Lucene排序取TopN源码分析
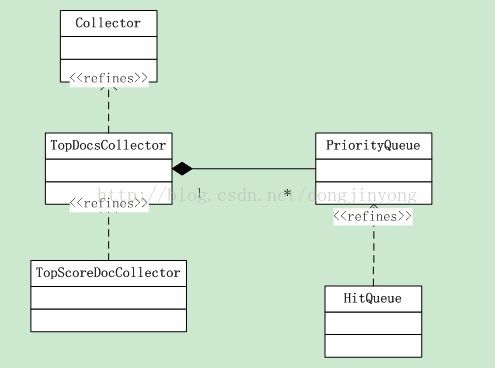
通过分析lucene源码可知,lucene每命中一个结果,就调用一次collector.collect(doc)方法,由Collector把结果保存到一个PriorityQueue中。对于常见的取TopN的情况,通常实例化一个org.apache.lucene.search.TopDocsCollector的子类对象A,这些类之间的关系如下:
(一)org.apache.lucene.util.PriorityQueue的内部实现
这个优先级队列被用来实现堆排序。堆用一个一位数组表示,长为size()+1,第0个元素没有实际用途,第1个元素就是堆顶元素。每次出堆,要把堆顶元素移出(按堆排序原理,pop后可以放数组后面,从后往前放,最终使数组有序;但lucene提供的这个类没这么做,只是把堆尾置null,size--,数组是private的,外部无法直接访问)。如果需要获取N个元素从大到小的序列,只需把它们全部入堆,再全部出堆,使用小顶堆比较合适。特别需要注意的是,除了add()方法之外,还有一个方法insertWithOverflow():
public T insertWithOverflow(T element) {
if (size < maxSize) {
add(element);
returnnull;
} elseif (size > 0 && !lessThan(element, heap[1])) {
T ret = heap[1];
heap[1] = element;
updateTop();
return ret;
} else {
return element;
}
}
这个方法很重要,它把想要入堆的元素和堆顶元素做比较,决定是否该入堆,从而使取topN时,堆的空间复杂度控制在O(N),降低了开销。
到底该使用大顶堆还是小顶堆呢?分析如下:
小顶堆:如果按从大到小取topN的话,只需初始化堆大小为N,入堆时调用insertWithOverflow()方法。这个方法非常重要,它把想要入堆的元素和堆顶元素做比较,决定是否该入堆,从而使堆空间复杂度降低。堆空间复杂度降低,会使堆的深度降低,对时间性能上也有提升。为获得TopN,最后还需要先把堆中所有元素弹出。需要注意的是:最先弹出的是topN里的最小值,最后弹出的才是最大值。
大顶堆:如果按从大到小取TopN的话,初始化的对大小必须为元素的总个数,只能add。堆占用的数组空间比小顶堆要大,建堆性能劣于小顶堆。出堆时,最先出的就是最大值。可见,取TopN,小顶堆优于大顶堆。但如果取lastN(按从大到小,排在最后面的N个元素),则大顶堆更有优势,这时大顶堆可以实现一个insertWithOverflow()方法。
PriorityQueue有两种模式:
1. pre-populate=false,不用重写getSentinelObject()方法,堆的size()方法可以直接用。初始化堆的大小应该根据实际需求来设置,使用时需注意区分add()和insertWithOverflow()方法,如果错误使用add()有数组下标越界的可能。
2. pre-populate=true。该类的源码注释很清楚:关于入堆、出堆、size都有特殊用法,size需要自己来维护,使用者应自己知道堆里有多少元素,知道每一步操作到底使堆发生哪些变化。相比之下,pre-populate=true的性能应该更优,它会在初始化堆数组的时候,一次性全部初始化数组里的所有元素,集中创建对象。所以看lucene的默认实现,基本都采用了pre-populate=true的用法。这种模式下,必须重写protected T getSentinelObject()方法,以便初始化堆数组。Add一个元素,主要包括以下步骤:
* MyObject pqTop = pq.top();
* pqTop.change().
* pqTop = pq.updateTop();
PriorityQueue类的其它方法:
1.
protected final Object[] getHeapArray() {
return (Object[]) heap;
}
个人感觉这个方法价值不大,返回的数组很难满足业务需要,因为pop时把数组后面元素置为null了,所以取topN还需使用者自己再创建一个数组,有些浪费。
2.
public final T pop() {
……
heap[size] = null; // permit GC of objects
size--;
……
}
这个方法会把堆size--。在pre-populate=true的用法中,size()方法返回的值是没有实际意义的,堆初始化时即设置size为maxSize,top()、updateTop()不影响size,pop()影响size。
(二)org.apache.lucene.search.HitQueue
从源码看,HitQueue 是一个final类,继承了PriorityQueue, 小顶堆, prePopulate=true,使用时需关注size的含义。
(三)Collector的子类
1. 建堆过程。
TopScoreDocCollector使用了HitQueue,参见OutOfOrderTopScoreDocCollector的部分源码,在collect(doc)过程中完成建堆过程:
OutOfOrderTopScoreDocCollector.collect(int doc):
if (score == pqTop.score && doc > pqTop.doc) {
// Break tie in score by doc ID:
return;
}
pqTop.doc = doc;
pqTop.score = score;
pqTop = pq.updateTop();
这种用法堆数组变化过程如下:
初始化之后对象状态:[ O1,O2,O3,……On ]
top更改:O1-->A1
updateTop()之后: [ On,O2,O3,……A1 ]
再更改top,再updateTop,……直至堆数组所有元素完成建堆。
2. 出堆过程。
在 org.apache.lucene.search.TopDocsCollector类中,topDocs(int start, int howMany)方法完成出堆排序的全过程,代码如下:
public TopDocs topDocs(int start, int howMany) {
int size = topDocsSize();
if (start < 0 || start >= size || howMany <= 0) {
return newTopDocs(null, start);
}
// We know that start < pqsize, so just fix howMany.
howMany = Math.min(size - start, howMany);
ScoreDoc[] results = new ScoreDoc[howMany];
for (int i = pq.size() - start - howMany; i > 0; i--) { pq.pop(); }
populateResults(results, howMany);
return newTopDocs(results, start);
}
其中,populateResults(results, howMany)会把topN放入一个新的数组返回。
protected void populateResults(ScoreDoc[] results, int howMany) {
for (int i = howMany - 1; i >= 0; i--) {
results[i] = pq.pop();
}
}