还没理顺IO流?进来看看吧!
文章目录
-
-
- 1.字节流(InputStream、OutputStream)
- 2.字符流(Reader、Writer)
- 3.处理流InputStreamReader、OutputStreamWriter
- 4.上面三种流之间的关系
- 5.缓冲流
-
-
-
- (1)字节缓冲流
- (2)字符缓冲流
-
-
- 6.序列化反序列化
- 7.拓展
-
- 经验
-
最后还是变成了标题党,哈哈。第一次起这么骚的标题。勿喷!
来,和我一起复习IO流这块内容吧!这块知识点其实算简单,但是尝尝因为太多而被绕晕了!这次目标是清清楚楚,清爽的八大鸟!
先上个图:
 这篇博客主要就是围绕上图。
这篇博客主要就是围绕上图。
1.字节流(InputStream、OutputStream)
这是最基础的子一对输入输出流。属于字节流。用法如下:
public class IsTest {
public static void main(String[] args) throws Exception{
File file = new File("C:/Users/Administrator/Desktop/123.txt");
byte[] bytes1 = new byte[20];
byte[] bytes2= new byte[]{'a','b','c'};
/*if (file.exists()){
InputStream inputStream = new FileInputStream(file);
System.out.println(inputStream.read(bytes1));
}*/
if (file.exists()){
OutputStream outputStream = new FileOutputStream(file);
outputStream.write(bytes2);
}
}
}
2.字符流(Reader、Writer)
这一对相较于上一对的主要区别就在于每次读取或者输出的单位更大。字符肯定比字节大,所以也理所当然的效率更高!UTF-8环境下,1个英文或者符号对应1个字节,1个中文字对应3个字节。
Reader:
public class Test2 {
public static void main(String[] args) throws Exception {
Reader reader = new FileReader("C:/Users/Administrator/Desktop/123.txt");
char[] chars = new char[8];
//offset
int length = reader.read(chars,2,3);
System.out.println("数据流的长度是"+length);
System.out.println("遍历数组");
for (char aChar : chars) {
System.out.println(aChar);
}
}
Writer:
public class Test {
public static void main(String[] args) throws Exception {
Writer writer = new FileWriter("/Users/southwind/Desktop/copy.txt");
//writer.write("你好");
// char[] chars = {'你','好','世','界'};
// writer.write(chars,2,2);
String str = "Hello World,你好世界";
writer.write(str,10,6);
writer.flush();
writer.close();
}
}
字符流的基本操作就是这样了,方法很多不一一写了。
值得注意的是,字符流还是在字节流的基础上操作的,并且我们已经在上述代码中和处理流打上交道了。看一下FileWriter或FileReader源码便一目了然:

 下面要说的处理流InputStreamReader、OutputStreamWriter已经出现了。
下面要说的处理流InputStreamReader、OutputStreamWriter已经出现了。
 同样看字节流代码中FileInputStream的源码你会发现,这里的不同就在于FileReader不是直接在继承自Reader的,之间多了个处理流。而这个处理流,顾名思义,就是一个有把字节流变成字符流作用的处理流。
同样看字节流代码中FileInputStream的源码你会发现,这里的不同就在于FileReader不是直接在继承自Reader的,之间多了个处理流。而这个处理流,顾名思义,就是一个有把字节流变成字符流作用的处理流。
3.处理流InputStreamReader、OutputStreamWriter
2中其实已经提到了处理流,看源码也不难发现,处理流是在操作字节流。从这里也能直观的看出节点流和处理流的区别:就是处理流是作用在流上的,不能直接作用在文件上。而像字节字符流这些节点流是可以直接作用在文件上的。
测试代码:
InputStreamReader:
public class Test {
public static void main(String[] args) throws Exception {
//基础管道
InputStream inputStream = new FileInputStream("C:/Users/Administrator/Desktop/123.txt");
//处理流
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
char[] chars = new char[1024];
int length = inputStreamReader.read(chars);
inputStreamReader.close();
String result = new String(chars,0,length);
System.out.println(result);
}
}
OutputStreamWriter:
public class Test2 {
public static void main(String[] args) throws Exception {
String str = "你好 世界";
OutputStream outputStream = new FileOutputStream("/Users/southwind/Desktop/copy.txt");
OutputStreamWriter writer = new OutputStreamWriter(outputStream);
writer.write(str,2,1);
//writer.flush();
writer.close();
}
}
4.上面三种流之间的关系

感觉这张图还算清晰吧。他们之间的关系这么记,我个人是觉得印象深刻!
5.缓冲流
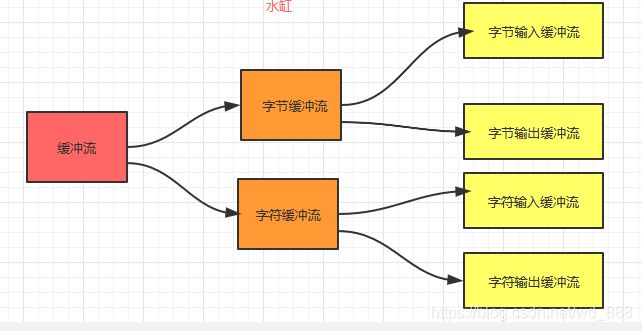
⽆论是字节流还是字符流,使⽤的时候都会频繁访问硬盘,对硬盘是⼀种损伤,同时效率不⾼,缓冲流在这种背景下应运而生。
缓冲流⾃带缓冲区,可以⼀次性从硬盘中读取部分数据存⼊缓冲区,再写⼊内存,这样就可以有效减少对硬盘的直接访问并且提高效率。
(1)字节缓冲流
字节输⼊缓冲流
public class Test {
public static void main(String[] args) throws Exception {
//1、创建节点流
InputStream inputStream = new FileInputStream("/Users/southwind/Desktop/test.txt");
//2、创建缓冲流
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
// int temp = 0;
// while ((temp = bufferedInputStream.read())!=-1){
// System.out.println(temp);
// }
byte[] bytes = new byte[1024];
int length = bufferedInputStream.read(bytes,10,10);
System.out.println(length);
for (byte aByte : bytes) {
System.out.println(aByte);
}
bufferedInputStream.close();
inputStream.close();
}
}
就字节流来说,字节缓冲流的效果并不明显。但是字符缓冲流就能明明显的看出区别了。
(2)字符缓冲流
字符输入缓冲流
public class Test2 {
public static void main(String[] args) throws Exception {
//1、创建字符流(节点流)
Reader reader = new FileReader("/Users/southwind/Desktop/test.txt");
//2、创建缓冲流(处理流)
BufferedReader bufferedReader = new BufferedReader(reader);
String str = null;
int num = 0;
System.out.println("***start***");
while ((str = bufferedReader.readLine())!=null){
System.out.println(str);
num++;
}
System.out.println("***end***,共读取了"+num+"次");
bufferedReader.close();
reader.close();
}
}
字符输入缓冲流的readline方法的效果就很明显,一次性就读取了一整行。
字符输出缓冲流
public class Test2 {
public static void main(String[] args) throws Exception {
Writer writer = new FileWriter("/Users/southwind/Desktop/test2.txt");
BufferedWriter bufferedWriter = new BufferedWriter(writer);
// String str = "由于在开发语言时尚且不存在运行字节码的硬件平台,所以为了在开发时可以对这种语言进行实验研究,他们就在已有的硬件和软件平台基础上,按照自己所指定的规范,用软件建设了一个运行平台,整个系统除了比C++更加简单之外,没有什么大的区别。";
// bufferedWriter.write(str,5,10);
char[] chars = {'J','a','v','a'};
// bufferedWriter.write(chars,2,1);
bufferedWriter.write(22902);
bufferedWriter.flush();
bufferedWriter.close();
writer.close();
}
}
6.序列化反序列化
序列化就是将内存中的对象输出到硬盘⽂件中保存。
反序列化就是相反的操作,从⽂件中读取数据并还原成内存中的对
象。
上面都还么有涉及到实体类对象,读写实体类对象时我们就要用到序列化技术了。
(1)序列化
public class Test {
public static void main(String[] args) throws Exception {
User user = new User(1,"张三",22);
OutputStream outputStream = new FileOutputStream("/Users/southwind/Desktop/obj.txt");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
objectOutputStream.writeObject(user);
objectOutputStream.flush();
objectOutputStream.close();
outputStream.close();
}
}
(2)反序列化
public class Test2 {
public static void main(String[] args) throws Exception {
InputStream inputStream = new FileInputStream("/Users/southwind/Desktop/obj.txt");
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
User user = (User) objectInputStream.readObject();
System.out.println(user);
objectInputStream.close();
inputStream.close();
}
}
User
package com.southwind.entity;
import java.io.Serializable;
public class User implements Serializable {
private Integer id;
private String name;
private Integer age;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
public User(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
}
7.拓展
在看源码中常常看见一些借口,总结一下他们的作用。
 Appendable 接⼝可以将 char 类型的数据读⼊到数据缓冲区
Appendable 接⼝可以将 char 类型的数据读⼊到数据缓冲区

Readable可以将数据以字符的形式读⼊到缓冲区。
 Flushable接口只有输出流有。Flushable 是可刷新数据的目标地。调用 flush 方法将所有已缓冲输出写入底层流。 这是JDK的定义。我自己的理解就是,防止输出有丢失,强制把所有数据都刷新到目标地。
Flushable接口只有输出流有。Flushable 是可刷新数据的目标地。调用 flush 方法将所有已缓冲输出写入底层流。 这是JDK的定义。我自己的理解就是,防止输出有丢失,强制把所有数据都刷新到目标地。
经验
- 文本类型(Excel、word、txt…)一般用字符流操作(当然也可以用字节流)
- 而非文本类型(图片,音频,视频…)不能用字符流操作,只能用字节操作。