springdata elasticsearch详细接入方法
版本
spingboot 2.2.2.RELEASE
引入 spring-boot-starter-data-elasticsearch 可以不指定版本,工程会自动拉取springboot对应的版本依赖
elasticsearch server 6.8.4
如果指定使用版本,要注意兼容性问题,防止不兼容导致出现千奇百怪的错误
spring data 官方版本对照表,如果是新项目建议选用spring推荐的几个版本,太老的不值得接入和维护,成本太高,
官方版本地址:https://spring.io/projects/spring-data-elasticsearch#learn
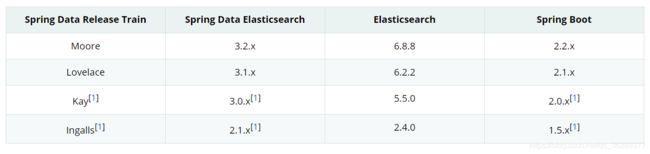
如果你的版本较新,请查看官方地址:https://docs.spring.io/spring-data/elasticsearch/docs/3.2.7.RELEASE/reference/html/#new-features.3-2-0
maven依赖
放到你项目的model层,因为springdata需要进行es实体类注解
org.springframework.boot
spring-boot-starter-data-elasticsearch
客户端配置
先附上官方文档:https://docs.spring.io/spring-data/elasticsearch/docs/3.2.7.RELEASE/reference/html/#elasticsearch.clients.rest
这里我们也采用官方推荐的REST Client方式,可能有些人还在使用配置文件的方式配置es连接信息,不过这里我们不推荐,
该方式已经被官方废弃了,请看:
还有一些老项目在使用Transport Client,我这里也不推荐使用,至于原因,官方文档说的很清楚:

我们着重来看下官方墙裂推荐REST Client配置方式
方法1 :一般来说,不需要验证的这种方式就可以了,自己可以将host和port定义到配置中
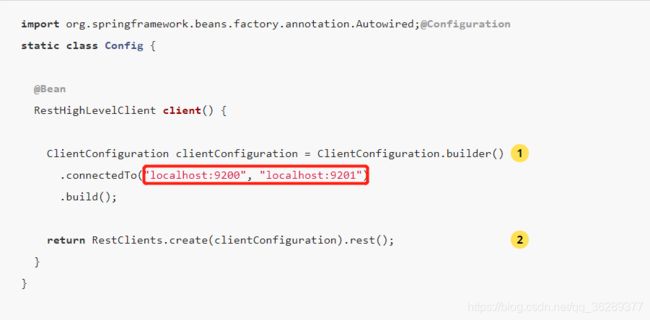
方法2:如果需要验证,那么就需要在HttpHeader添加用户名和密码,一般公司做了ES中间件或者做了权限的话通常都要验证
只需要在方法1中添加方法2框出来的红色配置即可,没有验证的es服务直接使用方法1。
我的使用demo,我将配置信息放入配置文件的自定义配置中,便于不同环境的切换,此为我的本地配置:

配置类注意需要添加启用注解:
@EnableElasticsearchRepositories 进行扫包,扫到实体类映射层,原理和jpa、mybatis一样@Configuration
@EnableElasticsearchRepositories(basePackages = "com.tino.repository")
public class EsRestClientConfig extends AbstractElasticsearchConfiguration {
@Value("${custom.elasticsearch.server}")
private String server;
@Value("${custom.elasticsearch.username}")
private String userName;
@Value("${custom.elasticsearch.password}")
private String password;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
// 设置用户名密码
HttpHeaders defaultHeaders = new HttpHeaders();
defaultHeaders.setBasicAuth(userName, password);
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(server)
.withDefaultHeaders(defaultHeaders)
.build();
return RestClients.create(clientConfiguration).rest();
}
}如何使用
实体类:假设为公司信息,这里我继承的实体是mongodb的实体,当然也可以是mybatis和jpa的,为什么不直接使用数据库的实体映射呢?两点:
1.我需要对多表数据做聚合,例如实体类中有个聚合数组为products:表示公司经营的产品,公司的产品我也希望可以参与到全文检索中去,如果不用怎么必须用多索引组合检索,增加了复杂度。
2.类和字段映射存在耦合和干扰,可以为全文检索业务和数据库增删改查业务解偶,比如,products我希望在es中持久化、在mongodb中不持久化,因为mongodb中produs存在单独的业务表中,那么不分开的话,靠@Transient
@Transient
private List products;
肯定无法解决这个问题,耦合度太高,扩展性被限制死了,想要增加更多内容,就不得不得通过其他方式,繁琐且低效。
当然我这种方式也不是最好的办法。数据同步也可以,不过那就更依赖运维和公共组件,而且可能仍然要定义单独的实体类。
这里有个问题,为什么不直接放弃数据库,用es存储元数据呢?
答案是当然可以,如果你的数据不经常改动,不用数据库完全可以满足你的业务需求,那么直接使用es存储元数据也并没有什么大问题。反之,es毕竟不是数据库,写入效率肯定不如mysql 、oracle、mongodb等,其他特性更加没法比较:事件、视图、触发器、图形化管理工具等等,对于复杂业务关系(多表关联)的维护起来也很难,如果需要做数据迁移,那么工作就更复杂了。当然随着更新,elastic公司也提供了付费版的es,使用上越来越接近数据库,但是普罗大众不可能都去付费,为了不产生这些问题,最好还是用数据库来维护元数据,有了数据库的保障,不管es数据有什么问题,索引都可以再建、重构。
基类,注意两种@Id配置

mongodb实体
/**
* 公司信息 mongodb实体
*
* @author tino
* @date 2020/4/14
*/
@org.springframework.data.mongodb.core.mapping.Document(collection = "gls_company_info")
public class CompanyInfoModel extends BaseModel {
/**
* 公司编号
*/
private Long companyCode;
/**
* 公司名称
*/
private String companyName;
/**
* 公司logo
*/
private String logo;
/**
* 组织机构代码
*/
private String orgCode;
public Long getCompanyCode() {
return companyCode;
}
public void setCompanyCode(Long companyCode) {
this.companyCode = companyCode;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getLogo() {
return logo;
}
public void setLogo(String logo) {
this.logo = logo;
}
public String getOrgCode() {
return orgCode;
}
public void setOrgCode(String orgCode) {
this.orgCode = orgCode;
}
}es实体
/**
* 全文检索公司信息实体
*
* @author tino
* @date 2020/4/22
*/
@org.springframework.data.elasticsearch.annotations.Document(indexName = "gls", type = "gls_company_info", shards = 1, replicas = 0)
public class EsCompanyModel extends CompanyInfoModel {
public EsCompanyModel() {
}
public EsCompanyModel(List products) {
this.products = products;
}
/**
* 公司产品
*/
private List products;
public List getProducts() {
return products;
}
public void setProducts(List products) {
this.products = products;
}
repository
方法1:和jpa一样,需要什么继承什么,我这里需要分页和自定义检索功能,所以我继承
ElasticsearchRepository PagingAndSortingRepository方法2:如果你需要springdata 根据方法名称查询的功能,继承
ElasticsearchCrudRepository方法3:elasticsearchTemplate,喜欢的可以用,灵活性高。需要注入elasticsearchTemplate bean,不懂看官方
https://docs.spring.io/spring-data/elasticsearch/docs/3.2.7.RELEASE/reference/html/#elasticsearch.query-methods
这里只讲我使用的方法1,如果你对jpa或者springdata比较陌生,又想可以恶补一下官方文档对于查询的指引:
https://docs.spring.io/spring-data/elasticsearch/docs/3.2.7.RELEASE/reference/html/#elasticsearch.query-methods
为了便于我们重复使用,这里定义一个
基类Repository
/**
* es基础接口
*
* @author tino
* @date 2020/4/22
*/
public interface BaseEsDao extends ElasticsearchRepository, PagingAndSortingRepository {
} 如果你想使用方法2,可以再定义一个基类 继承 ElasticsearchCrudRepository:
BaseCrudRepository命名为dao只是个人习惯,个人可以Repository、Mapper随意。
公司Repository
@Repository注入到spring容器,如果是mybatis项目也不要使用@Mapper,应该没人那么傻吧,哈哈哈!/**
* es公司信息接口
*
* @author tino
* @date 2020/4/22
*/
@Repository
public interface EsCompanyDao extends BaseEsDao {
} service层
/**
* 公司信息搜素接口
*
* @author tino
* @date 2020/4/22
*/
public interface EsSearchService extends BaseService {
/**
* 保存索引
*
* @param companyInfoModel
*/
void saveIndex(CompanyInfoModel companyInfoModel);
/**
* 根据内容分页检索结果
*
* @param categoryType
* @param content
* @param pageInfo
* @return
*/
Page search(Integer categoryType, String content, PageInfo pageInfo);
} BaseService写不写无所谓,里面我只放了logger,擅用继承可以多定义基础父类
service实现
/**
* es搜索
*
* @author tino
* @date 2020/4/22
*/
@Service
public class EsSearchServiceImpl extends BaseServiceImpl implements EsSearchService {
@Autowired
private EsCompanyDao esCompanyDao;
@Autowired
private ProductService productService;
@Autowired
private CompanyInfoService companyInfoService;
@Transactional(rollbackFor = Exception.class)
@Override
public void saveIndex(CompanyInfoModel companyInfoModel) {
if (null == companyInfoModel
|| StringUtils.isBlank(companyInfoModel.getId())
|| null == companyInfoModel.getUserCode()
|| null == companyInfoModel.getCompanyCode()) {
BaseException.exception(BaseErrorCode.PARAM_ERROR);
return;
}
EsCompanyModel esCompanyModel = new EsCompanyModel();
BeanUtils.copyProperties(companyInfoModel, esCompanyModel);
List productModels = productService.listByCompanyCode(companyInfoModel.getCompanyCode());
esCompanyModel.setProducts(productModels);
esCompanyDao.save(esCompanyModel);
}
@Override
public Page search(Integer categoryType, String content, PageInfo pageInfo) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 根据产品分裂条件进行精确匹配
if (null != categoryType) {
boolQueryBuilder.must(QueryBuilders.multiMatchQuery(categoryType, "products.categoryType"));
}
// 构建查询条件
if (StringUtils.isNotBlank(content)) {
boolQueryBuilder.should(QueryBuilders.multiMatchQuery(content, "products.route").boost(4))
.should(QueryBuilders.multiMatchQuery(content, "city").boost(3))
.should(QueryBuilders.multiMatchQuery(content, "companyName").boost(2))
.should(QueryBuilders.multiMatchQuery(content, "address").boost(1));
}
// 设置排序规则
Sort sort = Sort.by(Sort.Direction.DESC, "companyCode", "createDate.keyword");
// 组织分页参数
Pageable pageable = PageRequest.of(pageInfo.getPageNum(), pageInfo.getPageSize(), sort);
// 搜索,获取结果
Page page = new Page(new com.github.pagehelper.Page());
try {
// 将分页对象重构为与其他模块相同的分页数据结构
org.springframework.data.domain.Page result = esCompanyDao.search(boolQueryBuilder, pageable);
page.setList(result.getContent());
page.setTotal(result.getTotalElements());
page.setPages(result.getTotalPages());
page.setPageNum(result.getPageable().getPageNumber());
page.setPageSize(result.getPageable().getPageSize());
} catch (Exception e) {
// 当es中索引为空时,可能会出现错误
logger.error("在es中未查询到结果", e);
}
return page;
}
} BoolQueryBuilder的设计思路和mongodb的 Criteria非常相似,提供链式编程方式,使用起来和elasticsearchTemplate一样灵活boost(1)表示权重,数字越大越根据该条件查到的结果越靠前其他查询的方式有很多种,具体可以查看QueryBuilders的源码
通过聚合条件搜索,不管是聚合对象还是数组可以通过 【.】 的方式进行连接, 是不是和mongdo 的Criteria非常像?例如以长产品数组中的路线作为条件查询和排序:products.route
排序需要构建排序对象,支持多条件排序查询,效果和sql一样
1.多条件倒叙
Sort sort = Sort.by(Sort.Direction.DESC, "companyCode", "createDate.keyword");
2.多条件多排序
Sort sort = Sort.by(Sort.Direction.DESC, "companyCode")
.and(Sort.by(Sort.Direction.ASC, "createDate.keyword"));3.通过子对象种的属性排序,假设子对象属性名为 child
Sort sort = Sort.by(Sort.Direction.DESC, "child.count", "createDate.keyword");注意:保存索引的时机应该是每次保存公司信息后,如果觉得慢可以通过异步方法更新,注意事务问题。
常见问题
1.根据时间字段排序,出现
Caused by: org.elasticsearch.ElasticsearchException: Elasticsearch exception [type=illegal_argument_exception, reason=Fielddata is disabled on text fields by default. Set fielddata=true on [createDate] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]
添加keyword标识后,日期才能参与排序
![]()
2.没有数据是报错
也是排序字段引起的,排序字段必须存在,此种错我建议捕获记录即可
3.json序列化错误
com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Cannot construct instance of `com.yunlsp.gls.api.model.children.CompanyTimesModel` (no Creators, like default construct, exist)检查实体类的聚合数组或者对象种是否包含了无参构造方法(如果类中只有有参构造方法时,es对数据进行序列化会找不到无参构造方法导致序列化失败)