基于中文维基百科的词向量构建及可视化
你将使用Gensim和维基百科获得你的第一批中文词向量,并且感受词向量训练的基本过程。

词向量原理详解请参考:
词向量技术原理及应用详解(一)
词向量技术原理及应用详解(二)
词向量技术原理及应用详解(三)
词向量训练实践请参考:
词向量技术原理及应用详解(四)
运行环境:
IDE:Pycharm2019
python版本:3.6.3
电脑配置:window7,i7,16G内存
Step-01:使用维基百科下载中文语料库
Corpus: https://dumps.wikimedia.org/zhwiki/20190720/
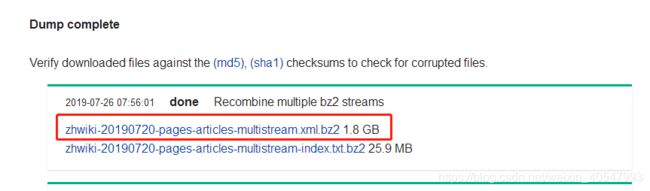
百度云盘下载:
链接:https://pan.baidu.com/s/1q54CAKPQ1ZVTMtCZ5jWG6g
提取码:bg2d
Step-02:使用python wikipedia extractor抽取维基百科的内容
从下载的语料库xml格式的压缩包中抽取维基百科的内容,将里面的繁体字转化为简体字(由于维基百科中有很多是繁体中文网页)。另外,在用语料库训练词向量之前需要对中文句子进行分词,这里采用 Jieba中文分词工具对句子进行分词 ,并保存在reduce_zhiwiki.txt文档中。 具体实现方式如下:
# -*- coding: utf-8 -*-
from gensim.corpora import WikiCorpus
import jieba
from langconv import *
def my_function():
space = ' '
i = 0
l = []
zhwiki_name = './data/zhwiki-20190720-pages-articles-multistream.xml.bz2'
f = open('./data/reduce_zhiwiki.txt', 'w',encoding='utf-8')
wiki = WikiCorpus(zhwiki_name, lemmatize=False, dictionary={}) #从xml文件中读出训练语料
for text in wiki.get_texts():
for temp_sentence in text:
temp_sentence = Converter('zh-hans').convert(temp_sentence) #繁体中文转为简体中文
seg_list = list(jieba.cut(temp_sentence)) #分词
for temp_term in seg_list:
l.append(temp_term)
f.write(space.join(l) + '\n')
l = []
i = i + 1
if (i %200 == 0):
print('Saved ' + str(i) + ' articles')
f.close()
if __name__ == '__main__':
my_function()
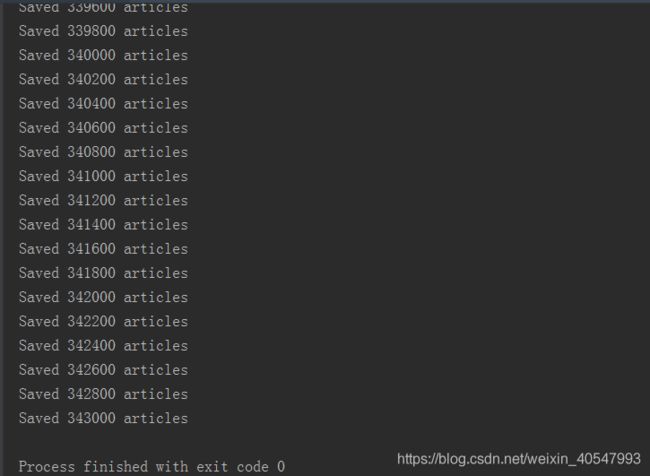
程序运行过程中如下图,总共有近34万篇维基百科文章,提取内容时长大概1-2个小时:
处理后的语料如图所示,分词完成后存储的reduce_zhiwiki.txt文档有1.24G:

看到分词后的文件,在一般的NLP处理中,会需要去停用词等处理。由于word2vec的算法依赖于上下文,而上下文有可能就是停用词。因此对于word2vec,可以不用去停词,具体根据自己的情况决定。
另一种实现方式也可参考: https://github.com/attardi/wikiextractor
Step-03:使用Gensim进行词向量训练
Reference:
- https://blog.csdn.net/weixin_40547993/article/details/88782251
- https://radimrehurek.com/gensim/models/word2vec.html
参考Gensim的文档和Kaggle的参考文档,获得词向量。 注意,你要使用Jieba分词把维基百科的内容切分成一个一个单词,然后存进新的文件中。然后,你需要用Gensim的LineSentence这个类进行文件的读取。再训练成词向量Model。
在训练之前,你得了解Gensim里面的参数:
gensim工具包中详细参数:
在gensim中,word2vec相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。
算法需要注意的参数有:
1) sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。
2) size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
3) window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
4) sg: 即我们的word2vec两个模型的选择了。如果是0,则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
5) hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
6) negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
7) cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示,默认值也是1,不推荐修改默认值。
8) min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
9) iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
10) alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为,默认是0.025。
11) min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
12)worker:训练词向量使用时使用的线程数,默认为3。
在了解完gensim工具包中的参数后,词向量训练具体代码如下:
# -*- coding: utf-8 -*-
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
def my_function():
wiki_news = open('./data/reduce_zhiwiki.txt', 'r',encoding='utf-8')
model = Word2Vec(LineSentence(wiki_news), sg=0,size=200, window=5, min_count=5, workers=6)
model.save('./model/zhiwiki_news.word2vec')
if __name__ == '__main__':
my_function()
这里使用了word2vec提供的LineSentence类来读文件,然后套用word2vec的模型。里面的参数可以根据自己的需求来进行调参。
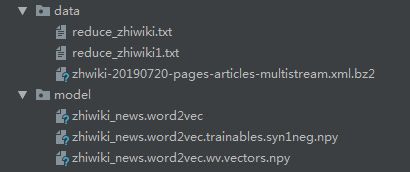
训练过程总共花了17分钟:

训练生成了model文件夹下的3个文件,如下图所示:
那训练出来的模型能打开看的吗 ? 如果直接打开都是乱码 ,但可以从model里面提取查看某一个单词的词向量 (Step-04有实践)。之前一直把它当黑盒了,不能看,只能从里面取,如果要看的话可能需要自己另外指定编码存储了。
实际上是可以指定存储为txt文档进行查看的,只用加一行代码,就可以查看所有词语的词向量,具体如下:
model.wv.save_word2vec_format('./data/word2vec_format.txt')
再打开word2vec_format .txt文档,可以查看所有词语的词向量,这里是拿一篇文章进行测试的,从下图可以看到这篇文章有116个词语,是50维的向量:

Step-04:测试同义词,找几个单词,看下效果
测试同义词,找几个单词进行测试
检测模型训练后的效果,可以根据词的相似度初步进行判断训练的效果:
#coding=utf-8
import gensim
import pandas as pd
def my_function():
model = gensim.models.Word2Vec.load('./model/zhiwiki_news.word2vec')
print(model.similarity('西红柿','番茄')) #相似度为0.60256344
print(model.similarity('西红柿','香蕉')) #相似度为0.49495476
# print(model.similarity('人工智能','大数据'))
# print(model.similarity('滴滴', '共享单车'))
result = pd.Series(model.most_similar(u'阿里巴巴')) #查找近义相关词
print(result)
result1 = pd.Series(model.most_similar(u'故宫'))
print(result1)
print(model.wv['中国']) #查看中国的词向量(单个词语的词向量)
if __name__ == '__main__':
my_function()
结果如下:
0.60256344
0.49495476
0 (马云, 0.7043435573577881)
1 (马化腾, 0.6246073842048645)
2 (淘宝网, 0.613457977771759)
3 (奇虎, 0.6117738485336304)
4 (联想集团, 0.605375349521637)
5 (携程, 0.5971101522445679)
6 (入股, 0.5965164303779602)
7 (陌陌, 0.5919643640518188)
8 (私募, 0.5906440019607544)
9 (第九城市, 0.5895131230354309)
dtype: object
0 (南院, 0.6943957805633545)
1 (北京故宫, 0.6514502763748169)
2 (故宫博物院, 0.6480587720870972)
3 (颐和园, 0.6093741655349731)
4 (大钟寺, 0.5974366664886475)
5 (首都博物馆, 0.5919761657714844)
6 (宝蕴楼, 0.5763161182403564)
7 (紫禁城, 0.5700971484184265)
8 (圆明园, 0.5676841735839844)
9 (北京故宫博物院, 0.5617257952690125)
dtype: object
[ 1.0179822 1.3085549 -0.15886988 2.2728844 0.30418944 -0.72818166
1.5713037 0.70873463 0.7049206 -0.27503544 -2.8415916 0.15120901
0.55266213 -0.97635883 1.1382341 0.13891749 -0.6220569 0.48901322
-2.3380036 -0.31055793 3.24562 -4.0859027 -0.579222 1.2372123
2.3155959 0.96481997 -3.6676245 -1.4969295 0.7837823 1.0870318
-0.6050227 0.8325408 1.328006 0.29150656 -2.5328329 -0.52930063
1.1638371 0.5451628 0.2401217 0.17821422 1.1282797 -0.6255923
-1.2899324 0.36619583 -0.46521342 2.7240493 -0.41811445 -1.3177891
0.32050967 -0.27907917 -0.02102979 2.1176116 1.4659307 -0.74454963
-1.3754915 0.26172 0.72916746 -0.78215885 0.9422904 -0.15639538
-1.9578679 -2.2291532 -1.604257 1.1513225 1.4394927 1.3663961
-0.23186158 2.1691236 0.70041925 4.0671997 0.6687622 2.2806919
1.1733083 0.8087675 1.143711 0.15101416 0.67609495 -0.37344953
-0.48123422 0.24116552 0.35969564 1.8687915 1.2080493 1.0876881
-1.8691303 -0.15507829 1.6328797 -2.5513241 -2.0818036 0.8529579
1.790232 0.9209289 2.8360684 0.46996912 -1.2465436 -1.7189977
0.30184388 1.5090418 -1.7590709 -0.6130559 -0.89942425 -0.16365221
-2.7557333 1.2682099 0.72216785 1.4142591 -0.12338407 2.2521818
2.242584 -1.2266986 1.5790528 -0.6049989 -1.2251376 0.04529851
1.2588772 1.4443516 1.9425458 -1.770078 -0.28633627 0.22818221
-1.1054004 0.05947445 0.6791499 0.8320315 0.07090905 -2.4605787
-2.8967953 1.5300242 2.3271239 -1.447048 -1.2444358 -0.82585806
0.20273234 0.6779695 0.03622686 -0.77907175 -1.756927 -0.5452485
1.0174141 2.8124187 -0.6510111 0.88718116 -4.1239104 -0.99753165
0.05194774 0.8445294 -1.0886959 -1.6984457 1.4602119 0.93301445
-1.0705873 0.5754465 -1.5405533 1.9362085 -0.98967594 0.5295451
1.589188 -0.5120375 3.1153758 1.200571 -0.9682008 1.0395331
-0.40270805 0.85788846 -1.1856868 -1.1182163 0.27180263 -2.3870842
0.30561337 -3.086804 0.6730606 -0.55788547 -1.8496476 1.1778438
-3.252681 1.1772966 -4.2397146 0.26227665 -1.1796527 -0.11905587
-1.6812707 -0.80028236 0.21924041 -0.6131642 0.50535196 0.02423297
-0.6145355 -1.2522593 0.19663902 1.4207224 0.18940918 -0.17578137
0.7356166 1.4127327 2.4649005 1.1953328 1.2943949 -0.30904412
-2.6319313 3.3482287 ]
Process finished with exit code 0
可见,词向量训练的结果还是不错的。这个可以看作是word2vec的求近义词、相关词,也可以看成利用word2vec聚类。
附:一个在线测试的网站,貌似是一位清华教授做的:http://cikuapi.com/index.php
这里计算词语"大数据"与"人工智能" ,"滴滴"与"共享单车"之间的相似度,会报错:
KeyError: "word '大数据' not in vocabulary" 或 KeyError: "word '共享单车' not in vocabulary"

为什么呢?因为 '大数据'和'共享单车'这两个词不在训练的词向量里面。
为啥不在呢,那么大的维基百科语料库?
1、有可能是我们训练词向量的时候,min_count最小词频默认为5,也就是分词后的语料中词频低于5的词语都不会被训练。这里可以将词频设置小一点,比如:min_count=2。语料越小,设置的词频应越低,但训练时所消耗的时间也就越长,大家可以设置试一下。这也是我上面设置min_count=5,只花费17分钟的时间就训练完了。
2、可能语料库里面没有这个词,这么大的语料可能性很小,况且这是最新的维基百科语料。
3、可能繁体字转化为简体字的时候没有转化过来。
加载模型找出指定词的相似词并制成词云
WordCloud:https://blog.csdn.net/sinat_29957455/article/details/81432846
这里必须添加字体,不然显示不出中文,字体一般在C盘:c:\windows\fonts\simsun.ttc 这个字体可以,你可以在自己的本地看下。另外,这里是绘制的圆形mask,你也可以加载本地图片,根据本地图片的形状生成mask,就不用去绘制了,这类代码可以去网上百度,有好多。
具体实现代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:Administrator
@file:WordCloud_visualization.py
@time:2019/07/31
"""
import logging
from gensim import models
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
font_path = 'D:\Fonts\simkai.ttf'
'''
获取一个圆形的mask
'''
def get_mask():
x, y = np.ogrid[:300, :300]
mask = (x - 150) ** 2 + (y - 150) ** 2 > 130 ** 2
mask = 255 * mask.astype(int)
return mask
'''
绘制词云
'''
def draw_word_cloud(word_cloud):
wc = WordCloud(font_path = font_path,background_color="white", mask=get_mask())
wc.generate_from_frequencies(word_cloud)
# 隐藏x轴和y轴
plt.axis("off")
plt.imshow(wc, interpolation="bilinear")
plt.show()
def test():
logging.basicConfig(format="%(asctime)s:%(levelname)s:%(message)s", level=logging.INFO)
model = models.Word2Vec.load("./model/zhiwiki_news.word2vec")
# 输入一个词找出相似的前100个词,默认是10个
one_corpus = ["人工智能"]
result = model.most_similar(one_corpus[0], topn=100)
# 将返回的结果转换为字典,便于绘制词云
word_cloud = dict()
for sim in result:
# print(sim[0],":",sim[1])
word_cloud[sim[0]] = sim[1]
# 绘制词云
draw_word_cloud(word_cloud)
if __name__ == '__main__':
test()词云效果如下图:

Step-05:使用Sklearn中TSNE进行词向量的可视化
感谢许同学提的小建议,哈哈哈,改下标题
可视化参考链接: https://www.kaggle.com/jeffd23/visualizing-word-vectors-with-t-sne
这里训练的时候设置的最小词频是500,根据结果看,可以词语还是太多了,可视化的过程很漫长,请耐心等待,我是让它跑了一晚上,第二天早上看到好了的,具体多长时间我也不太清楚。。。具体代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:Administrator
@file:Visualization.py
@time:2019/07/30
"""
import pandas as pd
pd.options.mode.chained_assignment = None
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import logging
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
wiki_news = open('./data/reduce_zhiwiki.txt', 'r',encoding='utf-8')
model = Word2Vec(LineSentence(wiki_news), sg=0,size=200, window=10, min_count=500, workers=6)
print('model训练完成')
def tsne_plot(model):
"Creates and TSNE model and plots it"
labels = []
tokens = []
for word in model.wv.vocab:
tokens.append(model[word])
labels.append(word)
tsne_model = TSNE(perplexity=40, n_components=2, init='pca', n_iter=2500, random_state=23)
new_values = tsne_model.fit_transform(tokens)
x = []
y = []
for value in new_values:
x.append(value[0])
y.append(value[1])
plt.figure(figsize=(16, 16))
for i in range(len(x)):
plt.scatter(x[i], y[i])
plt.annotate(labels[i],
fontproperties=font,
xy=(x[i], y[i]),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
tsne_plot(model)可视化结果如下,恐怖如斯:

随便找了一篇文章训练后可视化效果如下,训练时最小词频min_count=1:

但是上面的可视化图没有我想看到的词向量相近的词在一起的效果,所以找到一篇金庸的《笑傲江湖》的txt文档,进行词向量训练并进行可视化。
数据预处理:正则提取中文,jieba分词。这里添加停用词,就是去掉那些没有用的词,不然对可视化有影响。这个和构建中文词云差不多,所以增加了去停用词。这里的停用词是我精心搜集整理的哦!!!
1)数据预处理具体代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import collections
import re
import jieba
#读取数据
def read_data():
"""
对要训练的文本进行处理,最后把文本的内容的所有词放在一个列表中
"""
#读取停用词
stop_words = []
with open('./data/StopWord_new.txt',"r",encoding="UTF-8") as f:
line = f.readline()
while line:
stop_words.append(line[:-1])
line = f.readline()
stop_words = set(stop_words)
print('停用词读取完毕,共{n}个词'.format(n=len(stop_words)))
# 读取文本,预处理,分词,得到词典
raw_word_list = []
rules = u"([\u4e00-\u9fff]+)" #只提取中文
pattern = re.compile(rules)
with open('./data/笑傲江湖.txt',"r", encoding='UTF-8') as f:
lines = f.readlines()
for line in lines:
line = line.replace("\r","").replace("\n","").strip()
if line == "" or line is None:
continue
line = ' '.join(jieba.cut(line))
seg_list = pattern.findall(line)
words_list = []
for word in seg_list:
if word not in stop_words:
words_list.append(word)
with open('./data/分词后的笑傲江湖.txt', 'a', encoding='utf-8') as ff:
if len(words_list) > 0:
line = ' '.join(words_list) + "\n"
ff.write(line) # 词汇用空格分开
ff.flush()
raw_word_list.extend(words_list)
return raw_word_list
words = read_data()
print(len(words))
print(len(set(words)))结果显示去掉停用词还有29万个词语,但去重后只剩下40916个词语:
停用词读取完毕,共2414个词
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.771 seconds.
Prefix dict has been built succesfully.
294214
40916
Process finished with exit code 0分词后的文本:

2)词向量训练及可视化和上面代码一样,这里词频设置为min_count=5(默认词频):
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:Administrator
@file:笑傲江湖visualization.py
@time:2019/07/31
"""
import pandas as pd
pd.options.mode.chained_assignment = None
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import logging
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
wiki_news = open('./data/分词后的笑傲江湖.txt', 'r',encoding='utf-8')
model = Word2Vec(LineSentence(wiki_news), sg=0,size=200, window=10, min_count=5, workers=6)
print('model训练完成')
def tsne_plot(model):
"Creates and TSNE model and plots it"
labels = []
tokens = []
for word in model.wv.vocab:
tokens.append(model[word])
labels.append(word)
tsne_model = TSNE(perplexity=40, n_components=2, init='pca', n_iter=2500, random_state=23)
new_values = tsne_model.fit_transform(tokens)
x = []
y = []
for value in new_values:
x.append(value[0])
y.append(value[1])
plt.figure(figsize=(16, 16))
for i in range(len(x)):
plt.scatter(x[i], y[i])
plt.annotate(labels[i],
fontproperties=font,
xy=(x[i], y[i]),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.show()
tsne_plot(model)可视化效果如下。。。。 还是看不清。。。

min_count=20时,放大可以看清一点。。。可以根据自己需求调解参数,看下效果

min_count=30时,效果如下图:
小结:
整篇下来主要涉及:
(1)对文本的数据预处理,正则提取中文,结巴分词,加载停用词;
(2)通过链接可以学习到word2vec的基本概念和原理;
(3)利用Gensim工具包实现词向量训练、词语间相似度、查找词语的相关词(有一定的聚类意义,可以用来挖掘近义词、同义词)以及加载模型找出指定词的相似词并绘制词云;
(4)最后使用Sklearn中TSNE进行词向量的可视化。
详细代码请参考我的github:https://github.com/WenNicholas/WIKI_Word2vec
如果对您有一丢丢帮助,请您右上角点个赞吧。。。hahaha