The DataFrame Data Structure:
DataFrame数据结构是Pandas库的核心,经常用于数据分析和数据清洗任务中,DataFrame类型类似于数据库表结构,具有行索引和列索引,可以将DataFrame想成是由相同索引的Series组成的dictionary类型。其实可以把它看出一个二维的带标签的数组。
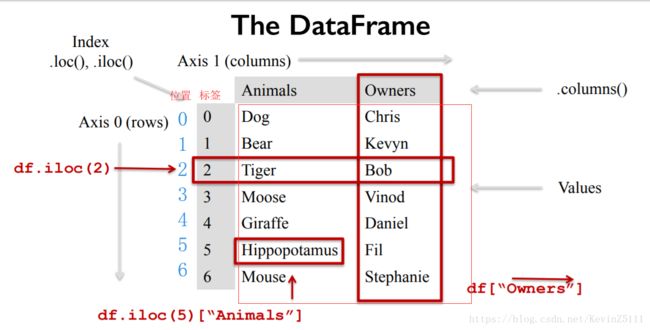
1.创建DataFrame:
使用一组series创建:
每个series代表DataFrame中的一行数据:
import pandas as pd
purchase_1 = pd.Series({'Name': 'Chris',
'Item Purchased': 'Dog Food',
'Cost': 22.50})
purchase_2 = pd.Series({'Name': 'Kevyn',
'Item Purchased': 'Kitty Litter',
'Cost': 2.50})
purchase_3 = pd.Series({'Name': 'Vinod',
'Item Purchased': 'Bird Seed',
'Cost': 5.00})
df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=['Store 1', 'Store 1', 'Store 2'])
df.head()
使用一组dictionary创建:
每个dictionary代表DataFrame中的一行数据,当由嵌套的字典类型生成DataFrame的时候,外部的字典索引会成为列名,内部的字典索引会成为行名。生成的DataFrame会根据行索引排序。
pop = {'Nevada': {2001: 2.4, 2002: 2.9},'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = pd.DataFrame(pop)
frame3
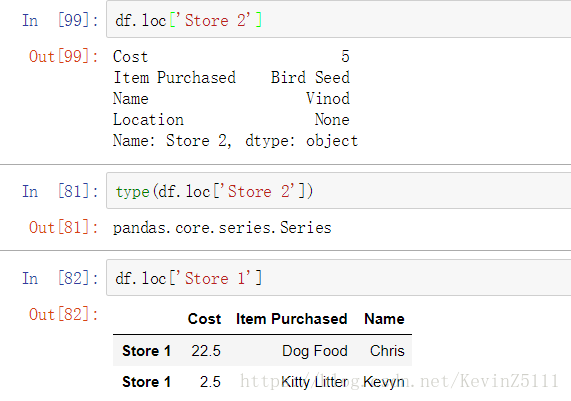
要注意的是,index和列名(column names)分别是指DataFrame的行和列,而且它们的值可以是不唯一的。
2.根据行、列获取数据:
如果我们为loc、iloc属性传递了两个参数,第一个参数是行的index值,第二个参数是列名,那么这样会返回具体位置上的数据:
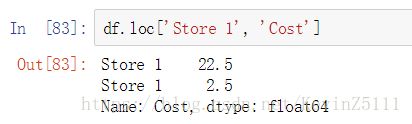
还有一个问题,如果我们想要根据列名来获取数据,那该怎么办?
方法一:将DataFrame进行装置,然后在loc属性进行获取;
例如,想要获取列名为Cost的所有数据:
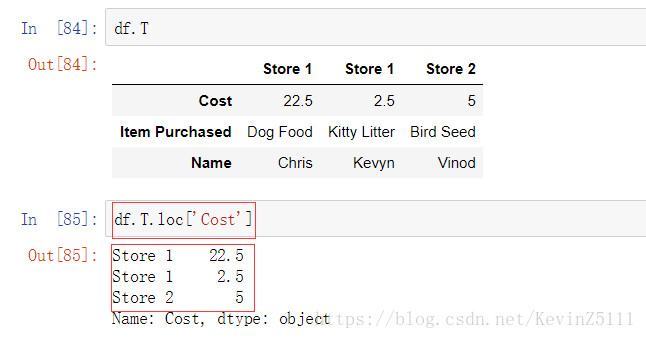
但是不推荐使用这种方法,因为有时候这会带来一些bug。
方法二:由于方括号操作符("[]")能根据其中给定的参数,获取DataFrame和series里的数据,而且在DataFrame里每一列都是有列名的,所以不会出现像在series里中使用的错误,而且这种操作类似于数据库中的投影。
例如,还是获取列名为Cost的所有数据:

而且,我们还可以联动的使用方括号操作符("[]"):
例如:
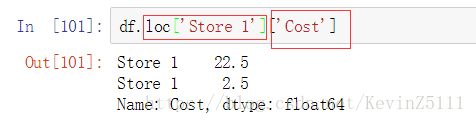
但是不推荐使用这种方法,因为这样返回的是要选择的数据的一个副本而不是投影,这样会造成一些花销,而且在联动使用的情况下还会出现bug。
此外,loc、iloc属性还支持分片操作,由于loc、iloc属性是进行的行选择(row selection),而且它们可以接受两个参数,所以只要将第一个参数设置为冒号(":"),这样就会包含所有的行,在给第二个参数设置成想要的列(可以是String类型,表示一列;也可以是list类型,表示多列):
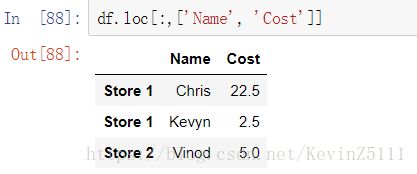
3.删除行或列:
删除行、列:可以使用drop函数进行删除,该函数的参数可以是行的idnex或者列名,但是要注意的是,drop函数并不会对原DataFrame进行操作,而是返回一个已经完成删除操作的结果DataFrame,这个特性和append函数很相似:
drop函数的签名为:
copy_df.drop(labels, axis=0, level=None, inplace=False, errors='raise')
其中axis=0表示行,axis=1表示列;inplace=true表示会在原DataFrame上进行删除操作,inplace=false表示不会;
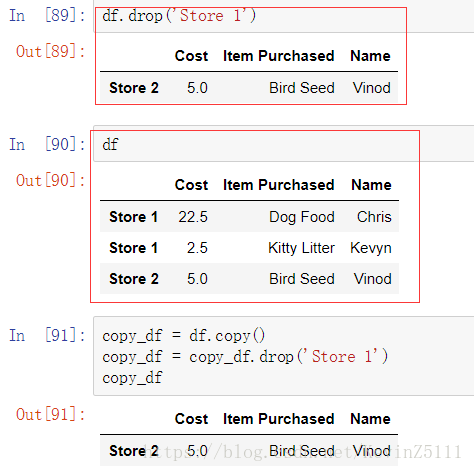
还可以使用del关键字进行删除:这个删除是直接作用在原DataFrame上的,不会返回任何值
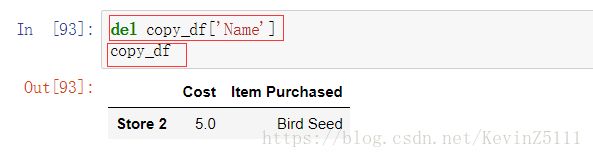
添加一列:
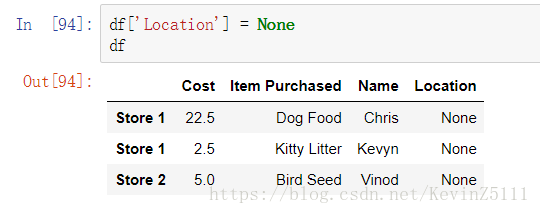
4.DataFrame的索引和载入:
通常来说,我们在进行数据处理时的工作流程是,首先读取数据到DataFrame中,然后取出DataFrame里感兴趣的特定行或列进行操作。而且Pandas返回的是DataFrame的一个视图,这样比起返回一个副本的情况更加高效且节省内存。但是这也意味着,但你在操作某些数据时,其实是在原DataFrame上直接操作、修改。

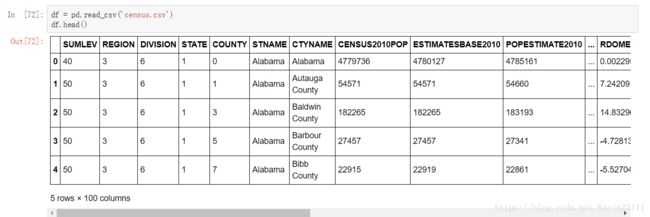
此外。pandas支持直接读取CSV文件、关系型数据库、Excel文件、HTML文件等等。
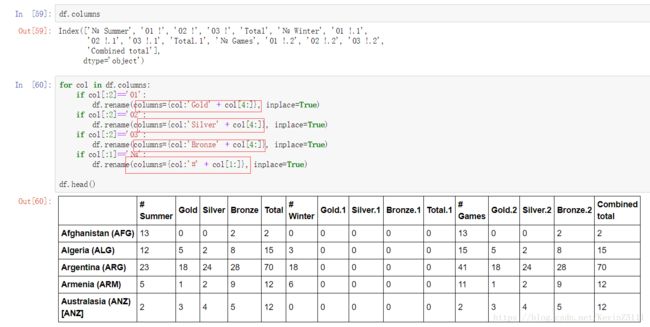
例如,我们从CSV文件中读取每个国家在奥运会中获得的奖牌的数目:
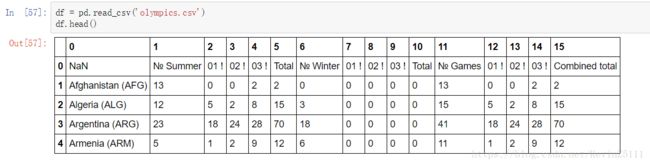
从上图我们可以看出,实际上我们应该把第二列的国家名作为DataFrame行的index,而把第二行获奖情况作为DataFrame的列名。所以,我们要为read_csv函数设置相应的参数,将index_col参数设置为0,这表示将列的index值为0的列,即第二列,作为DataFrame的index;将skiprows参数设置为1,这表示跳过一行,即将第二行作为DataFrame列名。最后的结果如下图:
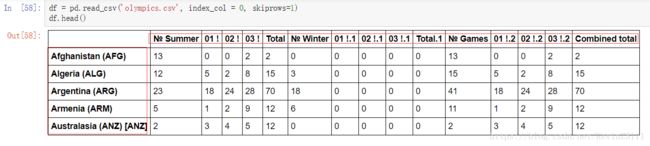
仔细观察上图,表中任然有些意思不明确的数字符号,所以需要我们清洗数据文件。我们可以操作CSV文件,也可以操作DataFrame的列名来达到效果:
5.Boolean Masking:
Boolean Masking 是Numpy能高效进行查询的核心,一个Boolean Mask其实是一个数组,就像一维的Series、二维的DataFrame一样,但是Boolean Mask其中的值是true或false。我们可以把Boolean Mask应用于我们需要查询的DataFrame或Series上。具体地,如下图所示:

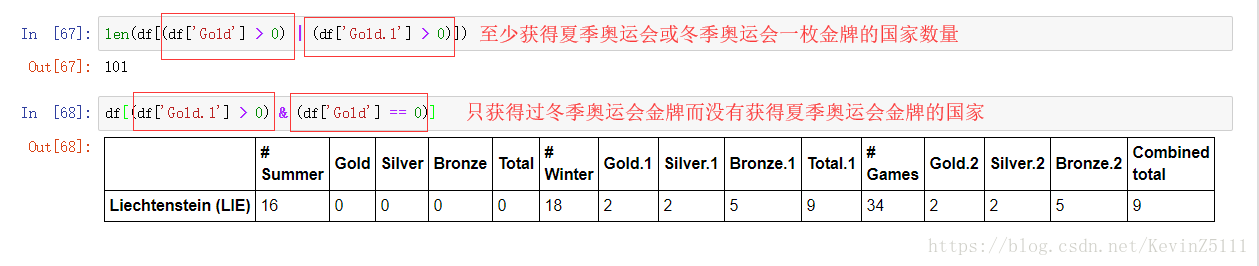
例如,我们想得到在夏季奥运会上至少获得一枚金牌的国家:
方法一:
第一步,得到在夏季奥运会上至少获得一枚金牌对应的一个Boolean Mask

第二步:使用where函数将Boolean Mask覆盖在DataFrame上,从而实现查询:
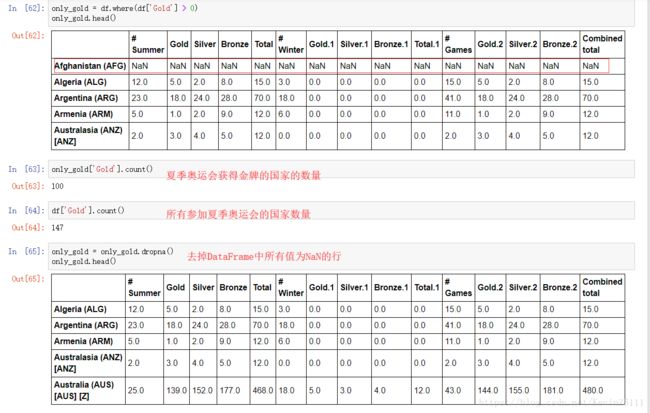
where函数把Boolean Mask作为条件,把这个条件应用于DataFrame或者Series上,并且返回一个与原DataFrame或Series相同形状的DataFrame或Series。
虽然在DataFrame中大部分的内置统计函数都能忽略NaN,但是我们还是有必要处理一下NaN,我们可以使用dropna函数来处理,
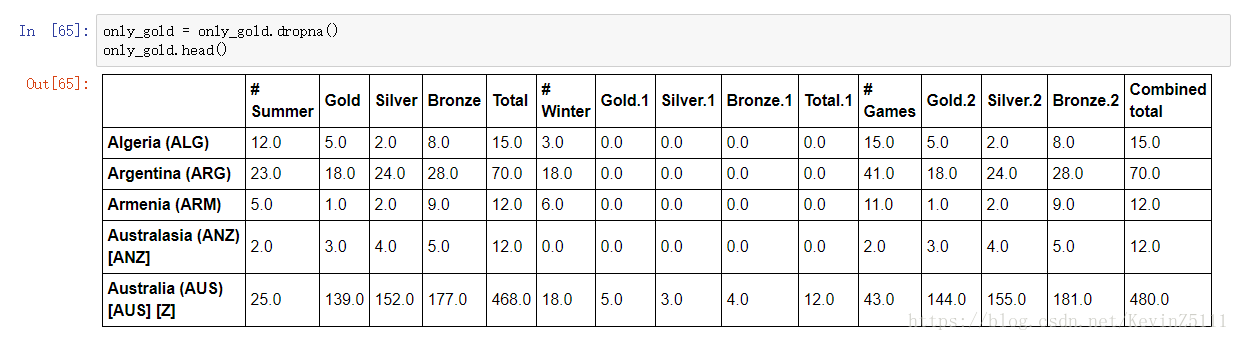
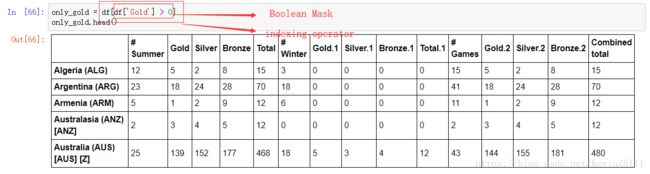
方法二:直接将Boolean Mask作为索引操作符(即方括号)的参数
此外,还能使用逻辑操作符对多个Boolean Mask进行操作,
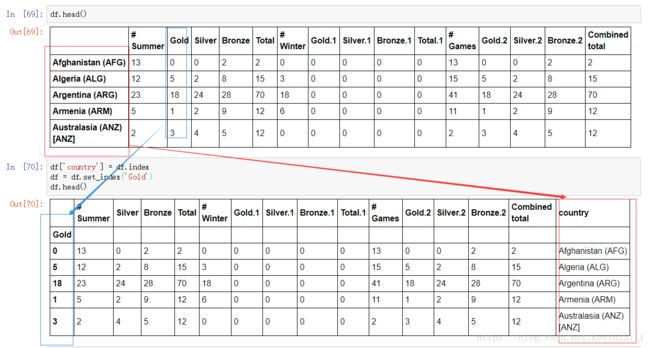
6.处理DataFrame的index:
正如之前所看到的,能将索引(index)应用于DataFrame和Series,索引本质上就是一个行标签。而且我们可以通过set_index函数来改变DataFrame或Series的索引,该函数将某一列名作为参数,把该列变成该DataFrame的索引,要注意的是set_index函数是破坏性的,即它不会保存之前的索引。如果你想保持之前的索引,那就要先使用index属性获得之前的索引,然后创建新的一列并且把之前的索引拷贝过去。
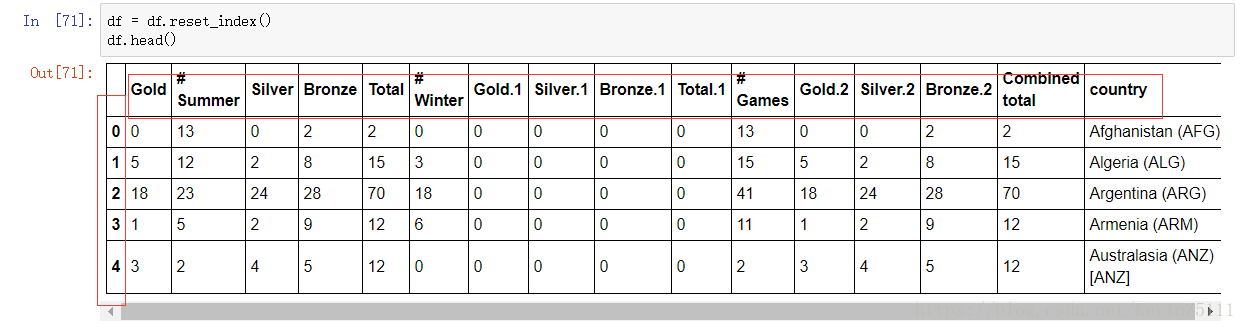
我们可以通过rest_index函数将DataFrame的索引重新设置成数值形式:
此外。pandas具有多层次索引的功能,这个特性类似于关系型数据库中的复合主键。我们可以通过给set_index函数设置一个list类型的参数来达到这个目的。
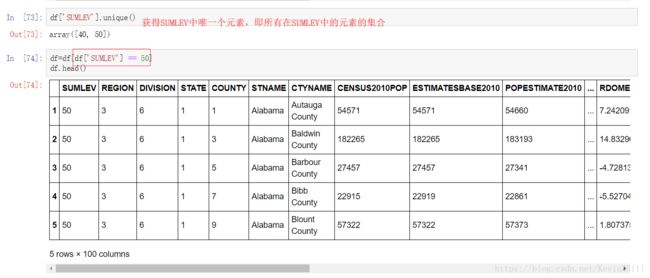

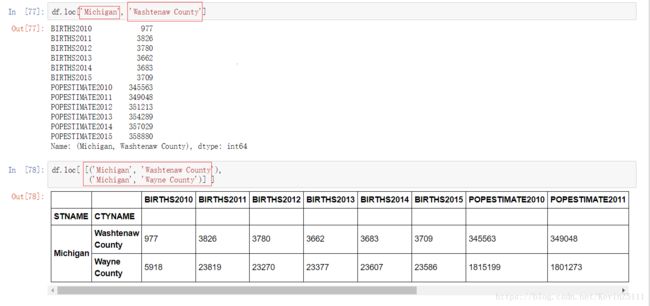
同样地,我们也可以使用iloc、loc属性进行数据获取:
7.处理DataFrame中缺失的值:
